

Toto je starší verze dokumentu!
Obsah
2. lekce: Položili jsme dotaz. Co vše můžeme zobrazit?
V první lekci tohoto průvodce pro práci s korpusy jsme se naučili položit korpusu jednoduchý dotaz. Nyní se budeme věnovat tomu, jaké informace o datech máme k dispozici, jak si je zobrazit a jak je uložit. Řadu těchto informací se ovšem dozvíme i ze samotného konkordančního řádku. Abychom jim správně rozuměli, nejprve se zaměříme na to, v jaké podobě jsou data v korpusu uložena a co to znamená pro jejich zobrazování. V dalším kroku si ukážeme možnosti, jež poskytuje např. nastavení různého rozsahu zobrazení metainformací. Pro začátek si však musíme již zmíněné pojmy word (slovní tvar) a lemma doplnit ještě o jeden – tag.
Word – lemma – tag
Tato „klíčová korpusová trojice“ je se používá ke kladení různých typů dotazů, které nabízejí jak analýzu jednoho konkrétního tvaru (word), tak celého paradigmatu/lexému (lemma). Navíc je u různých typů dotazů možné upřesnit slovní druh či další morfologické informace obsažené v tzv. značce, morfologickém tagu. Tag sumarizuje gramatickou informaci o hledaném slově v konkrétním kontextu a připisuje se většinou automaticky v průběhu morfologické analýzy. V současné době používaný tagset pro češtinu obsahuje 16 pozic umožňujících specifikaci kategorií typu slovnědruhová příslušnost, pád, číslo či čas a způsob.
| Klíčový pojem | Význam |
|---|---|
| word | konkrétní slovní tvar či podoba interpunkčního znaménka |
| lemma | základní (slovníkový) tvar automaticky přiřazený ke každému tvaru/wordu |
| tag | gramatická informace automaticky přiřazená ke každému tvaru/wordu 1) |
Jak jsou informace o tom, k jakému lemmatu patří konkrétní slovní tvar a jaký tag ho nejlépe popisuje, v korpusu zaneseny? K tomu je třeba absolvovat malý exkurz věnovaný vnitřní struktuře korpusu.
Vnitřní struktura korpusu
Nejprve si objasníme, v jaké struktuře jsou data, jež rozhraní KonText zpřístupňuje, uložena a zpracovávána. Podrobný popis poskytuje sekce Struktura korpusu, zde alespoň stručný příklad toho, jak vypadají ukládané texty, a to včetně hlavičky obsahující metainformace. Metainformace v použitém příkladu se týkají psaného textu z korpusu SYN2020, přičemž doc je struktura odpovídající celému dílu s metainformacemi: titul, podtitul, jméno autora, vydání, nakladatel, místo vydání, rok vydání, rok prvního vydání, jméno překladatele, zdrojový jazyk, pohlaví autora, pohlaví překladatele, textová skupina (txtype_group), textový typ (txtype), žánrová skupina, žánr, médium, periodicita, cílové publikum, ISBN/ISSN, bibliografická informace, id publikace, id dokumentu (viz také přehledy a seznamy značek užívaných k vkládání metainformací do textů).
