

This is an old revision of the document!
Corpus SYN2015
SYN2015 is a representative corpus of contemporary written Czech published in December 2015. SYN2015 is a sequel of the representative corpora of the SYN series (SYN2000, SYN2005, SYN2010), but at the same time, it reflects necessary methodological and technological enhancements outlined below.
| Name | SYN2015 | |
|---|---|---|
| Positions | Number of positions (tokens) | 120 748 715 |
| Number of positions (excl. punctuation) | 100 838 568 | |
| Number of word forms | 1 751 599 | |
| Number of lemmas | 777 011 | |
| Structures | Number of documents <doc> | 3 376 |
| Number of texts <text> | 114 492 | |
| Number of paragraphs <p> | 2 805 065 | |
| Number of sentences <s> | 8 004 732 | |
| Further information | Reference corpus | YES |
| Representative corpus | YES | |
| Publication year | 2015 | |
Changes compared to other SYN series corpora
The concept of written language in SYN2015
SYN2015 is designed as a representation of contemporary printed language of the last five-year period, i.e. 2010–2014. As the borders of synchronicity vary across the registers, the following criteria for inclusion of the individual texts into SYN2015 have been adopted (based on the three top-level categories, cf. below):
- fiction: publication date within the last 25 years and first publication date within the last 75 years;
- non-fiction: first publication date within the last 25 years;
- newspapers and magazines: publication date within the given five-year period.
Representativeness in SYN2015
The approach adopted to representativeness differs from previous corpora of the SYN-series. SYN2015 contains a large spectrum of different types of texts in order to cover vast majority of varieties the corpus aims to represent. This corresponds to Biber's notion of representativeness in terms of texts as products. Unlike the previous corpora in this series, SYN2015 is designed as representative, but not claimed to be balanced.
Text classification
The original text classification scheme of the SYN series has been updated and revised; both original and revised classifications are based on text-external criteria that reflect predominant function of a text. The revision has been made with respect to comparability with the original scheme, with the most significant change made to the sub-classification of non-fiction adopted from the Czech National Library and more detailed classification of newspaper texts.
| Txtype_group | Portion |
|---|---|
| FIC: fiction | 33,33 % |
| NFC: non-fiction | 33,33 % |
| NMG: newspapers and magazines | 33,33 % |
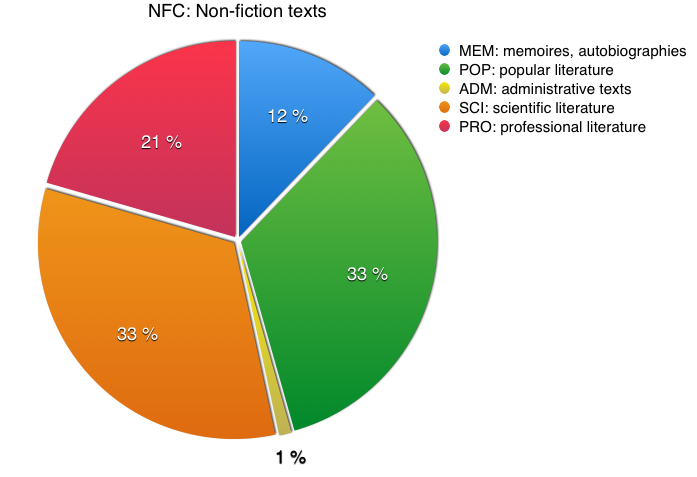

In line with its predecessors, SYN2015 contains a large variety of texts from various publishers within the given classification category. A category is defined by a combination of two variables: text type and genre. Proportions of the particular categories in SYN2015 are set arbitrarily, yet close to the original figures.
Next to the text type and genre, metadata related to the text classification and available for every document also include medium (book, journal, textbook etc.), periodicity (daily, weekly, monthly, less than monthly, non-periodical) and audience (general, children/youth). Standard division of the newspapers into the individual articles is also supplemented by their separate classification into 13 sections (politics, economics, sports, culture, leisure, commentaries etc.) and information about the author that is available for all prominent newspaper titles.
A more detailed description of the text types contained within the macro groups:
| txtype | genre / genre_group | category | proportion |
|---|---|---|---|
| Fiction (FIC) | 33,33 % | ||
| NOV | novels | 26 % | |
| COL | short stories | 5 % | |
| VER | poetry | 1 % | |
| SCR | drama, screenplays | 1 % | |
| X | other | 0,33 % | |
| Non-fiction (NFC) | 33,33 % | ||
| SCI (scientific) PRO (professional) POP (popular) | HUM | humanities | 7 % |
| SSC | social sciences | 7 % | |
| NAT | natural sciences | 7 % | |
| FTS | technical sciences | 7 % | |
| ITD | interdisciplinary | 1 % | |
| MEM | memoirs, autobiographies | 4 % | |
| ADM | administrative texts | 0,33 % | |
| Newspapers and magazines (NMG) | 33,33 % | ||
| NEW | NTW | nationawide newspapers – selected titles (MF, LN, HN, Právo) | 10 % |
| NTW | nationawide newspapers – other | 5 % | |
| REG | regional newspapers | 5 % | |
| LEI | leisure magazines | 13,33 % | |
Concept of synchronicity
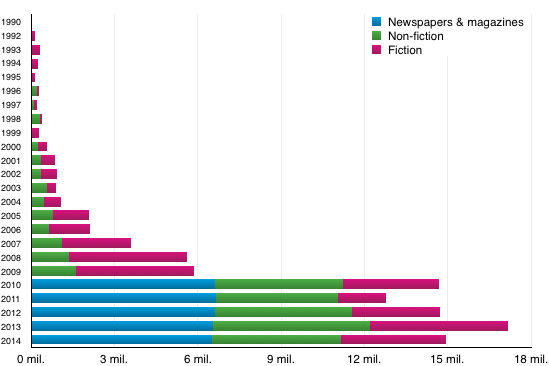
We are working under the assumption that a synchronic text is one that is still being read (or published), which is indicated by the year of publication. The boundaries of synchrony differ for each of the three macro groups:
- for fiction it is 25 + 75, i.e. the time elapsed since the first publication is less than 75 years (approximately three living generations) and the given issue of the text being added to the corpus is no older than 25 years (ensuring reception in the present),
- for non-fiction texts the first issue must be no older than 25 years,
- the boundaries for the synchrony of newspapers and magazines remains unchanged, i.e. the text must have been published in the period which is being mapped by the corpus (in the case of SYN2015 it is the period between 2010 and 2014).
