

Obsah
1. lekce: Začínáme
V úvodní lekci se naučíme zadávat do korpusu dotazy a vysvětlíme si, v čem se liší jejich různé typy. Na závěr si ještě ukážeme, jak korpusy citovat.
Rozhraní KonText spustíme odkazem na horní liště portálu www.korpus.cz nebo přímo, zadáním adresy https://www.korpus.cz/kontext. K plnohodnotné práci s rozhraním je nezbytné se zaregistrovat a přihlásit se k svému účtu. První dotaz napíšeme do prázdného dotazovacího řádku.
Výchozí nastavení
Hledání je ve formuláři pro zadávání nového dotazu automaticky přednastaveno na nejnovější referenční vyvážený korpus, tj. SYN2020 (my ale budeme často pracovat i se staršími korpusy) a jako výchozí (defaultní) je nastaven jednoduchý typ dotazu. Korpus, s kterým pracujete, je vždy uveden v levém horním rohu pod logem rozhraní, kde se nachází tzv. drobečková navigace, zaznamenávající průběh manipulace s dotazem; pokud kliknete na název korpusu, dostanete se k podrobnějším informacím o něm včetně toho, jak zvolený korpus citovat.
Do dotazovacího řádku v rozhraní KonText můžete napsat jakékoli slovo či kombinaci slov a sledovat, kolikrát se v daném korpusu vyskytuje. (Je dobré mít na paměti, že pro korpusový manažer je slovo pouhým řetězcem alfabetických znaků a že umí vyhledávat i znaky jiné povahy, např. číslice či regulární výrazy.)
Zkuste si v korpusu SYN2020 najít třeba
- své jméno, případně příjmení
- otazník – ? (tj. tázací věty) či vykřičník – ! (tedy mj. věty zvolací)
- nějakou kuriozitu
- třeba přímo slovo kuriozita
- regionalismus cmunda
- hovorové eklovat
- třeba i s reflexivem eklovat se
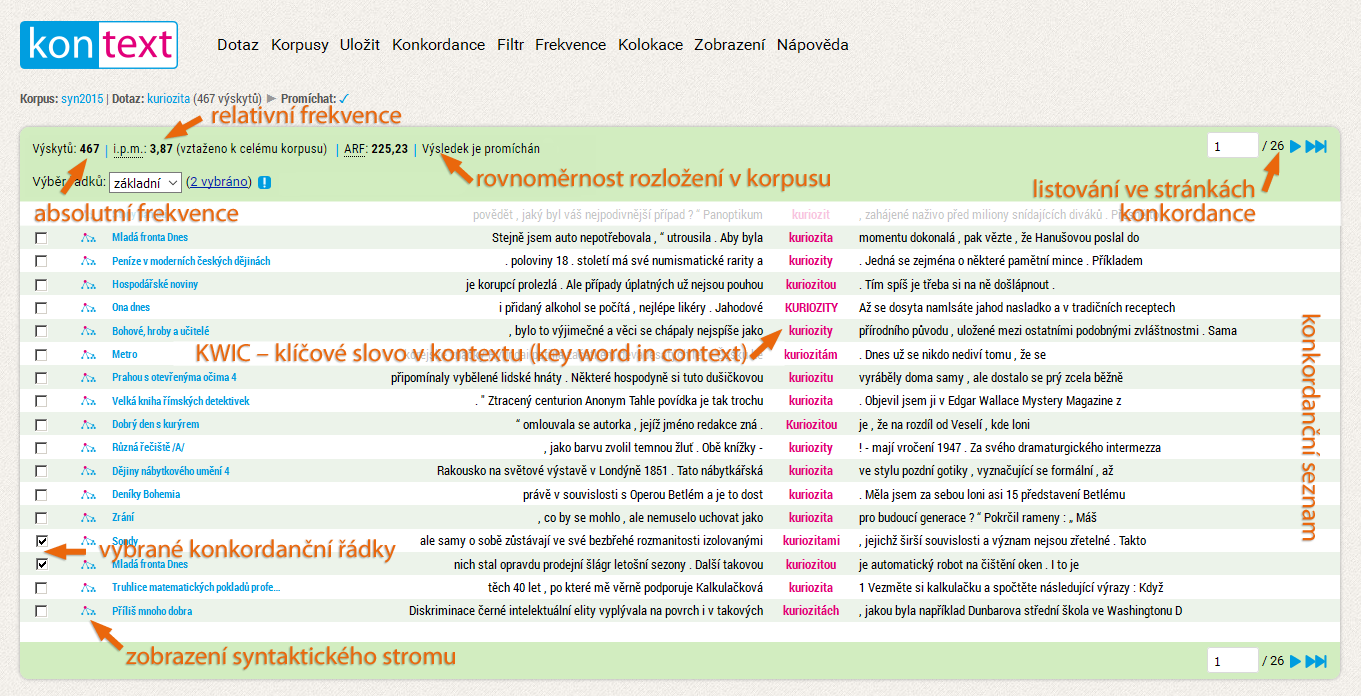
Funguje vám vyhledávání? Ověřte si výsledky v korpusu SYN2020:
| Dotaz | Počet výskytů | Relativní frekvence (i.p.m.) |
|---|---|---|
kuriozita | 456 | 3,74 |
? | 493 417 | 4050,15 |
! | 179 982 | 1477,36 |
cmunda | 9 | 0,07 |
eklovat | 6 | 0,05 |
eklovat se | 1 | 0,01 |
Můžeme si všimnout, že v korpusu SYN2020, který obsahuje zhruba sto milionů pozic, má jeden výskyt určitého výrazu (např. kombinace eklovat se) relativní frekvenci 0,01 výskytů na milion. Proč to stojí za povšimnutí? Relativní frekvence je velmi důležitá při srovnávání výsledků z různě velkých korpusů (10 výskytů ve stomilionovém korpusu neznamená stejnou četnost jako 10 výskytů v korpusu miliardovém).