Vertikála je interní formát korpusů, do něhož jsou všechny texty vstupující do korpusu převedeny. Zjednodušená ukázka vertikály z korpusu SYN2020:
<doc title="Svět podle Clarksona" subtitle="" author="Clarkson, Jeremy" issue="" publisher="Dokořán" pubplace="Praha" pubyear="2016" first_published="2016" translator="Drobek, Aleš" srclang="en: angličtina" authsex="M: muž" transsex="M: muž" txtype_group="FIC: beletrie" txtype="COL: kratší próza" genre_group="X: neuvedeno" genre="X: neuvedeno" medium="B: kniha" periodicity="NP: neperiodická publikace" audience="GEN: obecné publikum" isbnissn="978-80-7363-760-6" biblio="Clarkson, Jeremy (2016): Svět podle Clarksona. Překlad: Drobek, Aleš. Praha: Dokořán." id="clark_svetpodlec"> <text author="" section="" section_orig="" id="clark_svetpodlec:1"> ... <p id="clark_svetpodlec:1:1466"> <s id="clark_svetpodlec:1:1466:1"> V v RR--6---------- Norsku Norsko NNNS6-----A---- by být Vc----------I-- pořad pořad NNIS4-----A---- <hi rend="italic"> Chcete chtít VB-P---2P-AAI-- být být Vf--------A-I-- milionářem milionář NNMS7-----A---- <g/> ? ? Z:------------- </hi> zbankrotoval zbankrotovat VpMS----R-AAP-- <g/> , , Z:------------- protože protože J,------------- odkud odkud Db------------- chcete chtít VB-P---2P-AAI-- brát brát Vf--------A-I-- záludné záludný AAFP4----1A---- otázky otázka NNFP4-----A---- <g/> , , Z:------------- které který P4FP1---------- by být Vc----------I-- chránily chránit VpFP----R-AAI-- nejvyšší vysoký AAFP4----3A---- odměny odměna NNFP4-----A---- <g/> , , Z:------------- když když J,------------- tam tam Db------------- lidé člověk NNMP1-----A---- vědí vědět VB-P---3P-AAI-- úplně úplně Dg-------1A---- všechno všechen PLNS4---------- <g/> ? ? Z:------------- </s> </p> ... </text> ... </doc>
Každý dokument začíná specifickou značkou např. <doc …>, za kterou následují jeho charakteristiky (zachycené strukturními atributy), a končí značkou </doc>. Může být dál vnitřně členěn do částí, jejichž hranice se označují pomocí atributu <text> (část díla mající stejného autora, typicky článek v novinách nebo v časopise). <text> se dále člení do odstavců (<p>) a vět (<s>). Kromě těchto hierarchických struktur se v korpusu objevují i struktury nehierarchické, např. <hi> (označuje řezy písma, v tomto případě kurzívu) a <g/> (označuje místo, kde v původním textu nebyla mezera – tato informace umožňuje zobrazení textu v původní podobě).
Všechny struktury včetně vět musejí mít otevírací i ukončovací značku; po <s id="clark_svetpodlec:1:1466:1">, tedy identifikátoru začátku této konkrétní věty v rámci konkrétního opusu, tudíž následuje: </s> a stejně tak jsou ukončeny pomocí lomítka i všechny ostatní strukturní atributy (více v 7. lekci). Výjimkou je v tomto případě značka <g/>, která je jako nepárová ihned ukončena; nevyznačuje totiž rozsah (od–do), ale umístění.
Samotný text je ve vertikále uspořádán do sloupců. První sloupec představuje původní text (atribut word), další sloupce jsou pak vyhrazeny pro jednotlivé poziční atributy (v tomto případě lemma a tag, následovat ale mohou i další atributy).
Zjednodušeně uspořádání dat v lemmatizovaném a tagovaném korpusu vystihuje tato tabulka s týmiž třemi sloupci, jaké obsahuje předchozí kompletní ukázka vertikály:
| word | lemma | tag |
|---|---|---|
V | v | R.* |
Norsku | Norsko | N.* |
by | být | V.* |
pořad | pořad | N.* |
| … | … | … |
zbankrotoval | zbankrotovat | V.* |
, | , | Z.* |
| … | … | … |
Proč je vnitřní uspořádání tak důležité? Každou informaci, která je v korpusových datech takto explicitně zanesena, můžeme vyhledat. Jak na to, si ukážeme zčásti právě teď a zčásti v lekcích následujících.
V souvislosti s anotací musíme upozornit na důležitý faktor: nástroje na automatickou anotaci (taggery) pracují vždy s určitou chybovostí. V případě českých psaných korpusů dosahuje cca 4 %.
