

Obsah
Menu: Dotaz
Základním způsobem dotazování v korpusu je dotaz syntagmatický, jehož výsledkem je konkordance, tj. seznam všech výskytů (tokenů) odpovídajících dotazu spolu s jejich textovým okolím. Spouští se pomocí volby Dotaz → Konkordance.
Rozšířením dotazu syntagmatického je hledání paradigmatické, jež je vlastně kombinací několika dílčích syntagmatických dotazů a přináší průnik jejich frekvenčních distribucí. Výsledkem paradigmatického dotazování je tak množina typů, které odpovídají všem jednotlivým syntagmatickým dotazům. Spouští se pomocí volby Dotaz → Paradigmatický dotaz.
Další rozšiřující funkce umožňuje vytvořit seznam různých slov (typů), které dotazu odpovídají, spolu s jejich absolutní frekvencí, ARF nebo počtem dokumentů, v němž se hledaný jev vyskytuje. Spouští se pomocí volby Dotaz → Seznam slov.
Konkordance
Pomocí volby Dotaz → Konkordance je možné kdykoli začít nové hledání v korpusech. Kliknutím na tuto volbu opustíme předchozí vyhledaný dotaz, případně výsledky na něm vytvořené, a začínáme s novým hledáním. Následující text se zabývá především pokládáním dotazu do jednojazyčných korpusů, specifika zadávání dotazů do paralelního korpusu InterCorp popisuje podrobněji bonusová lekce základního kurzu práce s ČNK.
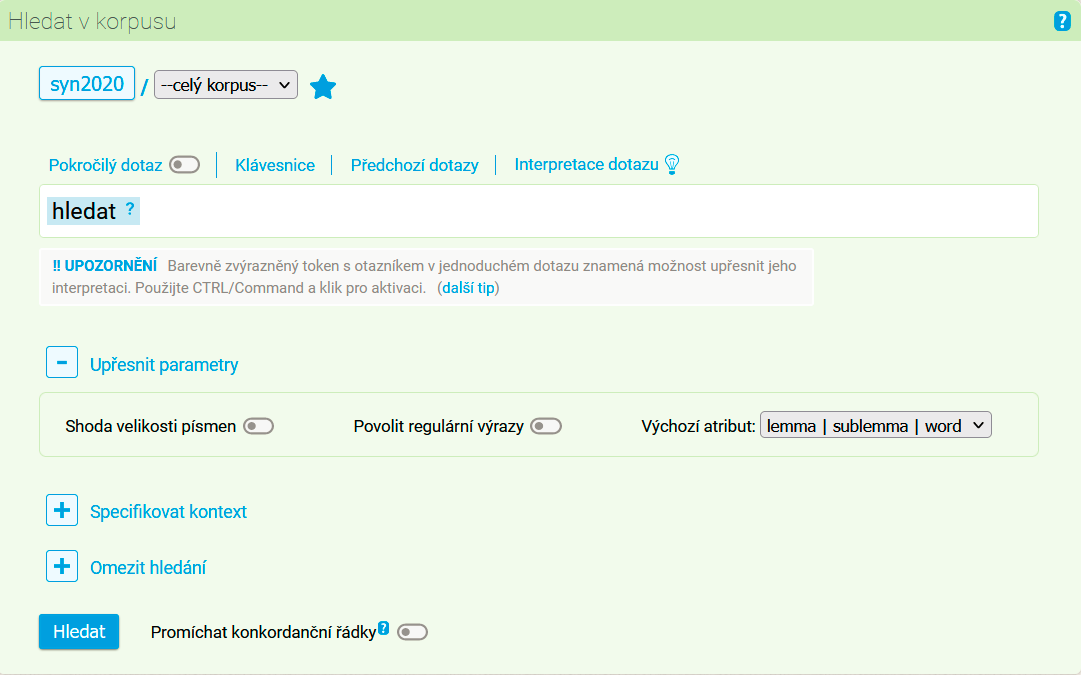
Po kliknutí na položku Konkordance se uživateli zobrazí základní menu pro dotazování. V rámci tohoto formuláře je možné zvolit korpus, v němž se bude vyhledávat, a ve vstupním řádku pod ním zadat dotaz. Pomocí přepínače lze aktivovat funkci Pokročilý dotaz, která pracuje s dotazovacím jazykem CQL. Součástí formuláře je i interaktivní mezinárodní klávesnice pro zápis speciálních znaků (zejména pro vyhledávání v nečeských textech a pro vkládání speciálních znaků jazyka CQL). Dříve položené dotazy je možné vyvolat jednak přímo v menu, jednak pomocí odkazu Předchozí dotazy nad dotazovacím řádkem. Poslední položkou v liště nad řádkem je Interpretace dotazu, kde uživatel zjistí, jak bude jeho dotaz vyhodnocen (de facto přeložen do CQL) a zda je tato interpretace v souladu s jeho záměrem. Tato funkce ztrácí smysl při přepnutí do režimu pokročilého dotazu, místo ní je však možné přímo vkládat interaktivně generované morfologické značky (u korpusů, které jsou takto značkovány) či podmínky specifikující texty, v nichž se má hledat (podmínka within) – viz položky Vložit tag a Vložit within.
