

Korpus SYN2015
Korpus SYN2015 je synchronní reprezentativní a referenční korpus současné psané češtiny, obsahující 100 milionů textových slov, tedy včetně interpunkce (tokenů). Navazuje na předchozí korpusy řady SYN (SYN2000, SYN2005 a SYN2010), vydávané v pětiletých intervalech, a pokrývá spolu s nimi časové období od roku 1989. Každý z korpusů řady SYN zachycuje především jazyk posledních pěti let, které předcházely jeho zveřejnění; SYN2015 je tak zaměřen na období 2010–2014. Žádný z textů v SYN2015 nebyl použit v jiném korpusu této řady (korpusy jsou vzájemně disjunktní). Korpus SYN2015 je lemmatizovaný a morfologicky tagovaný, ve srovnání s ostatními korpusy však přináší celou řadu změn: byl zúžen pojem psanosti, změněn princip reprezentativnosti, upravena a rozšířena klasifikace textů a přibyla nová vrstva syntaktické anotace.
| Název | SYN2015 | |
|---|---|---|
| Pozice | Počet pozic (tokenů) | 120 748 715 |
| Počet pozic bez interpunkce | 100 838 568 | |
| Počet slovních tvarů (wordů) | 1 751 599 | |
| Počet lemmat | 777 011 | |
| Struktury | Počet dokumentů <doc> | 3 376 |
| Počet textů <text> | 114 492 | |
| Počet odstavců <p> | 2 805 065 | |
| Počet vět <s> | 8 004 732 | |
| Další informace | Referenční | ANO |
| Reprezentativní | ANO (viz klasifikace textů) | |
| Rok zveřejnění | 2015 | |
Změny oproti ostatním korpusům řady SYN
Pojetí psanosti v SYN2015
Pojetí psanosti bylo pro korpus SYN2015 zúženo pouze na jazyk tištěný a veřejně publikovaný; korpus tedy neobsahuje např. nápisy ve veřejném prostoru, soukromé dopisy, plakáty nebo další tzv. efemera. Do korpusu SYN2015 nejsou zahrnuty ani texty publikované pouze na internetu.
Na základě předchozích výzkumů reprezentativnosti a v rámci výše uvedeného zúžení reprezentuje SYN2015 především tři velké textové makrotypy (v terminologii korpusových metainformací řady SYN jde o kategorii txtype_group):
- beletrii (zahrnující krásnou literaturu v nejširším pojetí: prózu, poezii a drama);
- oborovou literaturu (zahrnující odborné texty vědecko-naučné i popularizující, učební texty a profesní literaturu);
- publicistiku (zahrnující denní tisk a další periodika a neperiodické publicistické texty).
Reprezentativnost SYN2015
Oproti předchozím korpusům řady SYN, jejichž pojetí reprezentativnosti vycházelo z výsledků demografického průzkumu, z dnešního pohledu však již zastaralého, je složení textů v korpusu SYN2015 arbitrární: tři hlavní textové makrotypy – beletrie (FIC), oborová literatura (NFC) a publicistika (NMG) – jsou zastoupeny stejným dílem. Cílem bylo zahrnout co nejširší spektrum různých typů veřejných psaných (tištěných) komunikátů, které jako celek reprezentují současnou psanou češtinu; neodráží však jazykovou populaci v přesně daných proporcích, tedy reálný poměr výskytu textů ani jejich recepci.
Klasifikace textů
Klasifikace textů v SYN2015 je založena na externích, mimotextových kritériích. Při její aktualizaci jsme se snažili zachovat maximální možnou kontinuitu ve vztahu k předešlým korpusům řady SYN. Klasifikace je stejně jako ta předchozí hierarchická. Nejvyšší úroveň txtype_group určuje tři již zmíněné makrotypy textů: beletrii, oborovou literaturu a publicistiku, z nichž každý je zastoupen stejným dílem; další úroveň členění představuje txtype. Nově přidanou úrovní je genre_group, která se však vztahuje pouze k textům oborové literatury (NFC), nejjemnější úroveň klasifikace textů pak představuje tzv. genre (podrobnosti o složení a klasifikaci viz přehledný souhrn jednotlivých kategorií včetně zkratek).
| Txtype_group | Podíl |
|---|---|
| FIC: beletrie | 33,33 % |
| NFC: oborová literatura | 33,33 % |
| NMG: publicistika | 33,33 % |
Zastoupení v rámci jednotlivých makroskupin shrnují následující grafy.