První pohled na konkordanci
Už z prvního zobrazení konkordance lze vyčíst několik základních informací. Kromě samotného růžově zvýrazněného KWICu a modře zvýrazněného názvu textu je k dispozici několik informací o četnosti slova (jevu) v zelené liště nad konkordancí. První z nich je frekvence absolutní, která může sloužit k porovnání počtu výskytů slova v rámci jednoho korpusu. Pod zkratkou i.p.m. (instances per million) se skrývá údaj o frekvenci relativní, díky němuž můžeme srovnávat frekvence slov v různě velkých korpusech. Následuje průměrná redukovaná frekvence (ARF), která představuje informaci o rovnoměrnosti rozložení slova v korpusu.
Vpravo na zelené liště lze postupně listovat mezi jednotlivými stránkami konkordance, případně je možné zadat konkrétní číslo stránky a na tu přímo přejít.
Mezi konkordancí a menu vidíme tzv. drobečkovou navigaci. Oceníme ji především u složitějších, vícefázových dotazů (ty si nicméně ponechme do pozdějších lekcí): slouží jednak k snazší orientaci, jednak nám umožnuje vrátit se do kterékoliv fáze dotazu a podle potřeby jej modifikovat.

Rychlé zobrazení informací o textu a rozšíření kontextu
Vyhledejme si nyní slovesný tvar zbankrotoval v korpusu SYN2020. Výsledkem bude 24 konkordančních řádků a daný tvar – KWIC – bude barevně zvýrazněný.
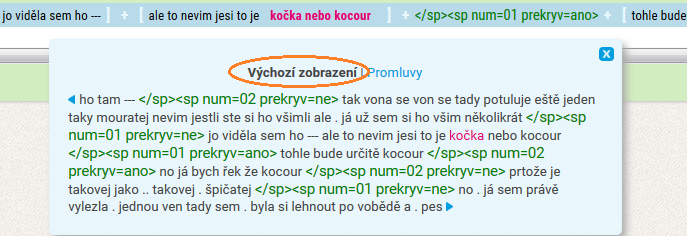
