

Obsah
7. lekce: Subkorpusy a podmínky
Už umíme položit dotaz, zobrazit si výsledek, vyhodnotit ho, zabývali jsme se tvorbou pokročilých dotazů s pomocí regulárních výrazů a CQL a konečně v předchozí lekci jsme si představili, jaké nástroje jsou k dispozici pro hledání kolokací. Spíše než tomu, jak pokládat dotazy, se v této lekci budeme věnovat tomu, v jakých datech vyhledáváme.
Pro dosažení optimálních výsledků totiž nestačí jen umět dotaz vytvořit, je také třeba co nejpřesněji vědět, jaká jsou data, která používáme. Před započetím jakékoli práce s korpusem bychom se proto nejdřív měli seznámit s jeho strukturou a obsahem. Pro mnoho výzkumných otázek je vhodné použít některý z reprezentativních korpusů (nejlépe vždy ten nejnovější, např. SYN2020). V některých případech je ovšem potřeba hledání omezit na určitý typ textů (např. pouze na beletrii, na díla starší, než je určitý rok, na díla původem česká apod.). Pomocí volby Omezit hledání podle metainformací nebo prostřednictvím trvalých subkorpusů je možné zkoumat jazyk určitého typu (autorský, dobový či konkrétního žánru).
Co jsou to metainformace a kde se o nich dozvíme více? Metainformace, tj. informace o názvu, autorovi, roce vydání apod., obsahuje každý text v korpusu. Lze podle nich i vyhledávat – můžeme například najít všechny texty daného autora, texty, které jsou přeložené z konkrétního jazyka nebo které byly vydány v určitém časovém rozmezí. V mluvených korpusech lze vyhledávat podle sociolingvistických údajů týkajících se mluvčích, jako je věk, vzdělání či nářeční oblast (viz specializovaná bonusová lekce).
Kde najdeme seznam příslušných metainformací?
- Seznamy všech informací dostupných k jednotlivým textům v psaných i mluvených korpusech lze nalézt přímo v této wiki, a to buď v popisu konkrétního korpusu, nebo v sekci Seznamy.
- Konkrétní hodnoty metainformací pro všechny konkordanční řádky lze zobrazit pomocí položky menu Zobrazení → Korpusová nastavení.
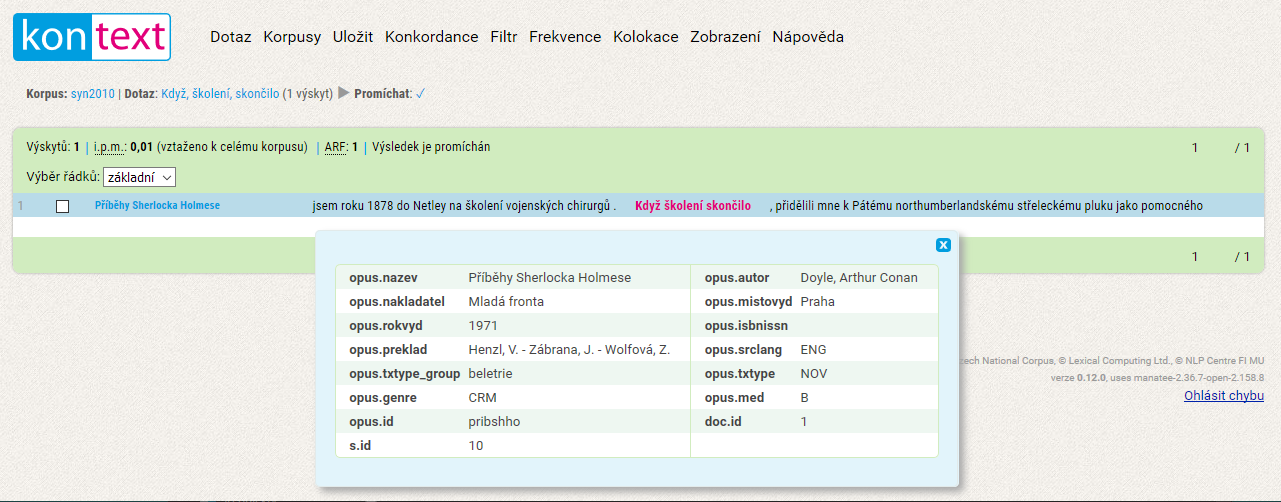
- Další možností je kliknout na metainformace přímo ve zvoleném konkordančním řádku (modře zbarvený údaj vlevo), čímž se zobrazí všechny dostupné informace o textu, z něhož daný doklad pochází.