Volba korpusu
Volba korpusu vhodného pro řešení dané výzkumné otázky je důležité rozhodnutí, které je nutné učinit ještě před samotným započetím výzkumu. Spektrum korpusů dostupných v projektu ČNK se neustále rozšiřuje, způsob výběru korpusu v rozhraní KonText proto kombinuje rychlý přístup k personalizovanému výběru (oblíbeným korpusům) spolu s výběrem pomocí tzv. štítků, které charakterizují jejich hlavní vlastnosti.
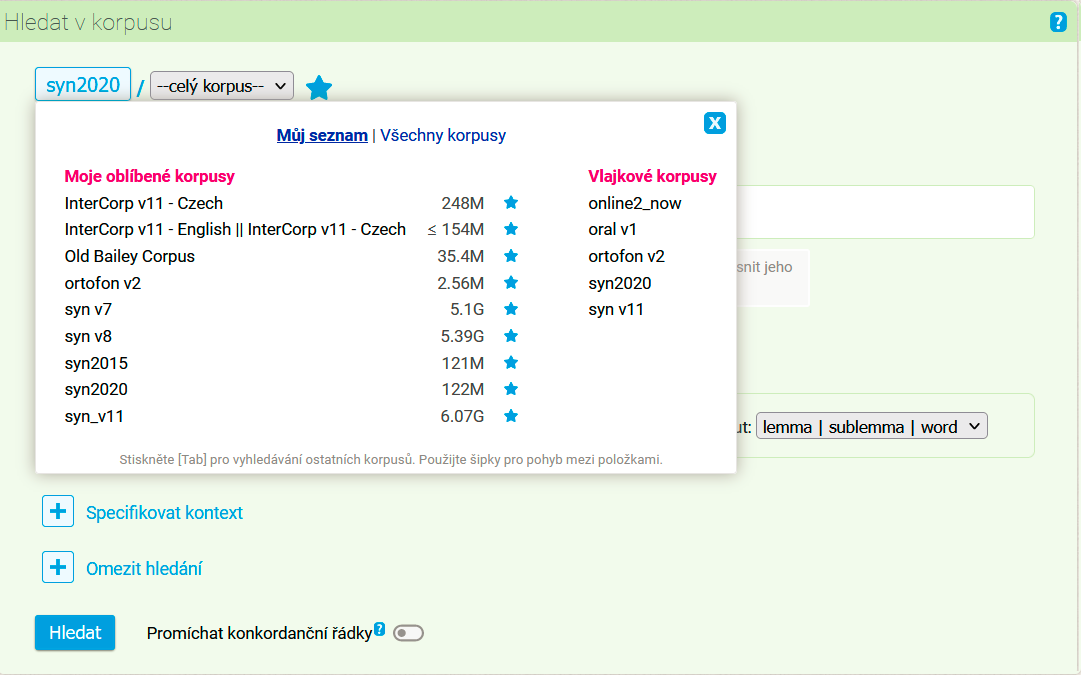
Po kliknutí na jméno korpusu (ve výchozím nastavení je jím vždy aktuální reprezentativní korpus synchronní psané češtiny, v současnosti SYN2020) se objeví rámeček pro výběr pracovního korpusu, který má dvě hlavní části:
- Můj seznam se zrychlenou volbou korpusů na jedno kliknutí. Tato zrychlená volba obsahuje jednak oblíbené korpusy, jejichž výběr je plně na uživateli, a dále tzv. vlajkové korpusy: přednastavený seznam několika korpusů, které ČNK považuje za reprezentanty jednotlivých oblastí své produkce. Jejich soustředění do jednoho místa pak usnadňuje volbu korpusu zejména uživatelům, kteří s ČNK pracovat teprve začínají. Oblíbené korpusy je možné zvolit buď na stránce se všemi dostupnými korpusy, nebo při práci s nimi v okamžiku zadávání dotazu (takové korpusy jsou signalizovány žlutou hvězdičkou).
- Všechny korpusy s možností výběru na základě jména a tzv. štítků, které korpusy charakterizují (typický korpus má štítků několik, např. SYN2020:
psaný,synchronní,čeština,řada SYN,reprezentativní). Hledáte-li tedy například webový korpus češtiny, stačí zvolit štítkyčeština+webovýa objeví se všechny takové korpusy, které má ČNK v nabídce. Vyhledávání je možné zpřesňovat také zadáním části jména korpusu nebo jeho popisu do vyhledávacího řádku, výsledný seznam korpusů se přitom podle takto zadaných klíčových slov nebo jejich částí interaktivně filtruje. Je však třeba mít na paměti, že seznam z prostorových důvodů zobrazuje pouze prvních 25 položek; je-li seznam příliš dlouhý, je potřeba dotaz zpřesnit přidáním dalšího štítku nebo vyhledáním části jména korpusu.