Pokud potřebujeme analyzovat širší kontext hledaného výrazu, lze ho vyvolat kliknutím přímo na vybraný růžově zobrazený KWIC. V dolní části obrazovky se zobrazí okno s širším kontextem, který je možné pomocí šipek ještě zvětšovat (ne však donekonečna). Lze rovněž přepnout z Výchozího zobrazení na Formátovaný text, kde jsou zachovány původní řezy písma a lépe patrné hranice odstavců, případně strof a jednotlivých veršů u básní. Oceníte to především u mluvených promluv.
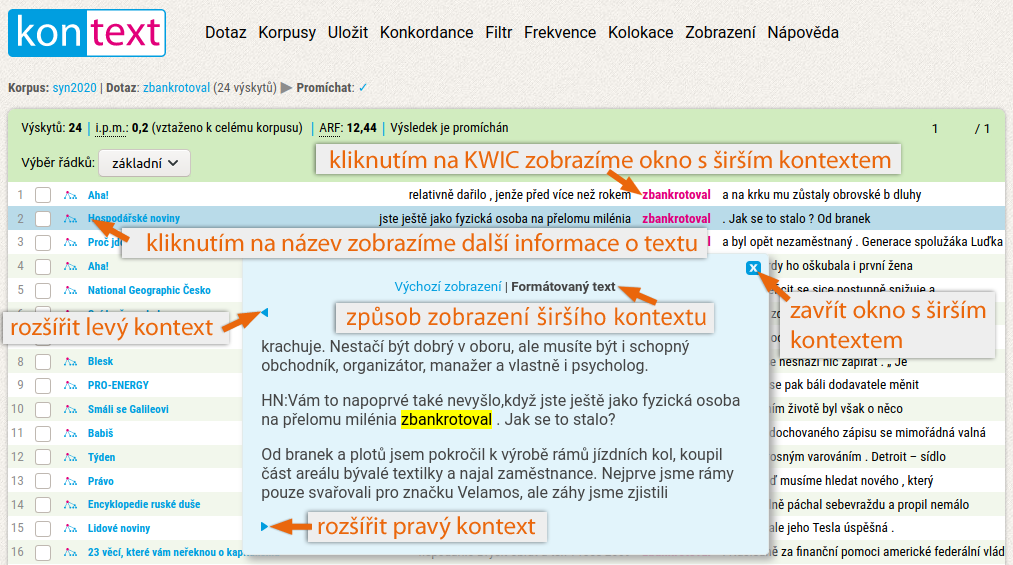
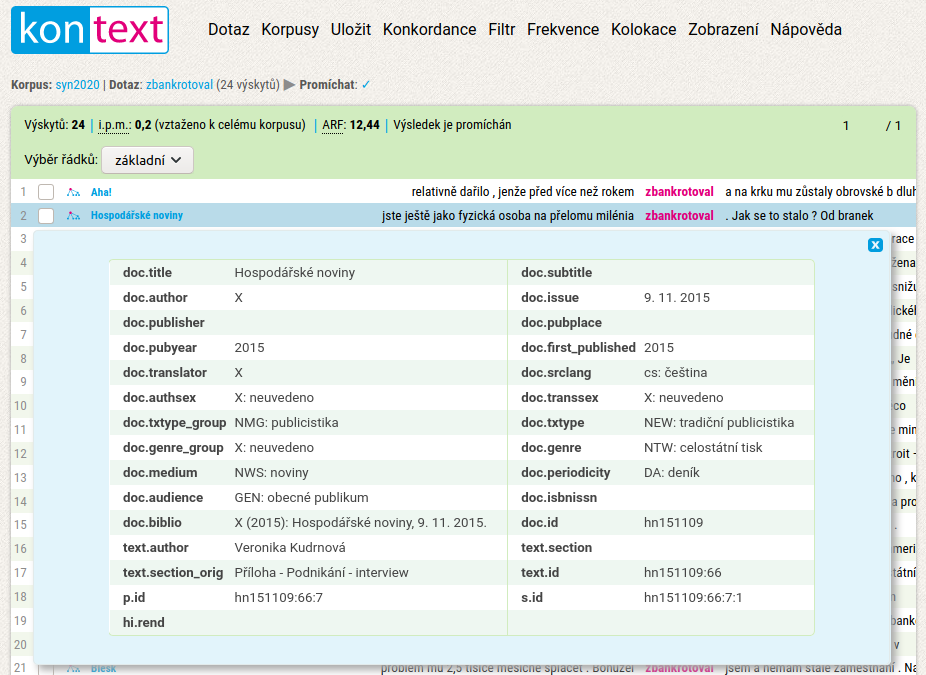
Ve výchozím nastavení vidíme vlevo modře zvýrazněný název dokumentu, z něhož daná kombinace slov pochází. Další informace (např. o autorovi, roku vydání, zdrojovém jazyku nebo u mluvených korpusů o věku mluvčích či geografické oblasti) lze zobrazit kliknutím na tento modrý text. V dolní části obrazovky se objeví barevné pole, v němž jsou všechny údaje o textu, z něhož ukázka pochází, sumarizovány. Toto pole zavřeme kliknutím na křížek v jeho horní části.
Možnosti zobrazení konkordance
V menu si vybereme položku Zobrazení, kde se skrývají všechny možnosti nastavení konkordance. Zde si ukážeme pouze nejčastěji používané volby.
Jak změnit rozsah konkordančního řádku
Chcete vidět širší kontext KWICu nežli defaultně nastavených 10 pozic (vlevo a vpravo)? V horním menu zvolíme Zobrazení → Obecné volby zobrazení a do formuláře zadáme požadovanou šířku kontextu v počtu pozic. Výsledek ovšem nebude nutně přehlednější, nastavení příliš širokého kontextu může být spíše kontraproduktivní. Rozmezí 10–15 pozic většinou plně dostačuje. Dále je dobré vědět, že běžný uživatel má limit pro rozšiřování kontextu maximálně 50 pozic.