A ještě jedna věc: vyhledanému výrazu či kombinaci výrazů – v našem rozhraní růžově zvýrazněnému – se říká KWIC; tato zkratka pochází z anglického key word in context (klíčové slovo v kontextu). Celému řádku se říká konkordanční řádek, ten je součástí konkordance (seznamu všech konkordančních řádků, tedy všech výskytů hledaného výrazu spolu s jejich kontexty).
Jak přejít na nový dotaz
Pokud chceme do KonTextu zadat další dotaz, přejdeme na něj pomocí menu Dotaz → Zadat nový dotaz.
TIP: Nejjednodušším způsobem, jak rychle zadat nový dotaz, je kliknout přímo na ikonu  v levém horním rohu.
v levém horním rohu.
Typy dotazů
V rozhraní KonText rozlišujeme mezi dvěma základními typy dotazů:
Výchozím nastavením je jednoduchý dotaz, v němž je dále implicitně nastaveno nerozlišování velikosti písmen (přepínač Shoda velikosti písmen je vypnutý), není povoleno použití regulárních výrazů (přepínač Povolit regulární výrazy je vypnutý) a vyhledávání je nastaveno podle výchozího atributu lemma|word (v SYN2020 lemma|sublemma|word), čímž se vyhledá nejen uvedený tvar (podle atributu word), ale i další tvary slova (podle atributů lemma nebo sublemma), pokud je zadaný tvar zároveň lemmatem nebo sublemmatem (poznámka: oproti předchozím verzím KonTextu nejde o změnu, jen o zobecnění chování původního základního dotazu). Do vstupního řádku je možné kromě jednotlivých slov zadávat i celé fráze. Vyhledávání lze na jednotlivých pozicích upřesnit jednak pomocí našeptávače, jednak změnou výchozího atributu (atribut je pak platný pro všechny pozice) a/nebo přepnutím shody velikosti písmen. Složitější dotazy je možné pokládat i v rámci jednoduchého dotazu, pokud uživatel využije volby Povolit regulární výrazy.
Pokročilý dotaz se aktivuje spínačem nad vstupním řádkem a plně odpovídá dotazu typu CQL předchozích verzí KonTextu. Při zadávání dotazovacího jazyka CQL KonText automaticky kontroluje a zvýrazňuje syntax dotazu. V případě, že dotaz není validní, KonText na to uživatele upozorní a umožní mu dotaz před vyhodnocením opravit. Vzhledem k širokým možnostem CQL dotazování však není kontrola správnosti dotazu vždy přesná, výjimečně se tak může stát, že se varování objeví i v případě validního dotazu.
Je-li zadán dotaz, je možné spustit vyhledávání buď kliknutím na tlačítko Hledat, nebo stisknutím klávesy Enter (kurzor musí být umístěn ve vstupním řádku).