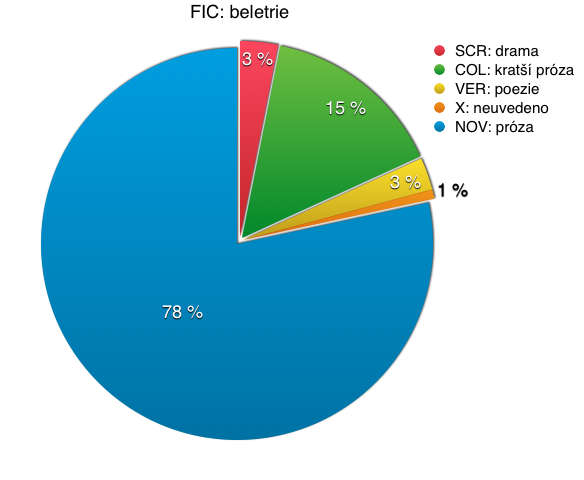
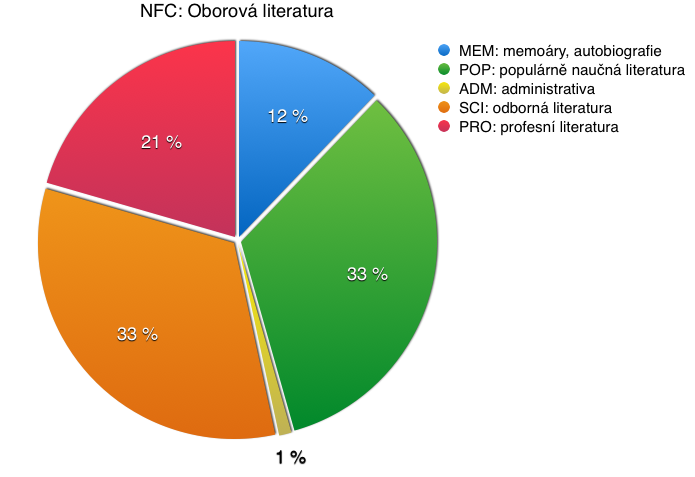
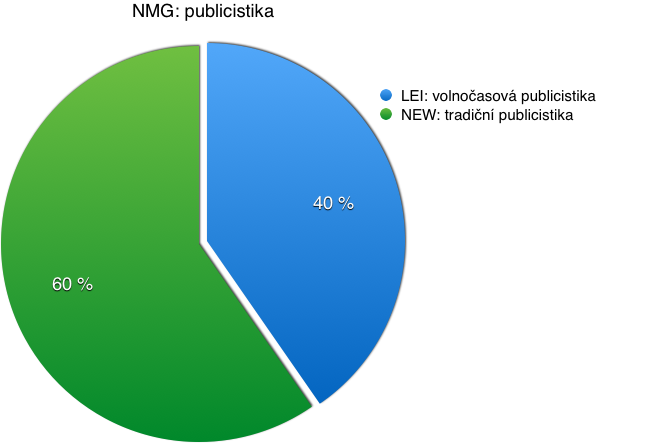
Pojetí synchronie
Vycházíme z předpokladu, že za synchronní lze považovat text, který se stále čte (resp. vydává), což v praxi indikuje rok vydání. Hranice synchronie se však u tří hlavních makroskupin liší:
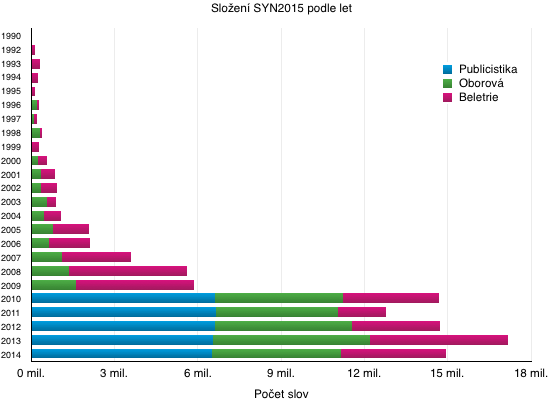
- pro beletrii platí strategie 25 + 75, tj. doba od prvního vydání nepřesahuje 75 let (přibližně tři žijící generace) a konkrétní vydání díla zařazovaného do korpusu není starší 25 let (zajištění současné recepce),
- u odborných textů platí požadavek prvního vydání v posledních 25 letech,
- hranice synchronie publicistických titulů zůstává nezměněna, tj. text musí být vydán v období mapovaném daným korpusem (v případě SYN2015 je to období let 2010 až 2014).
Výsledné složení korpusu podle počtu slov v jednotlivých letech shrnuje sloupcový graf.
