

Řešení úkolů
Zde najdete řešení úloh ze všech lekcí z Kurzu práce s ČNK.
Lekce 1
V korpusu SYN2020 bylo nalezeno 43 výskytů adjektiva nejvznešenější, z toho třikrát se daný tvar nachází na začátku věty (je s velkým počátečním písmem) a jednou je celý zapsán velkými písmeny. Lemma vznešený se v tomtéž korpusu vyskytuje 1314krát.
Lekce 2
V korpusu SYN2020 byste měli najít tyto údaje:
- 7 919 výskytů lemmatu vědomí – výsledek zde
- 6 698 výskytů tvaru vědomí přesně v této podobě – výsledek zde
- zdrojový jazyk: např. es: španělština, cs: čeština nebo en: angličtina
- překladatel: např. Faltýsková, Alena, Dvořák, Libor nebo Petkevič, Vladimír
- autor: např. Mitosek, Zofia, Komárek, Stanislav či Habermas, Jürgen
Lekce 3
- Frekvenční distribuce všech předložek předcházejících lemmatu vědomí získáme analogickým postupem, jakým jsme hledali příslovce rozvíjející dvojici adjektiv proslulý a věhlasný, tzn. pomocí atributu pos a pozice 1L v menu Frekvence → Vlastní. Zajímat nás bude hned první řádek (prepozice jsou značeny zkratkou R), na nějž aplikujeme pozitivní filtr a provedeme opět frekvenční distribuci výrazů v pozici 1L, tentokrát však s atributem lemma. Výsledek v korpusu SYN2020 by měl vypadat takto:
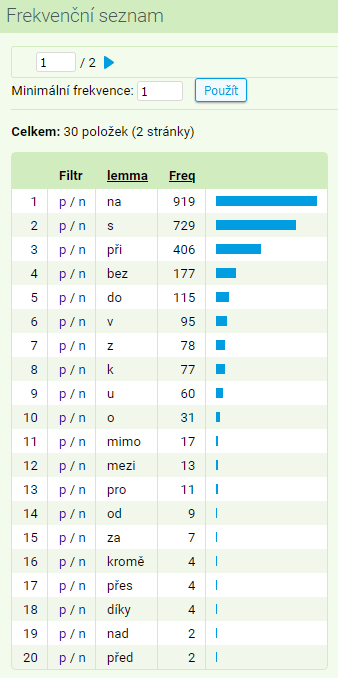
- Též jsme se pokusili odhalit, jak se liší výskyt výplňového slova vole v mluvě mužů a žen. Výsledky (po zaokrouhlení) shrnuje následující tabulka:
| mluvený korpus | absol. frekvence vole | relat. frekvence (ipm) | muži ipm | ženy ipm |
|---|---|---|---|---|
| ORAL2006 | 684 | 521 | 1369 | 147 |
| ORAL2008 | 1343 | 995 | 1732 | 269 |
| ORAL2013 | 3552 | 1081 | 1975 | 152 |
| ORAL v1 | 5977 | 940 | 1865 | 187 |
Můžeme rozhodně vyvodit závěr, že mužům je vole v mluvě mnohem bližší nežli ženám. Ale co s těmi značnými rozdíly v relativní frekvenci při srovnávání jednotlivých korpusů (téměř poloviční výskyt v jednom korpusu ve srovnání s dvěma ostatními)? Více mohou napovědět třeba podrobné informace o korpusu ORAL2006 a ORAL2008, někdy je však velmi těžké na příčinu podobných rozdílů přijít.
Lekce 4
Hledáme v korpusu SYN2015.
Slova obsahující sekvenci -kořen-, po níž následuje a jíž předchází alespoň jeden znak
Výchozí atribut: lemma
Dotaz (s aktivovanými regulárními výrazy): .+kořen.+
Pozn.: V dotazu je třeba použít sekvenci .+, protože v zadání je uvedeno, že předcházet i následovat musí alespoň jeden znak. Z toho důvodu nelze použít sekvenci .*, protože ta odpovídá i nulovému řetězci.