Příklad: Uživatel hledá v záložce Všechny korpusy současnou verzi anglické části paralelního korpusu InterCorp. Zvolí nejprve štítky InterCorp a současná verze (pro výběr více štítků je třeba zároveň stisknout klávesu Ctrl/Command), v seznamu se objeví prvních 25 korpusů vyhovujících zadané podmínce, ačkoli InterCorp zahrnuje mnohem více jazyků. K nezobrazeným korpusům se lze dostat dalším filtrováním pomocí zadání části názvu či jazyka (pozor: názvy jednotlivých jazykových mutací korpusu InterCorp jsou anglicky!). Nalezený korpus lze kliknutím vybrat a začít v něm vyhledávat. Pomocí hvězdičky jej lze zároveň označit jako oblíbený; tím je tento korpus zařazen na seznam oblíbených korpusů a lze se k němu rychle a snadno dostat na jedno kliknutí.
Typy dotazů
Současná verze KonTextu rozlišuje pouze dva typy dotazu: jednoduchý a pokročilý.
Předchozí verze KonTextu pracovaly se 6 typy dotazů: základní, lemma, fráze, slovní tvar, část slova a CQL. Současný jednoduchý dotaz zahrnuje prvních pět typů, jejich funkcionality lze docílit změnami nastavení jednoduchého dotazu, např. výchozího atributu a/nebo použitím regulárních výrazů (viz dále). Současný pokročilý dotaz plně odpovídá předchozímu typu CQL.
Výchozím nastavením je jednoduchý dotaz, v němž je dále implicitně nastaveno nerozlišování velikosti písmen (přepínač Shoda velikosti písmen je vypnutý), není povoleno použití regulárních výrazů (přepínač Povolit regulární výrazy je vypnutý) a vyhledávání je nastaveno podle výchozího atributu lemma|word (v nových synchronních korpusech počínaje SYN2020 lemma|sublemma|word), čímž se vyhledá nejen uvedený tvar (podle atributu word), ale i další tvary slova (podle atributů lemma nebo sublemma), pokud je zadaný tvar zároveň lemmatem nebo sublemmatem (poznámka: oproti předchozím verzím KonTextu nejde o změnu, jen o zobecnění chování původního základního dotazu). Do vstupního řádku je možné kromě jednotlivých slov zadávat i celé fráze. Vyhledávání lze na jednotlivých pozicích upřesnit jednak pomocí našeptávače (zatím jen v nových synchronních korpusech, viz další oddíl), jednak změnou výchozího atributu (atribut je pak platný pro všechny pozice) a/nebo přepnutím shody velikosti písmen. Složitější dotazy je možné pokládat i v rámci jednoduchého dotazu, pokud uživatel využije volby Povolit regulární výrazy.
Pokročilý dotaz se aktivuje spínačem nad vstupním řádkem a plně odpovídá dotazu typu CQL předchozích verzí KonTextu. Při zadávání dotazovacího jazyka CQL KonText automaticky kontroluje a zvýrazňuje syntax dotazu. V případě, že dotaz není validní, KonText na to uživatele upozorní a umožní mu dotaz před vyhodnocením opravit. Vzhledem k širokým možnostem CQL dotazování však není kontrola správnosti dotazu vždy přesná, výjimečně se tak může stát, že se varování objeví i v případě validního dotazu.
Je-li zadán dotaz, je možné spustit vyhledávání buď kliknutím na tlačítko Hledat, nebo stisknutím klávesy Enter (kurzor musí být umístěn ve vstupním řádku).
Vedle tlačítka Hledat je zároveň umístěna volba Promíchat konkordanční řádky. Tuto volbu je vhodné mít stále zapnutou, protože zobrazuje konkordance v náhodném pořadí, což je klíčové pro správnou a nezavádějící interpretaci výsledku. Podrobněji viz na stránce Konkordance.
Vyhodnocení dotazu
Pokud je hledání úspěšné, zobrazí se stránka s konkordančním seznamem, jejíž ovládání je podrobně popsáno na stránce Konkordance.
Našeptávač
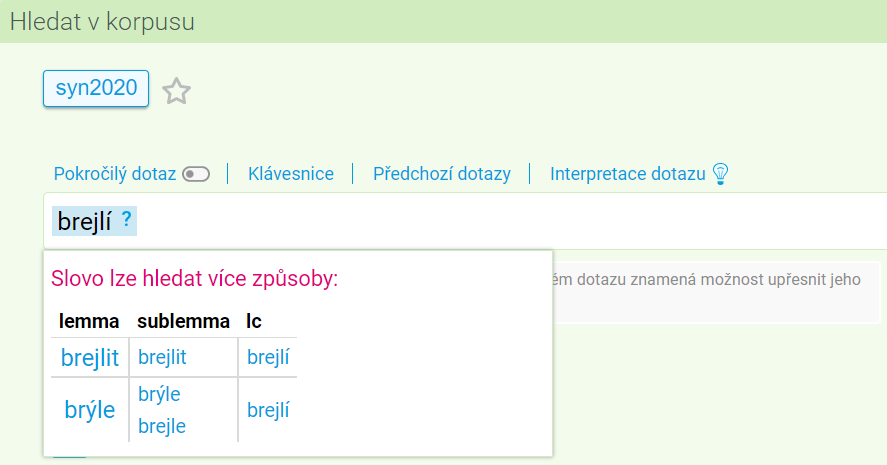
Pro korpusy s tzv. dvouúrovňovou lemmatizací (zatím české synchronní korpusy počínaje SYN2020 a SYN verze 9) je k dispozici tzv. našeptávač, nástroj nabízející na základě zadaného slovního tvaru další možné způsoby hledání slova (nebo i více slov), k němuž tento tvar náleží. Při aktivaci našeptávače se slovní tvary, které jsou v daném korpusu rozpoznány, ve vstupním řádku barevně zvýrazní, zprava vedle nich se pak objeví ikonka otazníku. Klikne-li uživatel na daný výraz a současně stiskne klávesu Ctrl/Command, objeví se nabídka výrazů v podobě lemmat, sublemmat a lc (tvarů nezávislých na velikosti písmen), z nichž je možné vybrat ten nejvhodnější, který pak zadaný tvar nahradí. Dojde tak ke změně původní interpretace daného výrazu, která je indikována zčervenáním volby Interpretace dotazu nad dotazovacím řádkem.