Jednorázové vyhledávání v určitém typu textů
Pokud chceme pouze jednorázově, tedy pro jediný dotaz, omezit vyhledávání jen na určitou skupinu textů, můžeme tuto skupinu blíže určit pomocí volby Omezit hledání. Podle typu korpusu lze zaškrtáváním vybrat skupinu textů např. podle žánru, média a jazyka originálu (SYN2020: nepřeložené učební texty z oblasti humanitních věd), podle nářeční oblasti a pohlaví mluvčích (ORAL2013: ženy z jihozápadočeské nářeční oblasti) nebo podle období (Diakorp: všechny texty z 16. století).
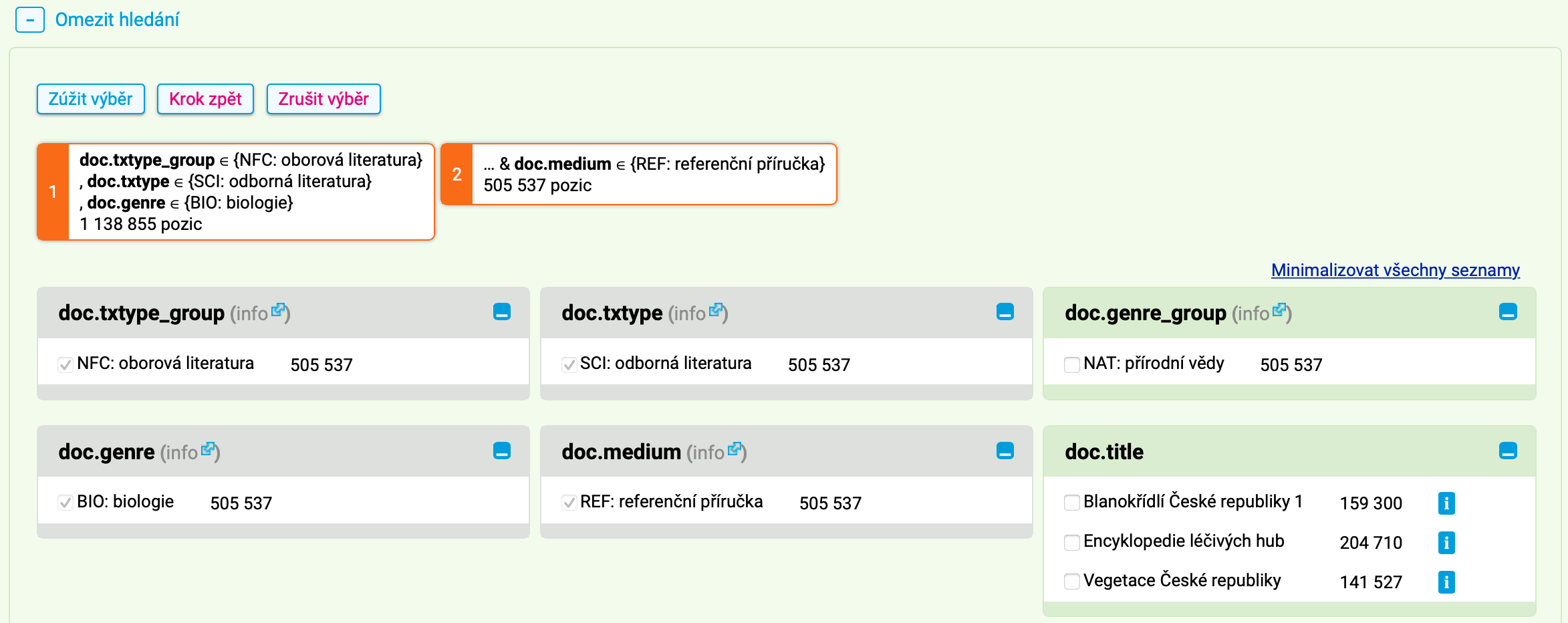
Chceme-li např. v korpusu SYN2020 najít výskyty lemmatu buňka pouze v odborných textech z oboru biologie, budeme dotaz specifikovat následujícím způsobem: v kolonce doc.txtype_group zaškrtneme políčko NFC: oborová, v kolonce doc.txtype políčko SCI: odborná literatura a v kolonce doc.genre políčko BIO: biologie. Pokud chceme zjistit, kterých textů se daný výběr týká, stačí zmáčknout tlačítko Zúžit výběr. Objeví se okénko s aplikovaným filtrem a počtem pozic v daném výběru. Není-li už náš výběr příliš omezený, lze na něj dále aplikovat další filtry, případně jej celý zrušit kliknutím na volbu Zrušit výběr. Tak bychom mohli omezit původní filtr ještě požadavkem na výskyt pouze v příručkách referenčního typu (kolonka doc.medium), kam spadají např. encyklopedie, slovníky apod. Definitivní výběr by pak vypadal takto:
Každý korpus obsahuje vlastní sadu značek a zkratek zachycujících metainformace. Výše uvedený postup tak nelze použít např. pro SYN2010. Seznamy hodnot jednotlivých strukturních atributů včetně rozdílů mezi starší a novější verzí najdete v sekci Seznamy na této wiki.
