

Toto je starší verze dokumentu!
Obsah
Specifika vyhledávání v mluvených korpusech
Vyhledávání v mluvených korpusech neprobíhá bezprostředně v originálních datech, jak je tomu u korpusů psaných,1) ale v transkriptu zvukové nahrávky. Jedná se tedy o určitou interpretaci „zvukové“ skutečnosti zachycené v nahrávkách.
Pro dosavadní mluvené korpusy vznikal transkript z audionahrávek, tzn. že přepisující ani badatel nemají k dispozici další doprovodné jevy nezbytně doplňující mluvený projev „tváří v tvář“, jako je např. mimika a gestikulace. Pravidla přepisu vycházejí vždy z určitého kompromisu mezi zachycením detailů a relativní jednoduchostí vyhledávání. Příliš podrobný transkript také stírá výhody korpusového přístupu, neboť se pak vzhledem k omezenému rozsahu mluvených dat zvyšuje podíl jevů, které jsou doloženy jen v jednotkách výskytů, a nelze je tudíž kvantitativně interpretovat. V případě řady ORAL se navíc způsob transkripce snažil navázat na pravidla aplikovaná v PMK. Postupně však docházelo ke změnám, které si vyžádalo zaznamenávání neformální spontánní konverzace a které byly lépe zachytitelné a kontrolovatelné při použití transkripčního programu (sondy pro ORAL2006 a 2008 byly přepisovány pouze v textovém editoru bez spojení se zvukem, čímž byla následná kontrola ztížená). K těmto omezením musí tedy badatel při volbě svých témat přihlížet.
Nicméně se domníváme, že mluvené korpusy neformální konverzace představují nejautentičtější zachycení prototypického jazyka. Nahrávky jsou pořizovány v prostředí přirozeném jak pro mluvčí, tak pro jejich komunikační partnery. Přirozená je pro obě strany i samotná komunikační situace, protože se navzájem znají. To vše značně přispívá k neformálnosti a spontánnosti komunikace. Na druhé straně se zde projevuje určitá omezenost témat a s tím související „chudost“ slovní zásoby ve srovnání s psaným korpusem.
Mluvčí byli postupně nahráváni po celém území republiky a k jejich charakteristice kromě pohlaví, věku a vzdělání patří i zařazení do nářeční oblasti, ve které pobývali v dětství. Tradiční dialektologické dělení (Bělič, 1972), převzaté pro potřeby korpusů řady ORAL, je zobrazeno v následující mapě.
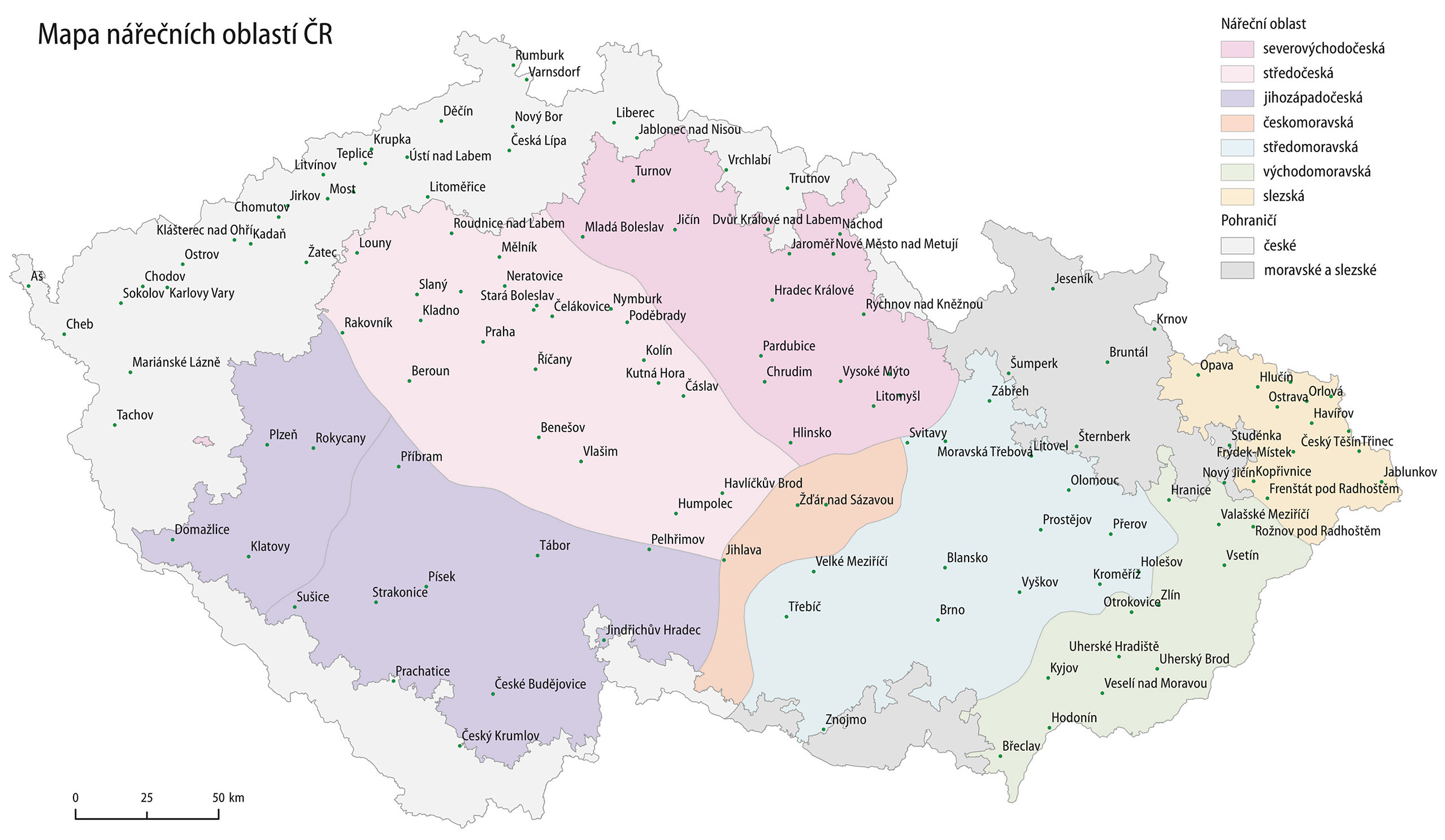
Rozdíly ve značení textu v mluveném a psaném korpuse
U psaného korpusu se doplňující informace týkají především díla samotného – textu, jeho členění, roku vydání atp. U mluveného textu (transkriptu) máme základní informace o jeho autorovi (mluvčím) (viz strukturu). Transkript je ve všech mluvených korpusech členěn podle replik jednotlivých mluvčích; pouze korpus ORAL2013 zachycuje i souběžnou mluvu dvou mluvčích, tzv. „překryvy“, a dělí repliky na menší části, tzv. segmenty, které jsou spojeny se zvukem a lze je přehrát.