Např. při vložení tvaru brejlí nás našeptávač upozorní, že tento tvar je v korpusu SYN2020 anotován v závislosti na kontextu pod dvěma různými lemmaty (brejlit a brýle), a navíc nám ukáže, že lemma brýle zahrnuje dvě sublemmata, stylistické varianty brýle a brejle. Uživatel má tedy možnost dotaz upravit tak, že bude hledat buď (i) všechny tvary vybraného slova nezávisle na variantě (sloupec lemma, např. brýle), nebo (ii) jen tvary slova patřící pod danou variantu (sloupec sublemma, např. brejle), nebo (iii) jen tvar nezávislý na velikosti písmen patřící pod lemma uvedené na řádku (sloupec lc, např. brejlí pod lemmatem brýle). Podobně našeptávač upozorňuje i na lemmata a sublemmata lišící se velikostí písmen (např. Procházka oproti procházka). Příklady zpracování variant v SYN2020 najdete zde.
Upřesnit parametry
Jak již bylo uvedeno výše, lze při zadávání dotazu specifikovat také další parametry, které ovlivňují jeho interpretaci: jde jednak o výchozí poziční atribut, v režimu jednoduchého dotazu je to dále zohlednění velikosti písmen (case-sensitivity) a také povolení použití regulárních výrazů.
Specifikovat kontext
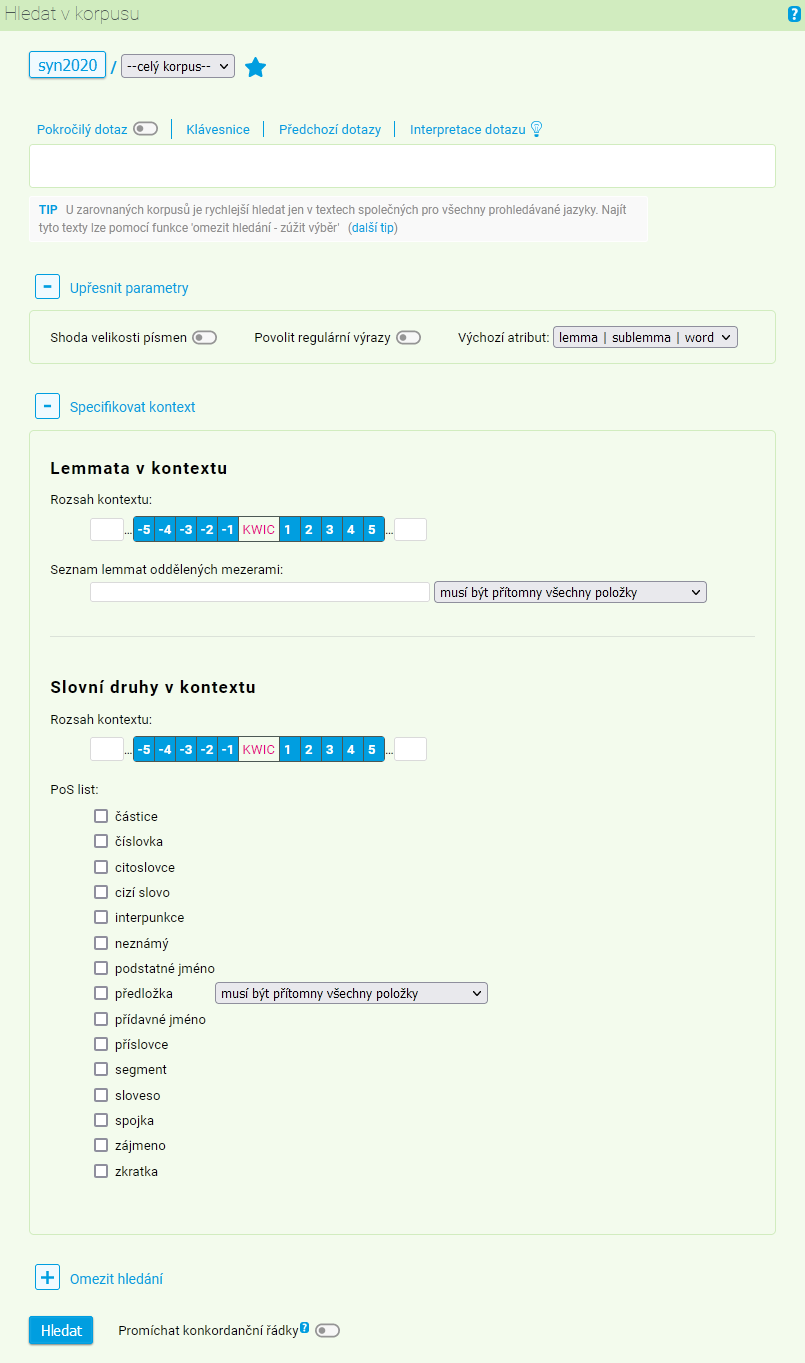
Každý dotaz je možné dále specifikovat s ohledem na kontext (textové okolí), v němž se hledané slovo nebo fráze vyskytuje. Ke specifikaci slouží kontextová nabídka, která se nachází ve spodní části dotazovacího formuláře.