Pro jednorázovou specifikaci subkorpusu, na nějž chceme dotaz omezit, můžeme využít podmínku within v rámci CQL dotazu:
- Hledáme citoslovce u Karla Čapka (v nereferenčním korpusu SYN, verze 8):
[tag="I.*"] within <doc author="Čapek, Karel" />
Vytvoření trvalého subkorpusu
Vytvoření trvalého subkorpusu se do značné míry podobá volbě Omezit hledání. Na rozdíl od vytvoření dočasného subkorpusu, který slouží k jednorázovému vyhledávání, lze však stálý subkorpus používat opakovaně. Zůstane totiž součástí konkrétního uživatelského účtu a bude k dispozici vždy, když se daný uživatel přihlásí do KonTextu.
Trvalý subkorpus: vytvoření pomocí naklikání
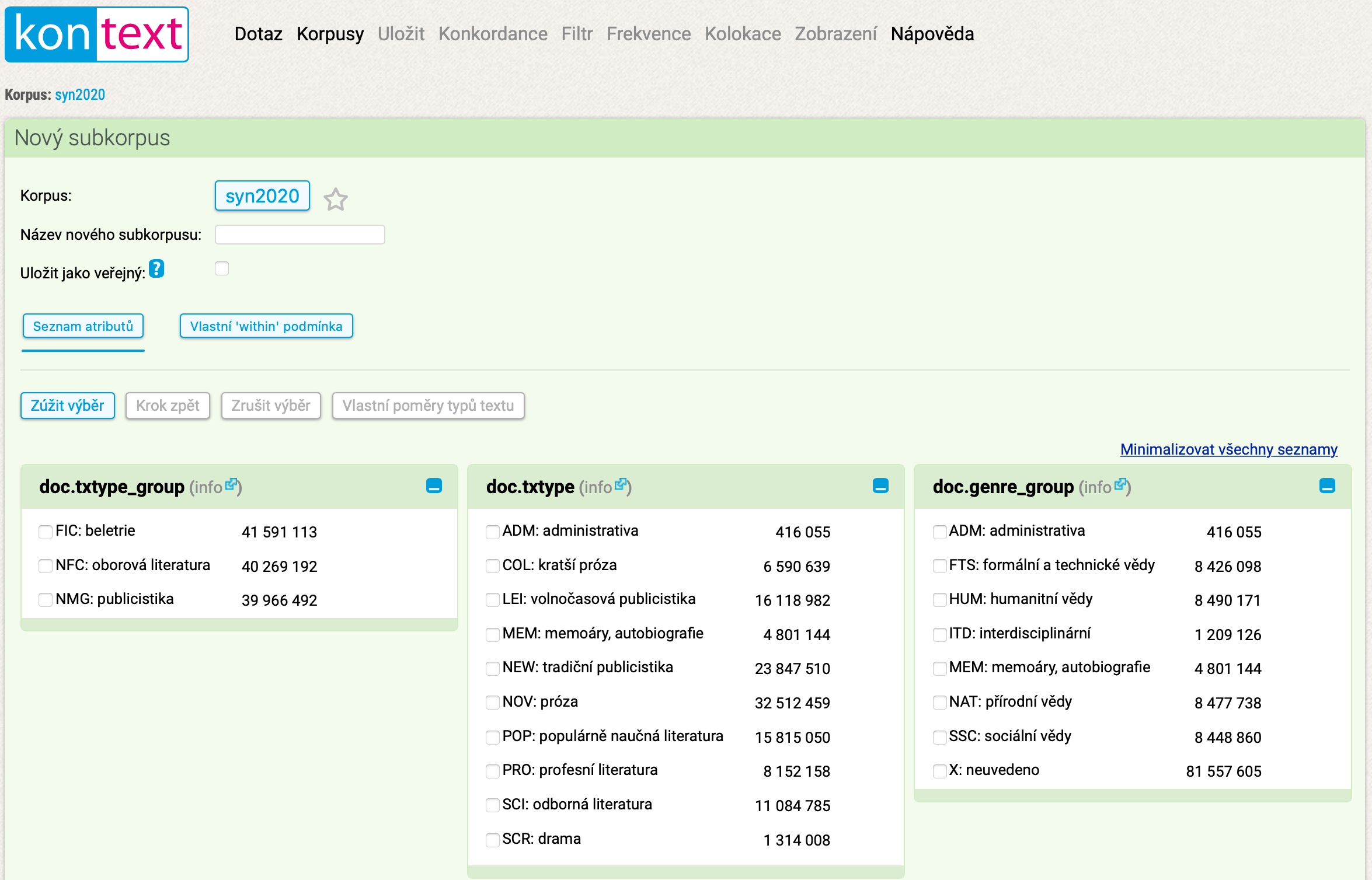
Trvalé subkorpusy se vytvářejí prostřednictvím položky v menu Korpusy → Vytvořit nový subkorpus. Stačí nám k tomu tři jednoduché kroky:
- 1. krok je vždy stejný: Musíme vybrat výchozí korpus, z něhož budeme volit odpovídající podmnožinu dat.