V následujícím textu chceme upozornit na odlišnosti při vyhledávání v psaném a v mluveném jazyce a na odlišnosti transkripce jednotlivých korpusů řady ORAL, jejichž neznalost by mohla způsobit špatnou interpretaci nalezených výsledků.
Vyhledávání v mluvených korpusech je v hlavních obrysech stejné jako u psaných korpusů série SYN (stejné základní dva typy dotazů, stejný dotazovací jazyk CQL); pokud jste v korpusu nikdy nehledali, projděte si tedy prosím nejprve rychlokurz v dotazování, zbytek textu předpokládá jeho znalost. V některých ohledech se ale způsob vyhledávání liší, a to zejména v těchto:
- v mluvených korpusech je větší variabilita forem – existují různé transkripční varianty stejného slova, nářeční varianty (sme – zme) apod.,
- mluvené korpusy převážně nedisponují lemmatizací a morfologickým značkováním (varianty sme – zme tedy nejde dohledat pomocí kombinace lemmatu být a značky odkazující k 1. os. mn. č. přítomného času, ale pouze zadáním konkrétní formy, tedy buď sme, anebo zme),
- z povahy materiálu vyplývá, že je o něco složitější zorientovat se v konkordanci.
Nástrahám způsobeným body 1 a 2 se věnujeme v oddíle Jak správně zadat hledané „slovo“, bodu 3 v oddíle Cílenější vyhledávání a pokročilejší dotazy a bodu 4 v oddíle Orientace v konkordanci.
Jak správně zadat hledané „slovo“
Jak již bylo řečeno, korpusy mluveného jazyka většinou nedisponují lemmatizací. Zároveň se v nich tvary některých lexémů vyskytují v mnoha variantách zápisu, které se snaží zohlednit různá specifika konkrétní realizace (převážně nářeční). Při specifikaci hledaného slovního tvaru je tedy namístě co nejvyšší obezřetnost, aby zadaný dotaz pokryl skutečně všechny možné transkripční varianty toho, co chcete vyhledat (tj. aby byl co nejvyšší recall).
Zajímá-li nás například lexém jako celek, ne jen jeden tvar z jeho paradigmatu, je potřeba ručně ošetřit vyhledávání různých tvarů v rámci paradigmatu (a to včetně nářečních, nespisovných variant, které se v přepisech také mohou vyskytnout). Dokonce i pokud nás zajímá pouze jedna položka z paradigmatu, musíme uvážit, že může mít různé varianty, srov. jsou – sou – sú – só.
Nejjednodušší způsob, jak tohoto dosáhnout, je přepnout v rozhraní KonText na Pokročilý dotaz a zadat dotaz v následujícím tvaru:
[word="jsou|sou|sú|só"]
Když do uvozovek zadáte seznam variant oddělený pomocí svislítka (OR), KonText bude jako cílové slovo brát kteroukoli z nich. Znalost regulárních výrazů umožňuje i úspornější zápis než seznam celých forem oddělených svislítky.3)
Stručná charakteristika transkripce korpusů řady ORAL
Pro všechny mluvené korpusy řady ORAL platí obecná zásada, že přepis zachycuje všechny verbální projevy a snaží se co nejvíce přiblížit tradičnímu zápisu podle pravopisu, ale ustálené podoby běžné mluvy a regionální prvky zachycuje bez ohledu na pravopis. Následující tabulka srovnává transkripci jazykových jevů:
| Pojmenování jevu | ORAL2006 | ORAL2008 | ORAL2013 |
|---|---|---|---|
| ustálená zjednodušená výslovnost | pudu, vemu, výde, pocem, dyž, neska, ňák, ďáli, štyry/štyři/čtyry/čtyři, pošta/počta, myslím/myslim/mysim4) | ||
| zápis bez ohledu na výslovnost | zdvojené hlásky, předpona roz-, souhláskové skupiny: každodenní, rozsvítit, rozzlobit, pražští, hřbitov |
||
| slova začínající j- | dle výslovnosti: (j)sem, (j)méno, (j)estli |
||
| protetické v | dle výslovnosti: vokno, von |
||
| předpona vz- a souhláskové skupiny | dle pravopisu: vzbudit, vzpomenu | dle výslovnosti: vzbudit/zbudit, vzpomenu/spomenu |
|
| nářeční varianty | dle výslovnosti: kameň, perkýnko, strejdoj, zme, zrouna, vo našom, nélepší |
||
| souhlásková skupina šť | dle výslovnosti: ještě/ešče |
||
| asimilace znělosti | pravidelné jevy bez variant se zapisují dle pravopisu: dub, sbírat |
||