Ve své podstatě je hledání v kontextu dodatečným filtrováním základní konkordance, která je specifikována již dotazem přímo v dotazovacím formuláři. Uživatel tu má možnost nastavit rozsah kontextu, na nějž bude dodatečná filtrovací podmínka aplikována, konkrétní lemmata, případně i slovní druhy.
Obecně je možné říci, že libovolné hledání v kontextu lze převést na běžné hledání a následné filtrování (pomocí pozitivního nebo negativního filtru). Filtrování je však také možné uskutečnit pomocí dotazovacího jazyka a provést totožnou operaci v rámci jediného kroku. Platí tedy, že k jednomu výsledku vede vícero cest a záleží plně na uživateli, kterou možnost považuje za nejpohodlnější.
Omezit hledání
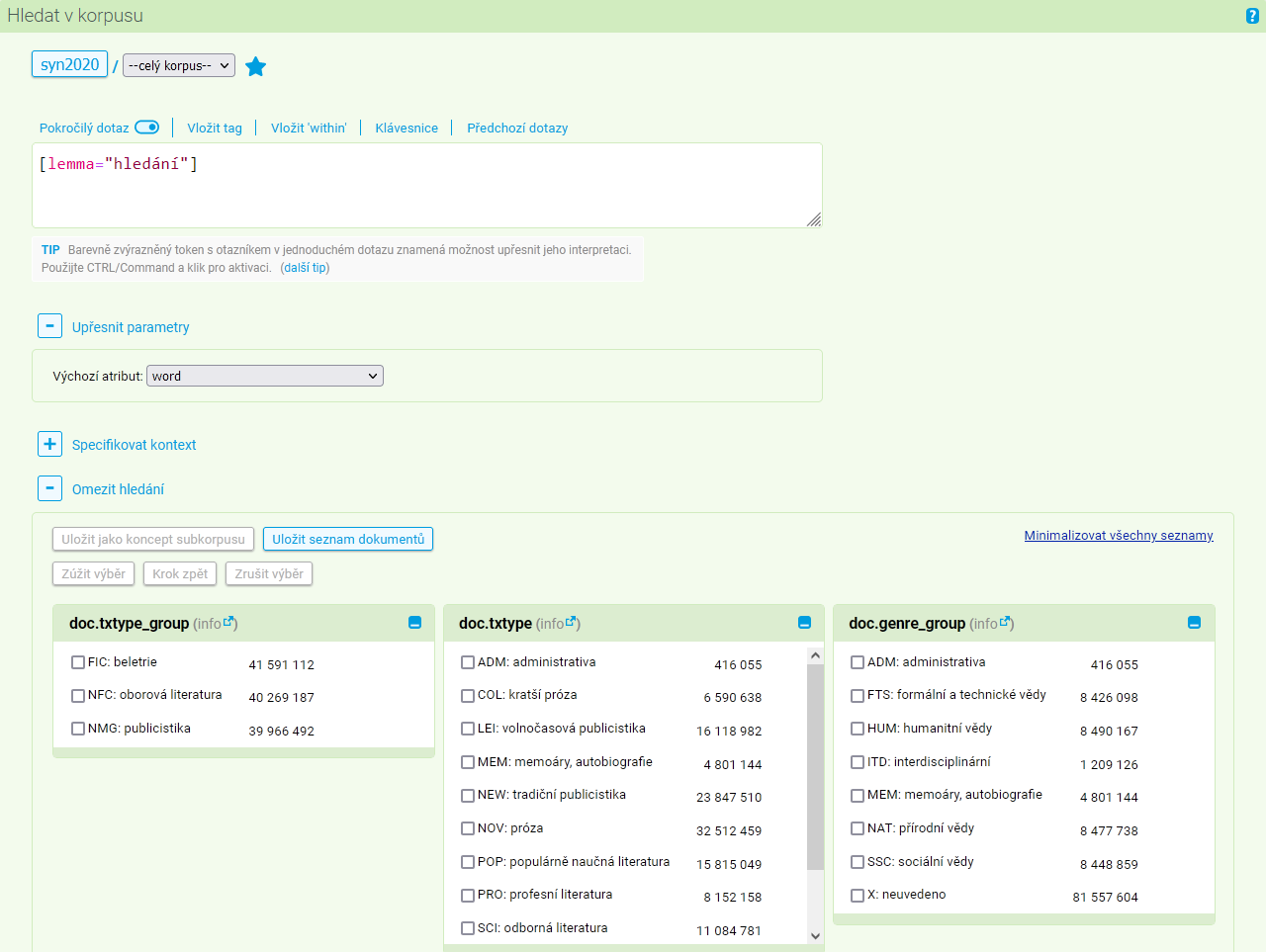
Potřebujeme-li hledat jen v úzce vymezené skupině textů z celého korpusu, máme dvě možnosti. Buď vytvoříme vlastní virtuální subkorpus, který bude pak možné vybrat v rámci nabídky korpusů, nebo dotaz omezíme nějakými podmínkami (typicky pomocí příkazu within). První možnost volíme zpravidla v situacích, kdy víme, že subkorpus budeme potřebovat delší dobu, nebo když je jeho specifikace složitá. Druhou možnost pak užíváme při ad hoc hledání v rámci nějakých jasně daných kategorií textů, které jsou specifikovány základními strukturními atributy.