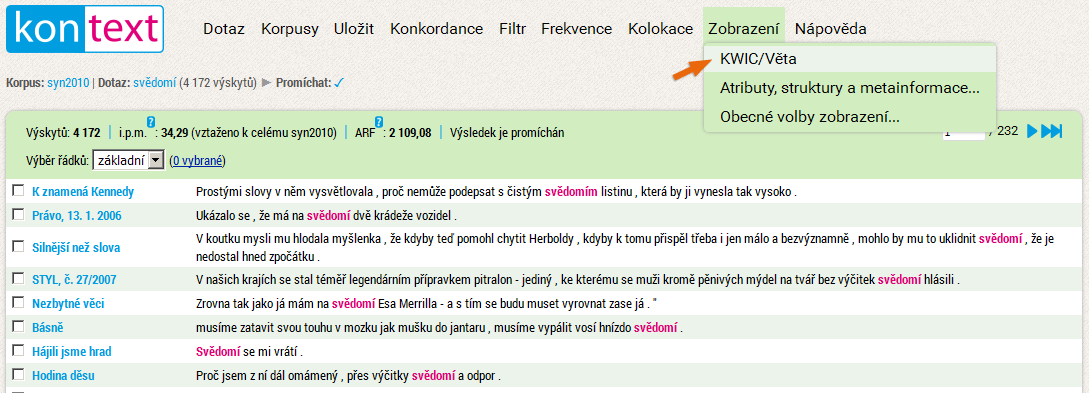
Jak zobrazit celé věty s KWICem
Možná vás ze všeho nejvíc mate zobrazení zarovnané na střed podle KWICu a ignorující hranice vět. Pak si přepněte zobrazení pomocí položky Zobrazení → KWIC/Věta. Je orientace při zobrazení vět snazší? Pokud ano, zvolené nastavení se aplikuje na všechny budoucí dotazy – pokud ne, jednoduše ho znovu přepněte zpět.
Jak zobrazit dostupné metainformace
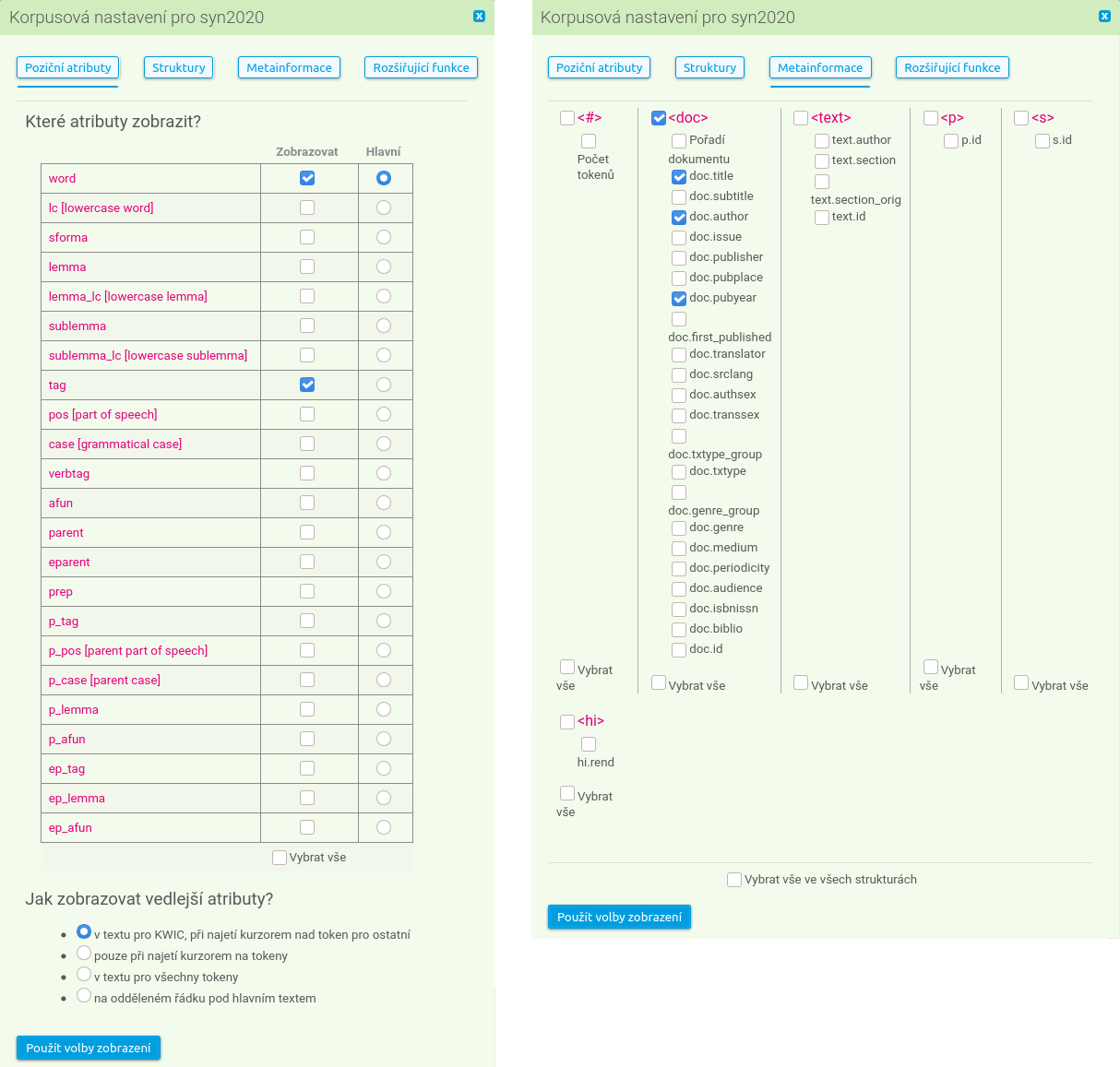
Jelikož se korpusy zpřístupňované rozhraním KonText liší svou povahou i způsobem zpracování, nejsou dostupné informace o původu textů či členění do strukturních jednotek totožné. K zobrazení metainformací se dostanete opět přes volbu Zobrazení → Korpusová nastavení, která umožňuje nejpodrobnější vyladění zobrazovaných dat.
Pro názornost uveďme příklad – u každé konkordance chceme zobrazit název díla, autora a rok vydání, u každého KWICu pak chceme zobrazit i jeho tag. Ve formuláři v menu