| - před R L M N Ň J | dle pravopisu: s máslem | dle výslovnosti: s máslem/z máslem, kupme/kubme | dle výslovnosti: s máslem/z máslem, kupme/kubme, kvůli/gvůli |
| - skupina sh- | dle pravopisu: shoda | dle výslovnosti: schoda/zhoda |
|
| asimilace místa tvoření | dle pravopisu: rozčesat, sčítat | dle výslovnosti: roščesat5), ščítat |
|
| hranice slov | respektují se: pod čepicí (NE počepicí), to jo, no no |
||
| kvantita | zachycuje se krácení v koncovkách i základech slov: rohlik, vim, žensky (=ženský) |
||
| zachycuje se dloužení v koncovkách i základech slov, vč. emfatického dloužení: klucí, volál, sebú, bóže |
|||
| komparativ a superlativ | dle pravopisu: novější, pěknější, vlasatější | moravské realizace s dlouhým ě zapisujeme jako kombinaci j + é: novjéši, pěkňéši, vlasaťéši |
|
| zkratky | dle výslovnosti: pokud jako jedno slovo, píše se jako jedno slovo; pokud zvlášť, píše se zvlášť: dé vé dé/dý ví dý/dývídýčko, aids, ú es á |
||
| neznámá X | zápis iks: po iks letech |
||
| velká písmena | u vlastních jmen dle pravopisu | ||
| cizí slova | dle pravopisu: software |
||
| hezitace | zvuky spíše souhláskové se zapisují: hmm6) | zvuky spíše souhláskové se zapisují: mmm |
|
| zvuky spíše samohláskové se zapisují: eee |
|||
| responzní zvuky | viz hezitace | spíše přitakávací zvuky: hmm |
|
| viz hezitace | spíše nesouhlasné, odporovací zvuky: emm |
||
| verbalizovaný smích | zápis dle slyšeného: haha/ha ha, chichi/chi chi |
||
Následující tabulka vysvětluje užívání značek a symbolů:
| ORAL2006 | ORAL2008 | ORAL2013 | |
|---|---|---|---|
| nedořečené, neúplné slovo | značí se hvězdičkou (*): koč*, *ková nekázeň |
||
| pokud za nedořečeným slovem následuje totéž slovo dořečené, neoddělují se čárkou: koč* kočka |
|||
| pokud za nedořečeným slovem následuje jiné slovo, oddělují se čárkou: přijde zít*, pozítří | neoddělují se: přijde zít* pozítří |
||
| příklonné s | neznačí se | značí se *s: dělala *s |
|
| nesrozumitelný úsek | značí se --- | ||
| neukončené promluvy | značí se …: mysim že budu mít co dělat abych …: |
||
| přerušení promluvy | značí se … na začátku i konci přerušené promluvy: mluvčí 1: sjedeš z toho kopce přejedeš … mluvčí 2: no mluvčí 1: … přejedeš řeku |
||
| poznámka, vysvětlivka v přepisu | zapisuje se do kulatých závorek (): (smích) (cizojazyčný projev) (odmlčení)7) |
||
Poslední tabulka srovnává používanou interpunkci:
| ORAL2006 | ORAL2008 | ORAL2013 | |
|---|---|---|---|
| typ interpunkce | větná8) | pauzová9) | |
| tečka (.) | označuje konec promluvy | tečka (.) značí kratší pauzu: sem mu řek že . nevim |
|
| dvě tečky (..) značí střední pauzu: no jo .. a co je eště novýho |
|||
| čárka (,) | dle psaného jazyka: vona byla ještě svobodná , když tam byla , nebo už vdaná ? | neužívá se | |
| pokud za nedořečeným slovem následuje jiné slovo: přijde zít*, pozítří | |||
| neznačí se | u přerušení, změn větné perspektivy: támhleto vem* , vem* , támhleto vemte | ||
| neznačí se | při opakování stejných slov: to já nevim , nevim | ||
| otazník (?) | v otázkách a v případě tázací intonace: to je kdo ? |
||
| vykřičník (!) | v případě zvolací intonace: jéžiš , já sem blbej ! |
||
| spojovník (-) | zápis dle pravopisu (natěsno, bez mezer): e-mail, au-pair, bylo-li |
||
| přímá řeč ("") | neznačí se | značí se "…": řekl sem : " prosim ? " | neznačí se |
Více informací lze nalézt v zásadách přepisu pro ORAL2006 a ORAL2008. Pro více detailů o přepisu nahrávek pro ORAL2013 viz detailní pravidla přepisu.
Anonymizační značky
Kvůli anonymitě byly v přepisech kódovány všechny citlivé údaje (zejména příjmení). Toto pravidlo se netýká jmen známých osob (herců, politiků, sportovců apod.). V případech, kdy si přepisující nebo nahrávaní nepřáli zveřejnit další údaje (např. místní jméno, křestní jméno, název firmy, telefonní číslo), byly kódovány i tyto údaje.