Počet výsledků: 1749
Nejfrekventovanější výsledky (lemmata): zakořeněný (382), zakořenit (323), okořenit (299), pokoření (160), okořeněný (142), pokořený (82)…
Infinitivy odvozené od slovesa téct/téci s prefixem
Výchozí atribut: word
Dotaz (s aktivovanými regulárními výrazy): .+téc[it]
Počet výsledků: 1997
Nejfrekventovanější výsledky: utéct (1622), utéci (230), odtéct (24), protéct (15), přitéct (14), vytéct (12), stéct (10)…
Tvary negativního superlativu (pouze nom. sg.)
Výchozí atribut: word
Dotaz (s aktivovanými regulárními výrazy): nejne.+[šč]í (stejný výsledek v tomto korpusu dostaneme i při zadání nejne.*[šč]í)
Počet výsledků: 673
Nejfrekventovanější výsledky: nejnebezpečnější (220), nejnevhodnější (38), nejnepříjemnější (34), nejnepatrnější (27), nejneuvěřitelnější (24), nejnevinnější (19), nejnemožnější (18)…
Lekce 5
1. Nejprve hledáme aktualizace přísloví těžko na cvičišti, lehko na bojišti. Pohled do korpusu SYN2020 příliš zajímavý není, na dotaz [word="cvičišti"][]{1,10}[word="bojišti"] dostaneme těchto 23 výskytů, z nichž aktualizací není ani jeden. O něco zajímavější data nalezneme v SYN2013PUB, týž dotaz najde 152 případů. Zde už bude vhodné uplatnit negativní filtr, rozsah hledání nastavíme na od -2 do -2, zrušíme volbu včetně KWIC a typ dotazu nastavíme na Slovní tvar, načež vepíšeme nejběžnější formu na dané pozici (2L): těžko|těžce. Výsledkem by měla být tato konkordance, z níž je patrné, že toto přísloví mělo stabilnější formu a bylo méně náchylné k modifikacím než to o vlku a koze. Doložena je nicméně i varianta obrácená (zde stačilo jen v dotazu prohodit oba slovní tvary).
2. Dále nás zajímaly kletby odvozené od slovního spojení Herr Gott a dostupné prostřednictvím korpusu ORAL2013. Nejprve zkusíme dosáhnout co nejvyšší hodnoty recall pomocí jednoduchého dotazu (s využitím regulárních výrazů) .*her.*, ovšem výrazy typu nádhera ukazují, že umístění základu her uprostřed hledaného řetězce k ideálnímu výsledku nepovede. Potřebujeme také eliminovat frekventovaný hermelín a herce s herečkami -– možný dotaz vypadá takto: [word="her[^cme][^cč].*"]. Výsledných 65 výskytů se jeví lépe, ovšem stále obsahuje hodně heren a herních odvozenin. Jak je vyřadit, když hlásku n musíme ponechat kvůli hernajs? Vyloučíme alespoň frekventované nejkratší tvary tím, že nás budou zajímat pouze výrazy o šesti a více znacích – kvantifikátor * nahradíme kvatifikátorem + a zadáme dotaz v této podobě: [word="her[^cme][^cč].+"]. Zbývajících 41 případů už snadno vyfiltrujeme manuálně pomocí okének na začátku příslušných konkordančních řádků, nepotřebujeme-li ale výsledná data ukládat či s nimi dále pracovat, postačí pohled na frekvenční distribuci tvarů (Frekvence → Slovní druhy). Zajímavé je, že mezi nimi figuruje pouze hergot (27krát) a jedno hernajs. O něco pestřejší je situace v ORAL2006.
Lekce 6
1. Začněme pohledem do aktuálního synchronního korpusu psané češtiny SYN2020. Hledáme v něm lemma tratoliště, které se tu vyskytuje 57krát, odfiltrujeme však všechna užití tratoliště krve. V menu zvolíme Filtr → Negativní, rozsah hledání upravíme na od 1 do 1 (jde nám o bezprostřední pravostranný kolokát), jako typ dotazu zvolíme Lemma a do řádku vepíšeme dotaz krev. Zredukovaná konkordance odhalí ještě jeden případ (na posledním řádku), kdy je substantivum krev rozvito adjektivem teplé, bude tedy lepší rozšířit rozsah hledání na od 1 do 2.