Zobrazení → Korpusová nastavení stačí zaškrtnout zkratky odkazující k příslušným kategoriím – některé jsou celkem intutivní (pubyear), kvůli jiným se možná budete muset podívat do zvláštního seznamu.
Ve výběru pozičních atributů nezapomeneme zaškrtnout tag (spolu s volbou, která ho zobrazí pouze u klíčového slova, nikoli u všech slov v dané konkordanci).
A takto vypadá zobrazení konkordančních řádků, na něž se aplikovaly výše uvedené volby:

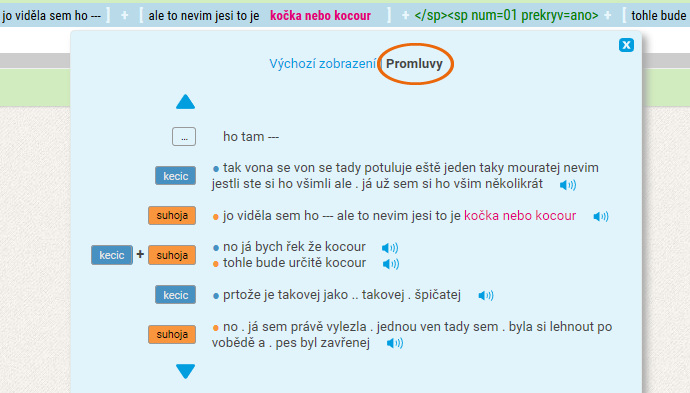
Jak zobrazit dialog v mluvených korpusech
Výchozí zobrazení rozšířeného kontextu, které dostanete při kliknutí na KWIC, je lineární a většinou rychlé orientaci či porozumění příliš nepomáhá. Lepší je zobrazit si dialog tak, aby v každém novém řádku byl jiný mluvčí. Přepnutím Výchozího zobrazení na Promluvy získáte právě takové setřídění. V zobrazení promluv jsou také snáze rozpoznatelné překryvy, tj. simultánní hovor dvou mluvčích. Najdete překryv na obou obrázcích?