Vyhledávací formulář poskytuje zjednodušení ve formě dodatečného formuláře Omezit hledání, který je umístěn pod kontextovým hledáním a aktivuje se podobně jako (výše popsaná) specifikace kontextu kliknutím.
V rámci tohoto formuláře je možné zaškrtnout ty hodnoty vybraných strukturních atributů, které nás zajímají. Formulář neobsahuje všechny strukturní atributy, pouze ty nejpoužívanější v daném korpusu (např. při hledání v SYN2020 jsou to txtype_group, txtype, genre, srclang). Použité zkratky je možné dohledat v příslušné sekci seznamů.
V jednom ze sloupců se objevuje seznam konkrétních textů (opusů nebo dokumentů), které odpovídají specifikované podmínce. V případě, že si z nabídky zvolíme nějaké kategorie, můžeme si zobrazit soupis textů, které takovéto podmínce odpovídají, pomocí tlačítka Zúžit výběr (pokud odpovídající seznam textů není příliš dlouhý). Sloupec se seznamem textů se přepočítá podle aktuálně zaškrtnutých kritérií. Takto můžeme pokračovat do té doby, než budeme spokojeni s vymezením dat, která k hledání chceme použít. Lze se přitom vracet (volba Krok zpět), případně celý výběr stornovat (volba Zrušit výběr). Daný výběr je také možné uložit pro pozdější využití (volba Uložit jako koncept subkorpus) a vytvořit tak nový virtuální subkorpus. Mimoto lze snadno získat seznam dokumentů v aktuálním výběru (volba Uložit seznam dokumentů), což může být praktické, např. chcete-li zjistit, která beletristická díla figurují v paralelním korpusu InterCorp pro ten který jazyk.
Pro podrobnější specifikaci je třeba použít podmínku within v rámci CQL dotazu.
Paradigmatický dotaz
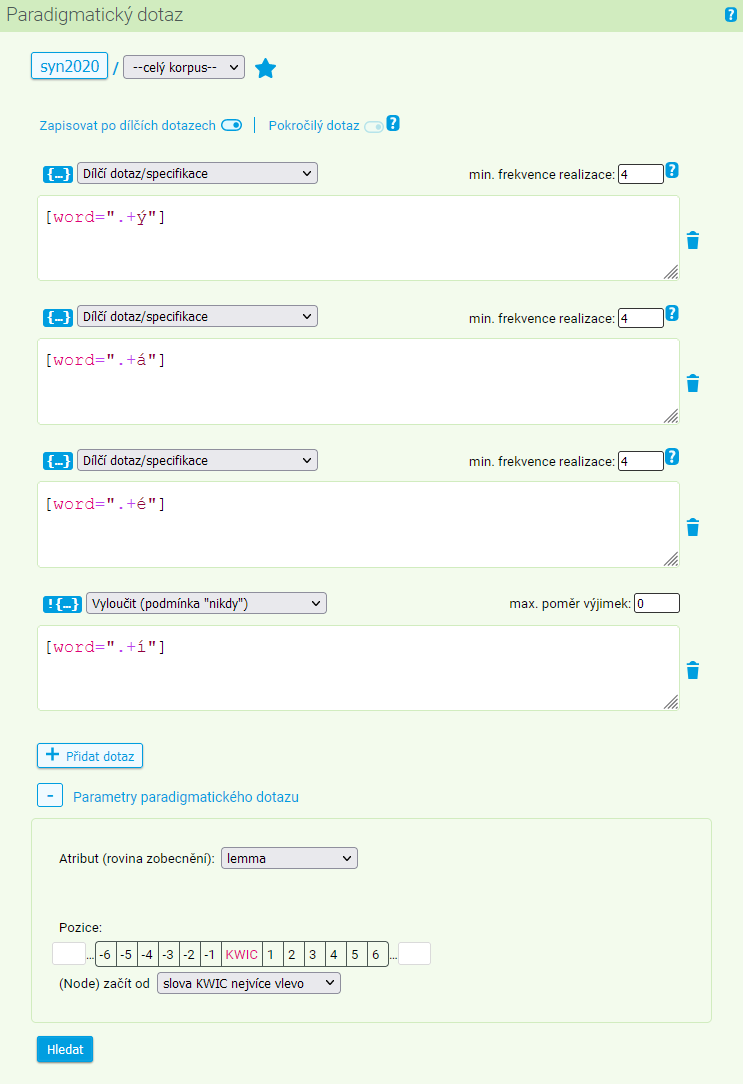
Vedle výše popsaného syntagmatického dotazu (hledáme množinu tokenů tvořících KWIC, které zobrazíme spolu s okolním kontextem v podobě konkordance) lze využít rovněž hledání paradigmatické, jež je vlastně kombinací několika dílčích syntagmatických dotazů a přináší průnik jejich frekvenčních distribucí. Výsledkem paradigmatického dotazování je tak množina typů, které odpovídají všem jednotlivým syntagmatickým dotazům.