Jak citovat korpus
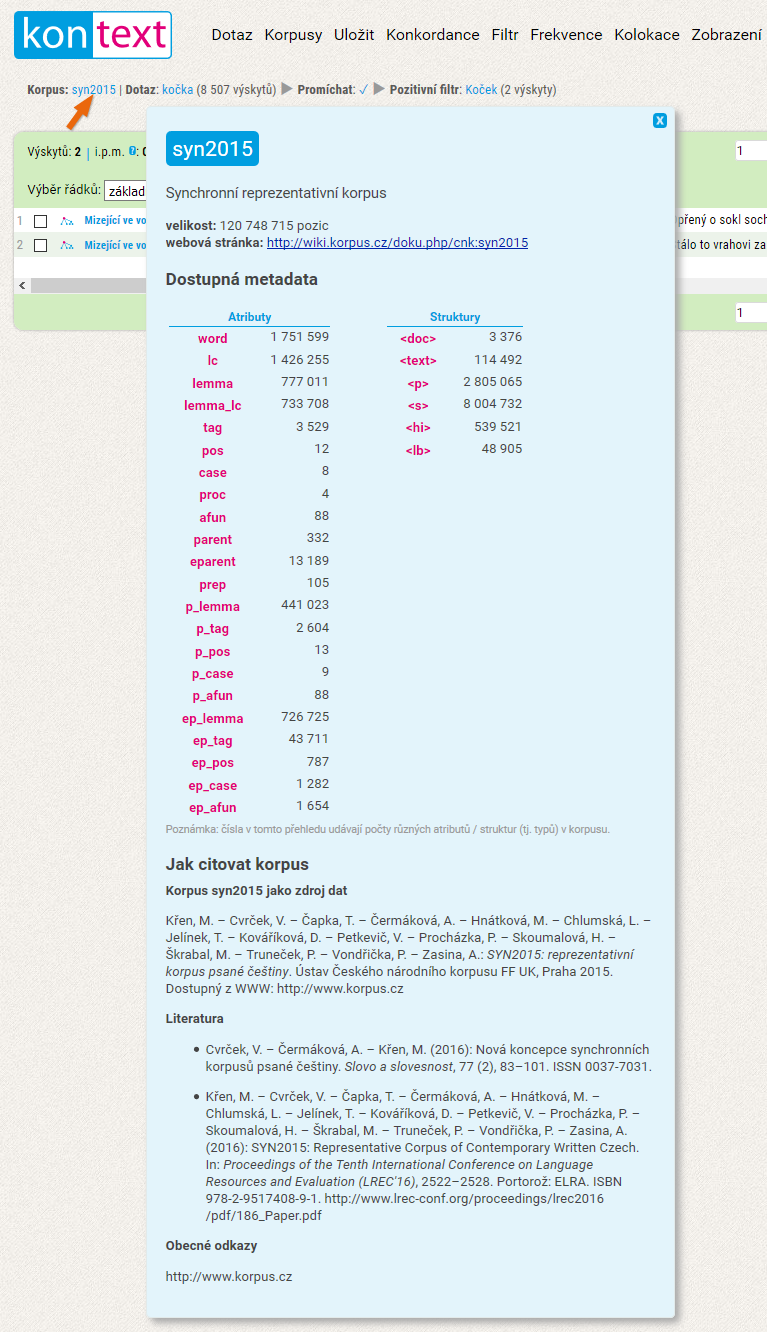
Pokud ve svém lingvistickém (či jiném) výzkumu používáte některý z korpusů ČNK, je třeba ho citovat v seznamu literatury. Pádných důvodů k tomu je hned několik:
- Každý výzkum by měl být replikovatelný, tedy ověřitelný dalšími badateli. V případě korpusů referenčních, jako je např. SYN2020 nebo ORAL2013, lze stejným dotazem vždy dojít ke stejnému výsledku, tedy i ověřit závěry vyvozené z jakéhokoli předchozího výzkumu. U korpusů verzovaných (např. SYN, InterCorp, DIAKORP, ONLINE), které s každou novou verzí rostou, je třeba dodat také informaci o verzi, příp. o datu zveřejnění.
- Bez údaje o tom, v kterém z korpusů ČNK byl daný jev vyhledán, nemůže být jeho analýza úplná. U většiny jevů totiž zcela zásadně záleží na velikosti korpusu (viz např. TTR), ale i na tom, o jaký typ dat jde (např. data psaná vs. mluvená).
- Korpusy ČNK jsou zahrnuty v RIV a na základě toho je třeba je citovat jako jakékoli jiné akademické dílo.
Jak tedy citovat korpusy? V řádku pod logem KonTextu je k dispozici aktuální údaj o tom, který korpus byl pro vyhledání dotazu použit. Po kliknutí na jméno korpusu se zobrazí okno se základními informacemi. Pro práci s korpusem je zcela zásadní informace o jeho velikosti (je značný rozdíl, zda slovo či jev vyhledáme v korpusu milionovém, stomilionovém či několikamiliardovém), a měla by být proto samozřejmou součástí jakékoli korpusové analýzy. Ve spodní části je rovněž uveden návod, jak daný korpus citovat.
Vyzkoušejte si na závěr
- Umíte v korpusu SYN2020 najít všechny výskyty slovního tvaru nejvznešenější?
- Pokud byste chtěli zobrazit všechny výskyty tohoto slova spadající pod příslušný základní tvar, použijte lemma vznešený.
- Výsledek najdete na speciální stránce s řešeními úkolů.
První seznámení s korpusem a typy dotazů máme za sebou, můžeme tedy směle pokračovat 2. lekcí: zobrazením dotazu.
Menu: Nový dotaz • Subkorpus • Uložit • Konkordance • Filtr • Frekvence • Kolokace • Zobrazení • Nápověda • Kurz práce s korpusem v 7 lekcích • 2. lekce