Následující tabulka uvádí seznam anonymizačních zkratek s jejich vysvětlením:
| Anonymizační značka | Vysvětlení |
|---|---|
| NP | příjmení |
| NJ | křestní jméno |
| NN | přezdívka |
| NM | místní jméno |
| NO | ostatní vlastní jména |
| NX | jiný citlivý údaj |
Cílenější vyhledávání a pokročilejší dotazy
Někdy může být žádoucí omezit vyhledávání pouze na korpusové pozice, které odpovídají jistým podmínkám, např. nás mohou zajímat výskyty daného slova pouze v místech, kde mluví víc lidí přes sebe (tzv. překryvy) či v projevech mladších mluvčích. Některé tyto podmínky lze jednoduše „naklikat“ pomocí grafického rozhraní manažeru KonText, jiné je potřeba zadat „ručně“ v dotazovacím jazyce CQL.
Jednoduše dostupné funkce – grafické rozhraní KonText
Specifikace kontextu
Jednou z charakteristik mluveného jazyka je i rozvolněnější syntax a kombinatorika lexikálních jednotek vůbec – zvlášť pokud mluvčí váhá, má tendenci řadit jednotky tak, jak ho napadají, aby si udržel mluvní aktivitu, a na pravidla větné skladby či obvyklou posloupnost prvků ve víceslovných celcích tolik nedbat. Základní dotazy vycházejí z pevného pořadí hledaných slov (tj. připouštějí jen jednu linearizaci), někdy může ovšem být výhodné zadat, že se jisté slovo má nacházet v okolí jiného slova, ne nutně přímo nalevo či napravo. Přesně toto KonText umožňuje, a to buď podmíněním kontextu přímo při zadávání dotazu, nebo dodatečným filtrováním konkordance (jde o dvě cesty k témuž výsledku).
Např. bychom mohli chtít dohledat výskyty slova to, které v okolí ±5 pozic obsahují kterékoli ze slov teda, jo, ne nebo fakt:
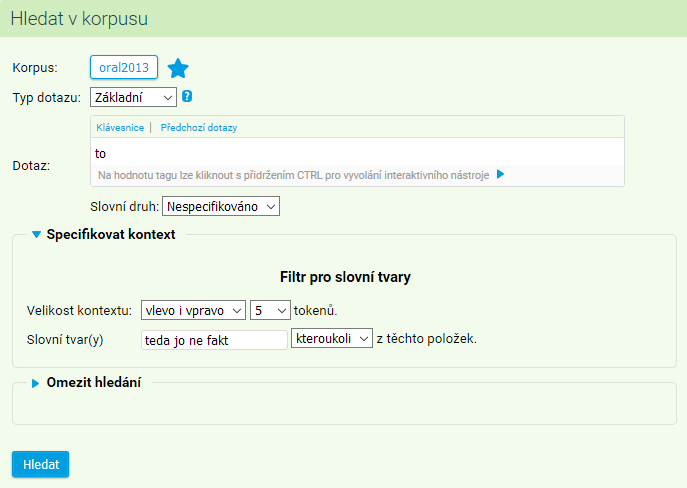
Ve výsledné konkordanci budou výskyty kontextově požadovaných slov zvýrazněné, což usnadní jejich identifikaci:

Omezení hledání
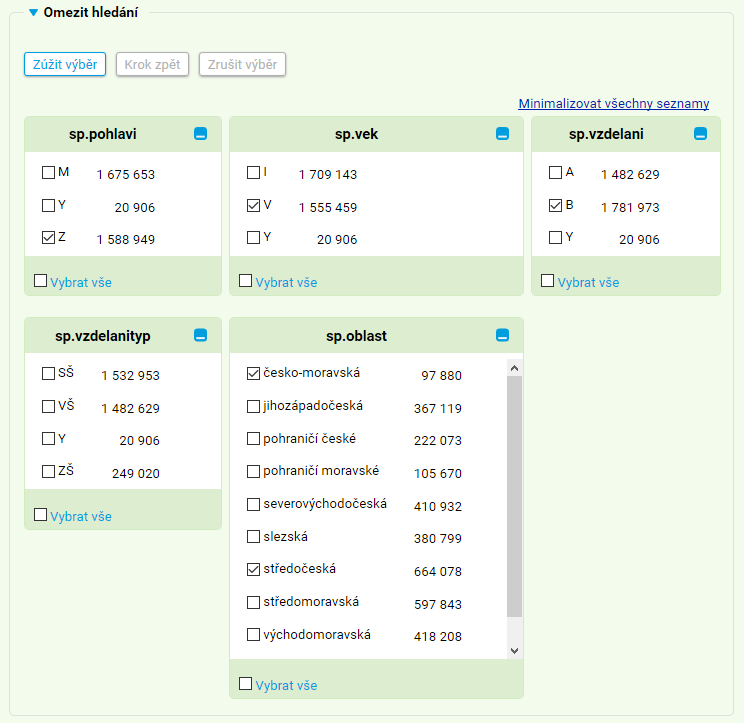
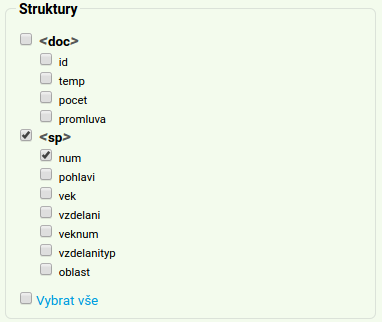
KonText také umožňuje omezit vyhledávání pouze na promluvy mluvčích, jejichž metainformace (věk, pohlaví apod.) splňují jistá kritéria. V zaklikávacím menu jsou dostupné metainformace sp.pohlavi, sp.vek, sp.vzdelani, sp.vzdelanityp a sp.oblast (viz též přehled metainformací v korpusech mluveného jazyka); ostatní metainformace lze specifikovat pouze pomocí dotazu v jazyce CQL (viz níže).