V dotazovacím formuláři zadáváme dílčí syntagmatické dotazy do jednotlivých okének, příp. lze další okénka přidat pomocí tlačítka vespod či ubrat kliknutím na ikonku koše vpravo. Dále můžeme specifikovat parametry jako výchozí atribut, minimální frekvenci jednotlivých dílčích syntagmatických dotazů a pozici, na níž bude u každého z nich uplatňována frekvenční distribuce.
Výsledný soupis jednotek splňujících všechny dílčí dotazy (jedná se o průnik dílčích dotazů) je defaultně seřazen podle posledního sloupce (celková absolutní frekvence), kliknutím na libovolné záhlaví sloupce (absolutní frekvence jednotlivých dotazů) lze řazení změnit. Horizontální pořadí partikulárních frekvencí je naznačeno barevným kódováním.
Příklad:
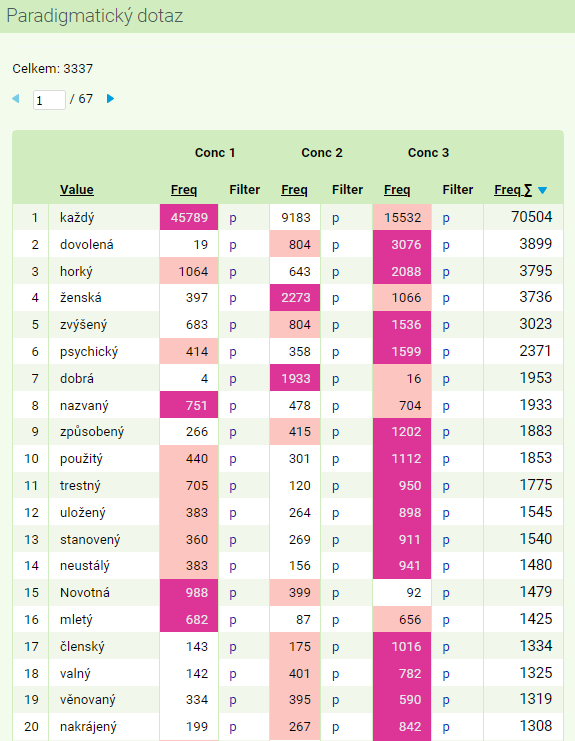
Dotaz, jenž hledá v korpusu SYN2020 všechna lemmata, která v jedné ze svých realizací končí na -ý, v jiném výskytu na -á a ještě v jiné realizaci na -é, vymezuje (ne zcela přesně) skupinu slov se složeným (adjektivním) skloňováním typu mladý, která mají v korpusu doloženy tvary pro nom. sg. mužského, ženského i středního rodu (mladý, mladá i mladé). Jednotlivé dílčí syntagmatické dotazy můžou mít tuto podobu (paradigmatický dotaz lze zadávat pouze pomocí CQL):
[word=".+ý"][word=".+á"][word=".+é"]
Atribut výsledku (rovina zobecnění): lemma
Minimální frekvence realizace: 4
Ve výsledcích najdeme adjektiva jako nový, celý, velký, dále zájmena a číslovky s adjektivním skloňováním každý, druhý, který, ale také slova s jiným skloňováním, která vykazují formální podobnost se zadaným dotazem, např. svůj (do jehož paradigmatu patří mj. tvary svý, svá, své). Nenajdou se naopak lemmata, která jeden z tvarů doložen nemají (např. šestatřicetiletý nemá doložen tvar šestatřicetileté, resp. má ho v korpusu doložen pouze třikrát, což je pod stanovenou mezí minimální frekvence).
Podmínka nikdy a vždy
Paradigmatické dotazy lze dále specifikovat podle podmínek nikdy (Vyloučit) a vždy (Omezit hledání na), jejichž výběr lze provést pomocí roletového menu nad každým dílčím dotazem.