Po odfiltrování by nám mělo zbýt těchto 20 výskytů. Patrně nás nepřekvapí, že až na pár výjimek pocházejí všechny z beletrie: vedle konkrét tratoliště peří, sazí, tělíček, zrcadel, písku a expresivnějšího tratoliště krvavých zvratků jsou zastoupena i abstrakta: tratoliště minut, noci, agresivních slov a vět; poměrně často stojí výraz samostatně, případně je rozvit zleva adjektivem: rudé, krvavé, divukrásné.
V SYN2015 by nám po odfiltrování mělo zbýt těchto 19 výskytů; s výjimkou jediného případu jsou všechny rovněž z beletrie. Vedle metafor krotčejších (tratoliště voleje, rozbředlého sněhu, moče, vzpomínek, minut, vlastního světla…) najdeme sem tam nějakou peprnější, např. Hrabalovo tratoliště básnických chcanek.
Maličko jiná je situace v SYN2010: lemma tratoliště se tu objevuje 53krát, nejtypičtější je pro beletrii (32krát), hojně je využívá ale i publicistika (17krát). Ve valné většině případů se objevuje ve spojení v tratolišti krve – v této podobě celkem 35krát. Po aplikaci stejného negativního filtru nám z původních 53 výskytů zbude těchto 8 případů.
V korpusu ORAL v1 se toto slovo – s jedinou, o to však půvabnější výjimkou, za niž by se nemusel stydět ani Hrabal ( …eště si ho vodšoupne jako dál a žere a tam prostě pod nim tratoliště drobků, a já na něj koukám a řikám Láďo proč si myslíš že sem ti tam dala ten talíř?) – nevyskytuje (v korpusu Ortofon pak nenajdeme žádný výskyt). Ovšem ruku na srdce, kdy naposledy jste o tratolišti hovořili vy sami?
2. Porovnáváme kolokační profily adverbií teď a nyní a zamyšlíme se nad mírou jejich synonymnosti. Prvním rozdílem je jejich odlišná frekvence v korpusu SYN2015: 85 940 výskytů teď oproti 34 570 výskytům nyní – první slovo je tedy téměř dvaapůlkrát častější než druhé. Ještě výmluvněji by tento rozdíl byl znát na mluvených korpusech, např. v ORAL2013 je to 8066 případů proti 4 (sic! a to jsme nezapočetli všechny možné varianty typu teďkon(c), teďka apod., které si lze dohledat zde). Mimochodem, obdobné výsledky získáte i pomocí nástroje SyD.
Závěrů, které lze z kolokační analýzy odvodit, je celá řada. Vybereme si proto jen ty nejviditelnější. Na první pohled upoutá fakt, že v první desítce kolokátů podle atributu lc najdeme jen dva společné: teprve a už. Synonymní již je vyhrazeno skoro výlučně lemmatu nyní, což může být důsledek toho, že jak nyní, tak již mají příznak knižnosti.
| Pořadí podle logDice | Kolokáty nyní | Kolokáty teď |
|---|---|---|
| 1. | již | už |
| 2. | už | právě |
| 3. | teprve | ale |
| 4. | čeká | tady |
| 5. | však | když |
| 6. | žije | teprve |
| 7. | pracuje | zrovna |
| 8. | hrozí | ? |
| 9. | máme | mám |
| 10. | je | co |
Povšimněte si rovněž, že mezi nejčastějšími kolokáty lexému teď převažují slova gramatická, kdežto u jeho protějšku je daleko více slov plnovýznamových (autosémantik). Viditelná je zejména preference sloves pojit se s nyní (v první desítce jich objevíme hned 6), zatímco teď má ve svém okolí spíš modifikátory (adverbia a částice).
Přesnou povahu kolokací zjistíme kliknutím na modře zvýrazněný pozitivní filtr (p). Tímto způsobem např. ověříme, že slovo už se objevuje jak na levé, tak na pravé straně obou adverbií, kdežto jiná slova téměř výhradně na jedné straně (teprve teď/nyní). Lexém tady se kombinuje většinou s teď, a to ve spojení tady a teď (331krát), ale i teď a tady (120) – zato v úzkém spojení s nyní se vyskytuje jen ojediněle (po 1 případu tady a nyní a nyní a tady).