Např. dotaz specifikovaný podle obrázku níže se bude vyhledávat pouze v promluvách (resp. strukturách <sp/>), které pronesla žena (Z) starší 35 let (V) základního nebo středoškolského vzdělání (B) ze středočeské či česko-moravské nářeční oblasti.
CQL
Jazyk CQL nabízí při prohledávání některé možnosti, které v rozhraní KonText jednoduše „naklikat“ nejdou (nezapomeňte si při tom přepnout na správný typ dotazu). Pro zadávání takovýchto složitějších dotazů je nutné mít představu o tom, jak je korpus strukturován, zejména jak je lineárně reprezentován v tzv. vertikále. Než se pustíte do dotazů v jazyce CQL v rámci korpusů mluveného jazyka, projděte si lekci v Kurzu práce s ČNK, kde si tento typ dotazů osvojíte na psaných korpusech.
Pokud si potřebujete strukturu mluvených korpusů jen osvěžit, následuje rychlý přehled. Mluvené korpusy se člení na struktury <doc/>, které představují jednotlivé sondy (ucelené rozhovory v rámci jedné komunikační situace), a ty jsou dále rozdělené na struktury <sp/>. V korpusech ORAL2006 a ORAL2008 představuje jednotka <sp/> ucelenou promluvu jednoho mluvčího, v korpusu ORAL2013 jsou z technických důvodů hranice <sp/> i v místech, kde dochází k překrývání mluvčích, a neexistuje jednoduchý způsob, jak určit, která hranice <sp/> je lingvisticky relevantní (tj. představuje skutečný začátek/konec promluvy) a která je pouze technickou nutností.
V následujícím textu při odkazování na struktury v mluvených korpusech systematicky rozlišujeme tyto tři možnosti:
<sp>(bez lomítka) značí začátek struktury (viz CQL dotaz<sp> [word="to"], který dohledá výskyty tvaru to následující bezprostředně po začátku struktury)</sp>(s lomítkem předsp) značí konec struktury (viz CQL dotaz[word="to"] </sp>, který dohledá výskyty tvaru to bezprostředně předcházející konci struktury)<sp/>(s lomítkem posp) odkazuje k celé struktuře, tj. veškerému obsahu (promluvě) mezi dvěma následnými značkami<sp>a<sp/>(viz CQL dotaz[word="to"] within <sp prekryv="ano"/>, který dohledá výskyty tvaru to v rámci struktur<sp/>, jejichž strukturní atributsp.prekryvmá hodnotu"ano")
Představme si následující útržek konverzace: mluvčí 01 říká ale já zítra nepřijdu, mluvčí 02 mu souběžně se slovem „zítra“ přitaká hmm a mluvčí 03 již souběžně se slovem „zítra“ naváže větou a proč ne ?. V korpusech ORAL2006 nebo ORAL2008 by přepis mohl vypadat následovně:
| mluvčí 01 | <sp>ale já zítra nepřijdu</sp> | ||
| mluvčí 02 | <sp>hmm</sp> | ||
| mluvčí 03 | <sp>a proč ne ?</sp> |
Po překryvech, které byly v popisu situace naznačené, zde není stopy; slova pronesená jednotlivými mluvčími jsou seskupená do souvislých promluv. Naproti tomu v korpusu ORAL2013 by reprezentace dialogu vypadala takto (atribut sp.prekryv značí, zda je daná struktura <sp/> součástí překryvu):
| mluvčí 01 | <sp prekryv="ne">ale já</sp> | <sp prekryv="ano">zítra</sp> | <sp prekryv="ano">nepřijdu</sp> |
| mluvčí 02 | <sp prekryv="ano">hmm</sp> | ||
| mluvčí 03 | <sp prekryv="ano">a proč ne ?</sp> |
Jak vidno, zatímco cílem korpusů ORAL2006 a ORAL2008 je přetavit dialog do jedné linie promluv, ORAL2013 se již snaží zachytit onen poměrně typický jev, kterým je mluva více účastníků konverzace najednou (byť s jistými omezeními: překrývat se mohou vždy jen projevy právě dvou mluvčích). Detailněji se tématu věnuje oddíl Orientace v konkordanci.
V příkladech níže jsou X či Y zástupnými symboly pro jakýkoli validní dotaz jazyka CQL, např. [word="to"], pokud chceme vyhledat slovní tvar to.
Souvýskyt bez ohledu na pořadí
Kromě funkcí pro specifikaci kontextu, resp. filtrování, které jsou pohodlně zabudované do rozhraní KonText, lze pro účely vyhledání souvýskytu slov bez ohledu na pořadí používat i operátory meet a union jazyka CQL. Dotaz (meet "to" "teda" -1 2)10) vyhledá výskyty to, jimž bezprostředně předchází (levý kontext -1) nebo na něž v jedné ze dvou následných pozic navazuje (pravý kontext 2) slovo teda. Výše uvedený příklad na specifikaci kontextu bychom s pomocí meet mohli přepsat jako (meet "to" "teda|jo|ne|fakt" -5 5).
Operátor union pak slučuje množiny výsledků definované pomocí jednotlivých operátorů meet do jedné konkordance, v důsledku čehož jsou tyto operátory v jistém ohledu flexibilnější než specifikace kontextu pomocí filtru, neboť umožňují vyhledávat libovolné množství arbitrárních dvojic s různými požadavky na kontextovou blízkost. Na druhou stranu ovšem ve výsledné konkordanci chybí zvýraznění kontextově podmíněných slov, takže pokud vysloveně zmíněnou flexibilitu nepotřebujete, je pohodlnější (z hlediska zadávání dotazu i následné analýzy) použít specifikaci kontextu pomocí filtru popsanou výše.