The resulting makeup of the corpus in no. of words over the years is summarized by the following graph.
Poziční anotace a značkování
Oproti předchozím korpusům byla vylepšena lemmatizace a morfologické značkování; obojí je v zásadě shodné se zpracováním korpusu SYN2013PUB (viz popis tagsetu), pro SYN2015 byly nicméně použity novější verze všech nástrojů (vylepšení se týkají jak morfologického slovníku, tak pravidlové disambiguace). Kromě toho se změnil způsob lemmatizace interpunkčních znamének: zatímco v předchozích korpusech byly sjednoceny různé způsoby zápisu uvozovek, apostrofů a byl také setřen rozdíl mezi spojovníkem a pomlčkou, v SYN2015 je již původní podoba těchto znaků v maximální možné míře zachována, a to v atributu word; v atributu lemma je pak uvedena sjednocená podoba, kterou je výhodné použít pro vyhledávání.
Vedle morfologické anotace se v SYN2015 poprvé v korpusech řady SYN objevuje automatická anotace syntaktická. Anotace vychází z koncepce Pražského závislostního korpusu (PDT) a byla provedena stochastickým parserem TurboParser. Vzhledem k její experimentální povaze lze syntaktickou anotaci využívat jako rámcové vodítko k dalšímu jazykovému výzkumu, je však nutné počítat s tím, že není spolehlivá jako anotace morfologická. Chybovost je vyšší u méně častých syntaktických funkcí a konstrukcí, u nejčastějších funkcí v obvyklém kontextu klesá pod 10 %. Anotace je zachycena pomocí několika pozičních atributů (viz shrnutí):
- afun – syntaktická funkce podle analytické roviny PDT
- prep – u jmen řízených předložkou uvádí lemma předložky
- p_lemma, p_tag, ep_lemma, ep_tag – tag a lemma řídícího tokenu
- p_afun, ep_afun – syntaktická funkce řídícího tokenu
Kromě těchto značek má korpus SYN2015 nově několik dalších pozičních atributů:
- proc - informace o typu nástroje, který je zodpovědný za konečnou disambiguaci tvaru
Struktura korpusu a strukturní značky
Struktura předchozích korpusů řady SYN se většinou řídila hierarchií <opus> – <doc> – <s> (tj. ucelený text nebo soubor textů – oddíl nebo kapitola – věta). V korpusu SYN2015 je tato hierarchie změněna a doplněna. Nejvyšší strukturní jednotkou je ve shodě s mezinárodní konvencí dokument <doc>, který se skládá z jednoho nebo několika textů <text> (články v periodiku, kapitoly v knize nebo jiné smysluplné úseky). Texty se dále člení do odstavců <p> a vět <s>. Každá z těchto struktur je charakterizována konkrétními atributy, jejichž přehled uvádíme v následující tabulce. Kromě těchto hierarchických struktur jsou v korpusu zaznamenány také struktury <hi> (zvýraznění a řezy písma) a <lb> (označení hranice verše v poezii).
<doc> | Poznámka | <text> | Poznámka | <p> | Poznámka | <s> | Poznámka |
|---|---|---|---|---|---|---|---|
| title | název dokumentu nebo periodika | section | generovaný typ rubriky (u vybraných periodik) | type | běžný odstavec/nadpis | id | unique identifier |
| subtitle | podtitul | section_orig | původní název rubriky (u vybraných periodik) | id | jednoznačný identifikátor | ||
| author | autor dokumentu | author | autor článku (u vybraných periodik) | ||||
| issue | vydání (u periodik) | id | unique identifier | ||||
| publisher | vydavatel | ||||||
| pubplace | place of publishing | ||||||
| pubyear | year published | ||||||
| first_published | year of 1st publication | ||||||
| translator | překladatel | ||||||
| srclang | zdrojový jazyk | ||||||
| authsex | pohlaví autora | ||||||
| transsex | pohlaví překladatele | ||||||
| txtype_group | skupina textových typů | ||||||
| txtype | textový typ | ||||||
| genre_group | skupina oborů | ||||||
| genre | tematická oblast | ||||||
| medium | médium | ||||||
| periodicity | periodicita | ||||||
| audience | adresát | ||||||
| isbnissn | ISBN/ISSN | ||||||
| biblio | generovaný bibliografický údaj | ||||||
| id | jednoznačný identifikátor |
How to cite SYN2015
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A.: SYN2015: reprezentativní korpus psané češtiny. Ústav Českého národního korpusu FF UK, Praha 2015. Dostupný z WWW: http://www.korpus.cz
Cvrček, V. – Čermáková, A. – Křen, M. (2016): Nová koncepce synchronních korpusů psané češtiny. Slovo a slovesnost, 77 (2), 83–101. ISSN 0037-7031.
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A. (2016): SYN2015: Representative Corpus of Contemporary Written Czech. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), 2522–2528. Portorož: ELRA. ISBN 978-2-9517408-9-1.