Ukládání dat
Všechna data, která už umíme vyhledat, si můžeme také uložit. Možnosti, které export dat z našeho manažeru nabízí, shrnuje příslušný oddíl manuálu. Výhodné je data ukládat do formátu XLSX (Excel), ten nám totiž umožňuje jednoduchou práci s jednotlivými řádky. Volba Uložit → Vlastní poskytuje možnost vlastního nastavení exportu dat, ať už jde o připojení hlavičky, číslování řádků, rozsah ukládaných řádků či jiné volby.
Co všechno lze exportovat
Exportovat můžete vždy, když je aktivní (tj. černě zbarvená) volba Uložit. Ukládat samozřejmě můžete nejen konkordanční řádky, ať už neupravené nebo třeba setříděné, ale také výsledky frekvenční distribuce a kolokační analýzy, o kterých bude řeč v dalších lekcích. Jak vidíte na obrázku níže, volba Uložit je aktivní.
Nač jsou jednotlivé formáty dobré
Při exportu dat si můžete vybrat ze čtyř různých formátů:
Formáty pro tabulkové editory: .xlsx či .csv
Velmi užitečný způsob, jak pracovat s exportovanými daty, jsou tabulkové editory, např. Excel či Calc. Jejich výhodou je možnost uložená data posléze různě třídit či filtrovat a provádět na nich další operace. Nejjednodušší je otevřít exportovaná data přímo v excelovém sešitě (formát .xlsx), s nímž můžete okamžitě pracovat. Formát .csv je textový formát umožňující zachovat sloupcový charakter dat.
Prostý text: .txt
Pokud výsledek nebudete chtít zpracovávat v tabulkovém editoru, uložte si ho v tomto formátu. KWIC zůstane oddělen tabulátory a jednotlivé konkordance budou na samostatných řádcích.
Extensible Markup Language: .xml
Tento formát je určen především pro pokročilé uživatele. Takto uložená data nelze otevřít v tabulkových editorech ani s nimi nelze pracovat jako s čistým textem.
Uložení konkordance
KonText umožňuje uložit dokonce celou konkordanci, a to se všemi informacemi, které jsou aktuálně zobrazeny (např. celý zobrazený levý i pravý kontext, ale i metainformace, jako je jméno autora či díla). Ukládání příliš rozsáhlých konkordancí (např. o tisících řádků) však nemá smysl – s takovým rozsahem je výhodnější pracovat pomocí KonTextu než prostřednictvím Excelu. Často je záhodno konkordanci před uložením nějak dále zpracovat, např. pomocí vytvoření náhodného vzorku nebo třídění řádků. Možnost uložení (pokud nechceme kopírovat řádky po jednom prostřednictvím schránky, tedy za pomoci Ctrl+C – Ctrl+V) vypadá takto:
Úkol na závěr
Zvolte korpus SYN2020 a hledejte:
- lemma
vědomí - slovní tvar
vědomí
Zobrazte si následující údaje:
- zdrojový jazyk (
doc.srclang) - překladatele (
doc.translator) - autora (
doc.author), ale ne název
Výsledky najdete na stránce Řešení úkolů.
Ve třetí lekci budeme pokračovat vyhodnocováním dotazu a tzv. frekvenční distribucí: naučíme se, jak si zobrazit celkový počet výskytů splňujících určitá kritéria (např. patřících k určitému typu textu). Těšte se, začneme se dostávat k jádru práce se zobrazenými výsledky.
Z.