Zúžení prohledávaných struktur podle metainformací
Množinu struktur (doc nebo sp, viz Struktura korpusů mluvené češtiny), které budou v rámci dotazu prohledány, lze omezit tím, že specifikujeme, jakých hodnot musí, nebo naopak nesmějí některé atributy těchto struktur nabývat (atributy, s nimiž lze v korpusech řady ORAL pracovat, jsou shrnuty zde). K tomu slouží operátory within nebo containing. Oba operátory se liší pouze syntaxí – X within Y je totéž co Y containing X – a způsobem zobrazení výsledné konkordance.
Obecný úvod do problematiky podmínek within je k dispozici v jedné z předchozích lekcí; zde se omezíme na pár příkladů využívajících struktury a atributy korpusů mluveného jazyka. Mohli bychom chtít hledat např.:
- v blízkosti míst střídání mluvčích (struktura
<sp/>):- začátek promluvy:
<sp> X - konec promluvy:
X </sp>
V korpusu ORAL2013 tyto dotazy odpovídají i místům, kde jsou z technických důvodů umístěny hranice struktur <sp/> kvůli záznamu překryvů (viz výše), které bohužel nelze nijak jednoduše odlišit od skutečných začátků/konců promluv.
- v překryvu11):
X within <sp prekryv="ano" /> - pouze u starších mluvčích z Moravy a Slezska (lze i „naklikat“ v novém dotazu v KonTextu):
X within <sp vek="V" & oblast="pohraničí moravské|slezská|středomoravská|česko-moravská|východomoravská" /> - pouze u mluvčích se základním vzděláním (v KonTextu „naklikat“ nelze, neboť atribut
sp.vzdelanitypnení součástí menu):X within <sp vzdelanityp="SŠ" /> - u mluvčích starších 30 let:
X within <sp veknum="1?[3-9]\d" />- atributy jsou vždy uložené jako řetězce znaků, nelze s nimi tedy pracovat jako s čísly (dotazy typu
X within <sp veknum>=30 />nejsou možné) - specifikace věku je založena na regulárním výrazu:
1?: na začátku může, ale nemusí být1(pro případ, že by v korpusu byli mluvčí starší sta let)[3-9]: následující znak (= desítky) může být kterákoli číslice mezi3a9\d: poslední znak (= jednotky) může být kterákoli číslice
Přesnou syntax pro zadání podmínky within není nutné znát zpaměti, pokud je v KonTextu zvolen typ dotazu CQL, je k dispozici pomůcka, která vám ji pomůže vložit:

within. Hledání sekvencí slov
Pokud hledáte víceslovnou sekvenci, většinou dotaz spadá do jedné ze dvou kategorií:
- buď má jít o ucelenou konstrukci, kterou pronesl jeden mluvčí,
- nebo se jedná o sekvenci, která se typicky objevuje v místě střídání mluvčích
Není běžné, že by bylo z hlediska lingvistické analýzy lhostejné, zda celou sekvenci pronesl mluvčí jeden, či zda v jejím průběhu došlo k prostřídání. Při znalosti členění mluvených korpusů na struktury <sp/>, které ohraničují promluvy jednotlivých mluvčích, nás tedy může napadnout následující řešení (X a Y zde značí vyhledávanou sekvenci slov):
X Y within <sp/>X <sp> Y, tj. takovéXaY, mezi nimiž se vyskytuje strukturní značka začátku nové promluvy
Takto jednoduše ovšem postup platí pouze u korpusů ORAL2006 a ORAL2008, kde nejsou zachyceny překryvy. Jak bylo popsáno výše, v korpusu ORAL2013 jsou z technických důvodů projevy dvou mluvčích, kteří se společně účastní jednoho překryvu, vyčleněny do samostatných promluv. <sp> se tedy může vyskytnout i tam, kde jeden mluvčí pokračuje v předchozí promluvě, jen mu paralelně do řeči skočí další mluvčí.
Představme si následující dialog:
| mluvčí 00 | hele to fakt | nevim | |
| mluvčí 01 | ale | nekecej |
Z hlediska jazykového jde o dvě promluvy dvou mluvčích, leč ve vertikále budou reprezentovány čtyřmi strukturami <sp/> (pro jednoduchost vynecháváme některé atributy, úplnější příklad vertikály mluveného korpusu lze nalézt zde):
<sp num="00" prekryv="ne"> hele to fakt </sp> <sp num="00" prekryv="ano"> nevim </sp> <sp num="01" prekryv="ano"> ale </sp> <sp num="01" prekryv="ne"> nekecej </sp>
V tomto příkladu je sekvence fakt nevim součást jedné promluvy mluvčího 00, ale dotazem [word="fakt"] [word="nevim"] within <sp/> bychom tento výskyt nedohledali, neboť obě slova nejsou součástí jedné struktury <sp/> a podmínka within tak není splněná. Naopak by nám tento výskyt falešně spadl do druhé kategorie, neboť mezi fakt a nevim je značka <sp>.