- 2. krok: V jednotlivých kolonkách strukturních typů zaškrtáme své volby příslušných kategorií. Čísla napravo od nich představují velikost textů v dané kategorii v počtu tokenů. Na základě těchto údajů je možné vytvářet subkorpus s určitými proporcemi. Svou volbu můžeme upravovat pomocí tlačítek Zúžit výběr a Zrušit výběr. Je-li výběr dostatečně úzký, lze vybírat také přímo z konkrétních děl (doc.title v SYN2020 a SYN2015, opus.nazev ve starších psaných korpusech).
- 3. krok: Subkorpusu je potřeba přidělit jméno (tj. jednoznačný a jedinečný identifikátor, který v rámci seznamu vašich existujících subkorpusů vytvořených z daného zdrojového korpusu dosud nebyl použit).
Poté stačí kliknout na tlačítko Vytvořit subkorpus a ten se stane součástí vaší nabídky dostupných korpusů. Při zadávání dotazu se ve formuláři vedle tlačítka pro volbu korpusu objeví další prvek, v němž je možné vybírat buď celý korpus, nebo libovolný subkorpus, který z něj byl vytvořen. Subkorpus je navíc možné si přidat mezi oblíbené korpusy, takže bude snadno a rychle dostupný.
Trvalý subkorpus pro pokročilé: vytvoření vlastnoručním stanovením podmínek
Specifický subkorpus můžeme vytvořit i pomocí podmínky within, o níž jsme mluvili v rámci lekce o CQL. Výhodou této složitější cesty je to, že můžeme pracovat s celou škálou informací, které nám korpusový materiál nabízí, nevýhodou je její náročnost (je třeba znát jak struktury v různých korpusech, tak jednotlivé atributy i jejich hodnoty a konkrétní formát).
V menu vyberte položku Korpusy → Vytvořit nový subkorpus. Na zobrazené stránce nejprve zvolte korpus, z něhož chcete texty vybírat (u psaných korpusů nejčastěji SYN2020 či daleko rozsáhlejší SYN), a svůj nový subkorpus nezapomeňte pojmenovat. Poté zvolte možnost Specifikovat subkorpus pomocí volby: Vlastní within podmínka. To umožní vybrat do subkorpusu texty (v psaných korpusech) či např. mluvčí (v mluvených korpusech) odpovídající konkrétním podmínkám. V psaných korpusech se obvykle vybírají texty, tzv. opusy či struktury typu doc. Do prázdného políčka je třeba vyplnit konkrétní podmínku. Následující příklady pocházejí z korpusu SYN2020:
txtype_group="FIC.*"– v subkorpusu budou obsaženy všechny beletristické texty z původního korpusuauthor="Soukupová, Petra"– v subkorpusu budou obsaženy všechny texty, jejichž autorkou je P. Soukupová (u vytváření podmínky obsahující jméno autora je vždy třeba dodržet tento konkrétní formát, případně autorovo jméno zkrátit, ale např. podmínkaauthor="Čapek.*"vztažená na velký korpus SYN by zahrnula texty nejen od obou bratrů Čapkových, ale též od méně známé bratrské dvojice Karla Jana a Michala Čapků)genre="BIO.*"– subkorpus zahrne všechny texty z oboru biologiepubyear="200[5-9]"– subkorpus bude obsahovat všechny texty z let 2005 až 2009
Podmínky lze i kombinovat, stejně jako v rámci jedné pozice, případně přidat další podmínku pomocí tlačítka + v modrém rámečku:
genre_group="NAT.*" & medium="TXB.*"– do subkorpusu budou zahrnuty učební texty z oblasti přírodních vědtxtype="NOV.*" & srclang="en.*" & pubyear="2..." & authsex="F.*"– subkorpus bude obsahovat romány napsané ženami a přeložené z anglického originálu, které vyšly po roce 2000 (včetně)
V mluvených korpusech pak můžeme subkorpusy vytvářet např. podle pohlaví mluvčích či podle nářeční oblasti, odkud pocházejí. V rámci podmínky within vyberte strukturní jednotku sp, tedy mluvčí (speaker) a do prázdného políčka vyplňte konkrétní podmínku či kombinaci podmínek, např.:
pohlavi="Z" & oblast="slezská"– v subkorpusu budou promluvy od žen ze slezské nářeční oblastivzdelanityp="VŠ" & oblast="středočeská"– vznikne subkorpus promluv vysokoškoláků ze středočeské oblasti
Pokud jste si oba subkorpusy vyzkoušeli vytvořit z korpusu ORAL2013, měl by první z nich mít velikost přes 180 tisíc pozic, zatímco ten druhý přes 441 tisíc.
Smazání a přehled dostupných subkorpusů
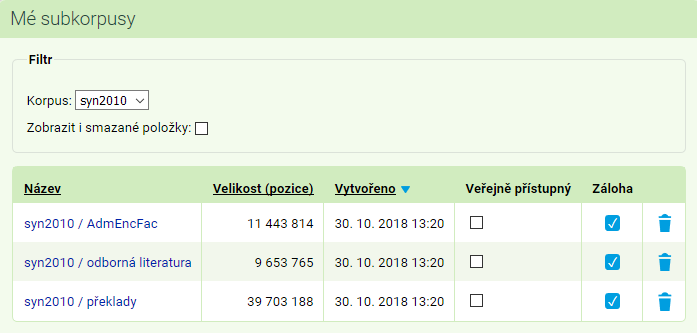
Subkorpusy můžeme spravovat a ty nepotřebné mazat v sekci Mé subkorpusy.
Veřejné subkorpusy
Veřejné subkorpusy slouží ke zpřístupnění subkorpusu dalším uživatelům (např. z výukových či referenčních důvodů). V menu Mé subkorpusy lze vytvořit veřejné subkorpusy (pomocí volby Veřejně přístupný). Zaškrtnutím této volby se pro daný subkorpus vygeneruje jedinečný klíč, pomocí něhož ho budou moct vyvolat a používat i další uživatelé (za předpokladu, že mají práva používat výchozí korpus). Pro zveřejnění je rovněž potřeba vyplnit textovou specifikaci subkorpusu; vřele doporučujeme tuto část vytváření subkorpusu nepodceňovat, protože často je tento popis pro potenciální uživatele vašeho subkorpusu jedinou indicií, podle které můžou odhadnout jeho složení a účel.
Unikátní klíč lze zobrazit, pokud si uživatel vybere vytvořený korpus k práci a nechá si zobrazit informace o něm (odkaz na začátku drobečkové navigace pod logem KonText).
Korpus je pak možné vyvolat v menu Veřejné subkorpusy buď zadáním unikátního klíče, nebo podle příjmení autora subkorpusu (je třeba zadat alespoň 4 počáteční znaky).
Vyzkoušejte si na závěr
Na korpusových datech zjistěte, nakolik se o newyorských Dvojčatech referovalo v roce 2001 a o deset let později (tedy v roce 2011). Zkuste vyhledávat v subkorpusu publicistických textů z daných let (výběr vhodných zdrojových korpusů je v tomto případě součástí úkolu) nejprve pomocí podmínky within, následně si příslušné subkorpusy vytvořte natrvalo. V nich hledejte též doklady přeneseného významu lexému tunel, respektive jeho odvozenin ((vy)tunelovat, tunelář apod.)
Řešení opět najdete na specializované stránce.
Kam dál?
Náš krátký kurz práce s korpusy ČNK zde končí. Pokud byste měli zájem se dozvědět víc, máte možnost ve specializovaných bonusových lekcích:
- specifika hledání v paralelním korpusu
- specifika hledání v mluvených korpusech
- specifika hledání v diachronním korpusu
- specifika hledání v syntakticky anotovaném korpusu