Lekce 7
Publicistické texty z roku 2001 pokrývá korpus SYN2005, zvolíme si proto ten a zadáme v něm tento CQL dotaz: [lemma="(?i)dvojče" & word="D.*"] within <opus txtype="PUB" & rokvyd="2001" />. Většina z 31 případů se týká právě newyorských mrakodrapů, manuální filtrací nežádoucích výskytů (pomocí volby Výběr řádků → Odstranit z výsledku vybrané řádky) by vám mělo zůstat těchto 22 výskytů. Trvalý subkorpus vytvoříte obdobně zformulovaným dotazem, měl by mít přes 7,8 milionů pozic. Pro kontrolu v něm zkuste zadat první část výše uvedeného dotazu, tedy [lemma="(?i)dvojče" & word="D.*"], opět by vám mělo vyjít 31 výsledků.
Publicistiku z roku 2011 najdeme v korpusu SYN2015. První část dotazu zůstane stejná (tzn. hledáme lemma dvojče, které se v textu vyskytuje s velkým písmenem), oproti starším korpusům se však změnilo označení metainformací, je tedy zapotřebí zapsat dotaz [lemma="(?i)dvojče" & word="D.*"] within <doc txtype_group="NMG.*" & pubyear="2011" />. Výsledků je na první pohled výrazně méně, celkem 14, z nichž je navíc zapotřebí odstranit 5 nerelevantních případů, zůstane tak pouze těchto 9 výskytů. Trvalý subkorpus publicistických textů z r. 2011 by měl obsahovat přes 8 milionů wordů.
Aktualizace lexému tunel hledáme pomocí dotazu [lemma=".*tunel.*"] within <opus txtype="PUB" & rokvyd="2001" />, případně v již vytvořeném subkorpusu jednoduchým dotazem (s aktivovanými regulárními výrazy a výchozím atributem lemma) .*tunel.*. V obou případech dostaneme 339 výskytů. Zatímco samotné základové slovo tunel si ve většině případů ponechává svůj původní význam, jeho odvozeniny už mají většinou význam přenesený (až na výjimky typu podtunelování – odborný termín, Eurotunel – jméno firmy apod.).
V subkorpusu publicistiky z r. 2011 najdeme 292 výskytů, frekvenční distribuci lemmat můžeme vzájemně porovnat a shrnout např. do následující tabulky (červeně zvýrazněny jsou případy, jež nás zajímají):
| Lemma | 2001pub | 2011pub |
|---|---|---|
| tunel | 233 | 245 |
| tunelář | 29 | 3 |
| tunelování | 25 | 15 |
| vytunelovaný | 10 | 6 |
| vytunelování | 9 | 5 |
| vytunelovat | 9 | 1 |
| tunelovat | 8 | 4 |
| tunelový | 8 | 10 |
| tunelovaný | 1 | 0 |
| tunelovitý | 1 | 0 |
| tuneláž | 0 | 1 |
| nano-tunel | 0 | 1 |
| Eurotunel | 0 | 1 |
Vidíme, že s jedinou výjimkou (tunelář) jsou počty dokladů přibližně stejné, což signalizuje dostatečnou etablovanost daného významu v tuzemské publicistice za posledních 15 let. Zajímavé doklady však najdeme též v jiných typech textů, byť tam převažuje původní význam slova. Vyhledávání stejného slovního základu v celém korpusu SYN2005, resp. SYN2015 odhalí např. tyto další deriváty:
Veřejnost, která volá po tvrdší odplatě za činy zlosynů, tunelujících a plenících naši zem. (SYN2005)
[…] moskevská prokuratura ho má za obyčejného velkotuneláře a neúspěšně žádala jeho vydání. (SYN2005)
Václav Havel v Rudolfinu s vážnou tváří pronesl, že „ekonomická základna je protunelovaná, protože se nevyvíjela v řádu Božích přikázání“. (SYN2005)
A do toho strach, že jsou podtunelovaný další banky a že je jen otázka času, kdy se zhroutěj. (SYN2015)
Úřady znovu vyšetřují jeho podíl na vytunelovávání CS Fondů a okolnostech, za kterých získal MUS. (SYN2015)
[…] po letech vrátila bodrý úsměv řadě supertunelářů, šéfů H-systému a velkozlodějů všeho druhu. (SYN2015)