První problém bohužel nijak řešit nelze, druhý ano – za cenu toho, že spolu s odfiltrovanými falešnými výsledky přijdeme i o některé správné kandidáty (snížíme recall a zvyšíme precision):
X <sp prekryv="ne"/> <sp prekryv="ne"> Y
Tímto zajistíme, že X a Y náleží do dvou různých struktur <sp/>, které zároveň nejsou součástí překryvu, takže na jejich švu skutečně musí docházet k vystřídání mluvčích. Zároveň tím ale pochopitelně přijdeme o všechny případy, kde ke střídání dochází s překryvem. Jinými slovy, toto na základě výše uvedeného dotazu najdeme:
| mluvčí 00 | … X | |
| mluvčí 01 | Y … |
a toto již ne:
| mluvčí 00 | … | X | |
| mluvčí 01 | Y | … |
Orientace v konkordanci
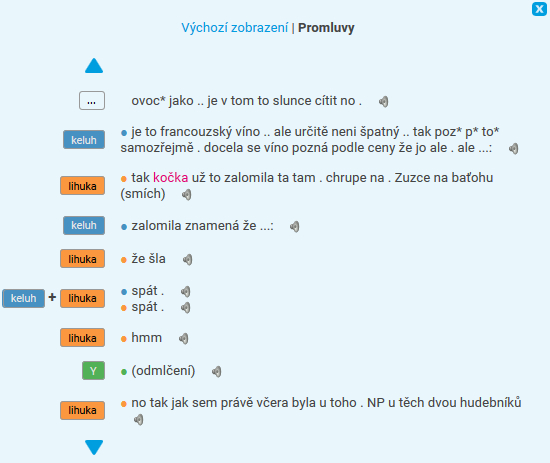
Jak již bylo zmíněno v úvodu, z povahy materiálu vyplývá, že zorientovat se v konkordančních řádcích z mluveného korpusu bývá těžší než u korpusu psaného, ať už kvůli střídání mluvčích, syntaktické a tématické roztříštěnosti, velké závislosti promluv na sdíleném kontextu, který nelze badateli jednoduše zprostředkovat, nebo kvůli tomu, že přepis je při nejlepší vůli jen značně ochuzeným odrazem původní promluvy a některé lingvisticky relevantní a pro porozumění důležité informace v něm mohou chybět (intonace, detailní temporální struktura promluvy, která může naznačovat např. váhání, apod.). Obecně platí, že je dobrý nápad v obecných volbách zobrazení rozšířit kontext KWIC na větší počet pozic, aby bylo možné si promluvu zasadit do širšího rámce. K témuž účelu poslouží kliknutí na KWIC, které vám zobrazí okénko s delším kusem dialogu. Pro lepší orientaci ve struktuře dialogu je lepší přepnout toto rozšířené okno z Výchozího zobrazení na Promluvy (viz obrázek). Každý mluvčí je barevně odlišen a jeho promluvu je možné si pustit pomocí symbolu reproduktoru. Toto zobrazení také umožňuje lepší přehled o překryvech, kterou jsou signalizovány spojením obou mluvčích pomocí +.
Návaznost replik a přehrávání zvuku
ORAL2006 a ORAL2008
Jak jsme si řekli výše, byla v přepisu pro korpusy ORAL2006 a ORAL2008 snaha překrývající se repliky více mluvčích „rozplést“ do samostatných ucelených promluv. Když se takový přepis zobrazí linearizovaný do jednoho konkordančního řádku, mělo by tedy být možné jej číst relativně pohodlně. Aby bylo možné určit hranice promluv jednotlivých mluvčích, je ovšem nutné v zobrazení atributů, struktur a metainformací zaškrtnout zobrazení struktury <sp/>, která tyto hranice značí. Je dobré zde rovnou zaškrtnout též poziční atribut sp.num, který umožní odlišit v rámci sondy jednotlivé mluvčí.
<sp/> a strukturního atributu sp.numZobrazení konkordance pak vypadá následovně:

<sp/> a strukturního atributu sp.numMožnost přehrát si k replice odpovídající zvukovou nahrávku v těchto dvou korpusech není k dispozici.
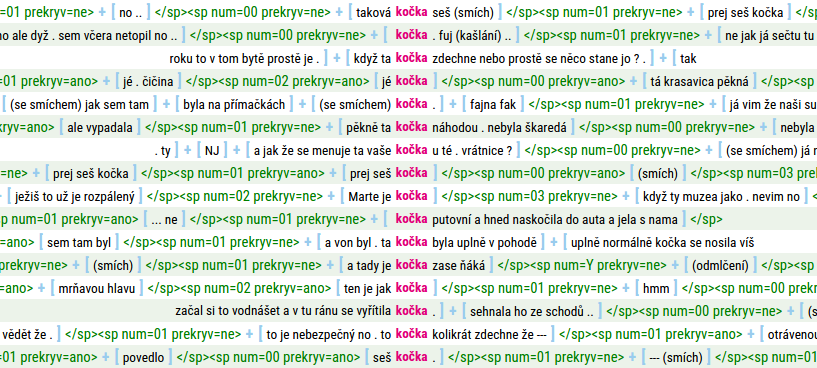
ORAL2013
Korpus ORAL2013 naopak přehrávání zvuku umožňuje, a to pomocí bleděmodře zbarvených hranatých závorek […] a znamének + rozmístěných v konkordančních řádcích. Kliknutím na [ nebo ] přehrajete segment, který je závorkami obklopen; kliknutím na + přehrajete jeden po druhém segmenty po obou stranách znaménka. Při bližším ohledání je zřejmé, že + není umístěno mezi všemi segmenty: tam, kde + není, jsou sousední segmenty součástí překryvu a patří k nim tedy stejný zvukový úryvek. Struktura dialogu je tak částečně naznačena už ovládacími prvky pro přehrávání zvuku.