Poziční anotace a značkování
Oproti předchozím korpusům byla vylepšena lemmatizace a morfologické značkování; obojí je v zásadě shodné se zpracováním korpusu SYN2013PUB (viz popis tagsetu), pro SYN2015 byly nicméně použity novější verze všech nástrojů (vylepšení se týkají jak morfologického slovníku, tak pravidlové disambiguace). Kromě toho se změnil způsob lemmatizace interpunkčních znamének: zatímco v předchozích korpusech byly sjednoceny různé způsoby zápisu uvozovek, apostrofů a byl také setřen rozdíl mezi spojovníkem a pomlčkou, v SYN2015 je již původní podoba těchto znaků v maximální možné míře zachována, a to v atributu word; v atributu lemma je pak uvedena sjednocená podoba, kterou je výhodné použít pro vyhledávání.
Vedle morfologické anotace se v SYN2015 poprvé v korpusech řady SYN objevuje automatická anotace syntaktická. Anotace vychází z koncepce Pražského závislostního korpusu (PDT) a byla provedena stochastickým parserem TurboParser. Vzhledem k její experimentální povaze lze syntaktickou anotaci využívat jako rámcové vodítko k dalšímu jazykovému výzkumu, je však nutné počítat s tím, že není spolehlivá jako anotace morfologická. Chybovost je vyšší u méně častých syntaktických funkcí a konstrukcí, u nejčastějších funkcí v obvyklém kontextu klesá pod 10 %. Anotace je zachycena pomocí několika pozičních atributů (viz shrnutí):
- afun – syntaktická funkce podle analytické roviny PDT
- prep – u jmen řízených předložkou uvádí lemma předložky
- p_lemma, p_tag, ep_lemma, ep_tag – tag a lemma řídícího tokenu
- p_afun, ep_afun – syntaktická funkce řídícího tokenu
Kromě těchto značek má korpus SYN2015 nově několik dalších pozičních atributů:
- proc - informace o typu nástroje, který je zodpovědný za konečnou disambiguaci tvaru
Struktura korpusu a strukturní značky
Struktura předchozích korpusů řady SYN se většinou řídila hierarchií <opus> – <doc> – <s> (tj. ucelený text nebo soubor textů – oddíl nebo kapitola – věta). V korpusu SYN2015 je tato hierarchie změněna a doplněna. Nejvyšší strukturní jednotkou je ve shodě s mezinárodní konvencí dokument <doc>, který se skládá z jednoho nebo několika textů <text> (články v periodiku, kapitoly v knize nebo jiné smysluplné úseky). Texty se dále člení do odstavců <p> a vět <s>. Každá z těchto struktur je charakterizována konkrétními atributy, jejichž přehled uvádíme v následující tabulce. Kromě těchto hierarchických struktur jsou v korpusu zaznamenány také struktury <hi> (zvýraznění a řezy písma) a <lb> (označení hranice verše v poezii).
<doc> | Poznámka | <text> | Poznámka | <p> | Poznámka | <s> | Poznámka |
|---|---|---|---|---|---|---|---|
| title | název dokumentu nebo periodika | section | generovaný typ rubriky (u vybraných periodik) | type | běžný odstavec/nadpis | id | jednoznačný identifikátor |
| subtitle | podtitul | section_orig | původní název rubriky (u vybraných periodik) | id | jednoznačný identifikátor | ||
| author | autor dokumentu | author | autor článku (u vybraných periodik) | ||||
| issue | vydání (u periodik) | id | jednoznačný identifikátor | ||||
| publisher | vydavatel | ||||||
| pubplace | místo vydání | ||||||
| pubyear | rok vydání | ||||||
| first_published | rok 1. vydání | ||||||
| translator | překladatel | ||||||
| srclang | zdrojový jazyk | ||||||
| authsex | pohlaví autora | ||||||
| transsex | pohlaví překladatele | ||||||
| txtype_group | skupina textových typů | ||||||
| txtype | textový typ | ||||||
| genre_group | skupina oborů | ||||||
| genre | tematická oblast | ||||||
| medium | médium | ||||||
| periodicity | periodicita | ||||||
| audience | adresát | ||||||
| isbnissn | ISBN/ISSN | ||||||
| biblio | generovaný bibliografický údaj | ||||||
| id | jednoznačný identifikátor |
Jak citovat SYN2015
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A.: SYN2015: reprezentativní korpus psané češtiny. Ústav Českého národního korpusu FF UK, Praha 2015. Dostupný z WWW: http://www.korpus.cz
Cvrček, V. – Čermáková, A. – Křen, M. (2016): Nová koncepce synchronních korpusů psané češtiny. Slovo a slovesnost, 77 (2), 83–101. ISSN 0037-7031.
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A. (2016): SYN2015: Representative Corpus of Contemporary Written Czech. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), 2522–2528. Portorož: ELRA. ISBN 978-2-9517408-9-1.