Přesto se ovšem při důkladnější analýze komplexních výměn replik nejspíš neobejdete bez zobrazení struktur <sp/>, znovu zejména kvůli informaci o číslu mluvčího sp.num (za účelem spárování replik patřících stejnému účastníkovi) a také kvůli explicitnímu zobrazení atributu sp.prekryv, který poskytuje stejnou informaci jako znaménko + (zda je promluva součástí překryvu, či není), jen nápadnějším způsobem. Pokud si chcete konkordanci exportovat a pracovat s ní v nějakém externím programu, je zobrazení těchto struktur a atributů nutností, neboť značky [, ] a + se při exportu ztratí.
<sp/> a strukturních atributů sp.num a sp.prekryv Mnohem přehlednější je však pracovat s replikami dialogu v náhledu Promluvy, jež se zobrazí po kliknutí na KWIC. Také v tomto režimu lze jednotlivé repliky pohodlně přehrát.
 Honzo, sem obrázek toho náhledu, vyber 1 z koček výše
Honzo, sem obrázek toho náhledu, vyber 1 z koček výše
Metainformace u KWIC
Jak je patrné z obrázku v předchozí sekci, který ukazuje výběr struktur a atributů k zobrazení, můžete si přímo v textu konkordance zobrazit kromě čísla mluvčího a případně překryvu i jiné údaje jako např. oblast původu mluvčího (atribut sp.oblast) nebo jeho věkovou skupinu (atribut sp.vek). Pokud si těchto atributů ovšem zaškrtnete více, konkordance začne být velmi rychle nepřehledná, neboť se budou zobrazovat u každé struktury <sp/> (budou tedy vložené do přepisu).
Alternativní způsob je zobrazit si stejné údaje jako metainformace na levém okraji konkordance. Na každém řádku konkordance je pak zobrazen údaj, který odpovídá danému atributu struktury, do níž patří KWIC. Pokud vás tedy tolik nezajímá struktura dialogu a jde vám spíš o vlastnosti konkrétní promluvy, jíž součástí je KWIC, bude toto zobrazení mnohem pohodlnější.


sp.prekryv) Zdrojem velmi zajímavých sociolingvistických analýz mohou být frekvenční distribuce vytvořené na základě metainformací v menu Frekvence → Vlastní. S jejich pomocí je možné zjistit, zda hledaný výraz na pozici KWIC používají více ženy, či muži, mladší, či starší mluvčí, případně zda má nějaká regionální specifika, či se naopak zdá být sdílený všemi mluvčími češtiny bez rozdílů.

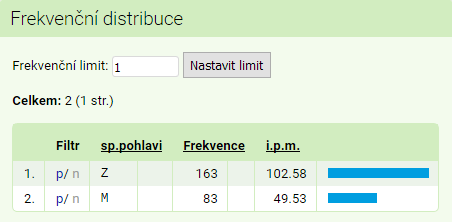
[word="(?i)koč(ič|k).*"] podle pohlaví: zdá se, že alespoň v korpusu ORAL2013 o kočkách, kočičkách ap. mluví více ženy než muži Některé zajímavé dotazy
Varianty výrazu protože
Na to, jak je slovo protože v mluvené řeči běžné, je až nepohodlně dlouhé (3 slabiky!). Není proto divu, že se jej mluvčí často snaží různými způsoby výslovnostně ošidit a artikulační úsilí raději věnovat slovům, která nesou více obsahu a nejsou tak snadno odhadnutelná. V korpusu ORAL2013 se v přepisu vyskytují následující výslovnostní12) varianty výrazu protože:
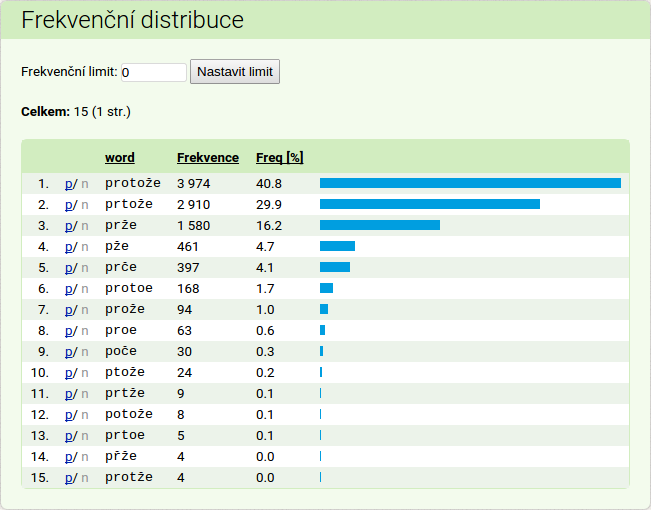
Zkuste si některé z nich vyhledat. Odhalí frekvenční distribuce podle sociolingvistických metainformací nějaké vzorce v jejich užívání?
Kolokace s pauzami (v korpusu ORAL2013)
Která slova se v naší řeči nápadně často vyskytují v okolí pauz? Zkuste v korpusu ORAL2013 zadat CQL dotaz [word="\.{1,2}"] a zobrazit si kolokace. Nezapomeňte na možnost zobrazit si pomocí odkazů p/n pozitivně/negativně filtrovanou konkordanci k danému kolokátu a prozkoumat tak do detailu, jak jednotlivé kombinace fungují.
Kolokace s hezitačními zvuky
Podobně zajímavé jsou i kolokace s hezitačními zvuky. Ty dohledáme v korpusu ORAL2013 pomocí CQL dotazu [word="mmm|eee"], v korpusech ORAL2006 a ORAL2008 pak pomocí dotazů [word="hmm|eee"].
[word="j?sou|s[úó]"].word, jinak by dotaz pochopitelně musel znít (meet [word="to"] [word="teda"] 0 2).sp.prekryv je k dispozici pouze v korpusu ORAL2013.