Podmínka nikdy umožňuje vyloučit případy nalezené ve specifikovaném dílčím dotazu. Pokud bychom k výše uvedenému příkladu přidali čtvrtý dílčí dotaz se se specifikací, že jde o podmínku nikdy, v podobě
4. [word=".+í"]
najdeme pouze taková lemmata s adjektivní deklinací, která nemají tvar odpovídající nom. pl.: např. každý, celkový, dostatečný, u nichž nejsou doloženy s nadlimitní frekvencí podoby *každí, *celkoví a *dostateční.
Podmínka vždy vymezuje nadmnožinu typů, z nichž se vyberou pouze ty, které jsou plně určeny dílčími dotazy, tj. nemají výskyty mimo tyto dotazy a mimo specifikovanou nadmnožinu. Ve výsledku se tak nemohou vyskytovat typy, které mají realizace, nepostižené alespoň jedním dílčím dotazem. Pokud k příkladu výše přidáme čtvrtou podmínku se specifikací Omezit hledání na (podmínka „vždy“) a hodnotou
4. [lemma=".+ý"]
najdeme pouze taková lemmata končící na -ý, která jsou v úplnosti určena podmínkami 1-3, tzn. nemají žádné jiné realizace, které by těmito dílčími dotazy zůstávaly nepostiženy. Tomu odpovídá lemma odmaštěný, které se v SYN2020 vyskytuje pouze v podobách odmaštěný, odmaštěná, odmaštěné a všechny mají alespoň čtyři výskyty.
Podmínky vždy i nikdy můžeme aplikovat striktně nebo lze jejich působení zmírnit uvedením maximálního procenta výjimek ve výsledku (pole max. poměr výjimek nad dotazovacím řádkem). Hledáme-li např. slova, která se nikdy nevyskytují v imperativu, můžeme zvýšením podílu výjimek na 1 % (údaj je potřeba vepsat ve formě 0.01) do výsledku zařadit i slovesa, v nichž je imperativ zastoupen maximálně jedním procentem jeho tvarů.
Seznam slov
Základním výstupem jakéhokoli dotazu je konkordance, tj. seznam všech výskytů (tokenů) odpovídajících dotazu spolu s jejich textovým okolím. Funkce Seznam slov naproti tomu vyhodnocuje dotaz tak, že výsledkem je seznam různých slov (typů), které dotazu odpovídají, spolu s jejich absolutní frekvencí, ARF nebo počtem dokumentů, v němž se hledaný jev vyskytuje. Funkce Seznam slov je tak analogická frekvenční distribuci, její výhodou je však rychlost a výpočetní nenáročnost, protože mezikrok přes konkordanci tu není potřeba.
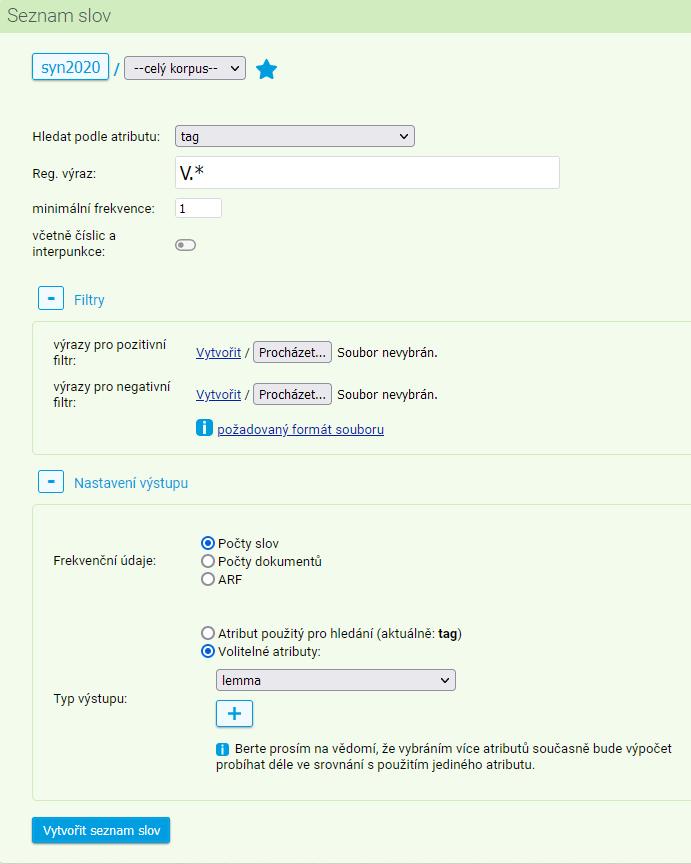
Ve formuláři je možné nastavit různé parametry hledání:
- korpus (příp. jeho subkorpus), ve kterém budeme seznam slov vytvářet
- atribut (poziční nebo strukturní), který má být v seznamu vypsán
- regulární výraz, kterému mají výsledná slova odpovídat (není-li zadán, seznam bude obsahovat všechny položky v korpusu, pokud odpovídají ostatním specifikacím ve formuláři)
- minimální frekvence
- včetně číslic a interpunkce – volba rozšiřující hledání i na slova, která nejsou složena pouze z alfabetických znaků
- výrazy pro pozitivní filtr – soubor1) se seznamem předvybraných slov, která ve výsledném seznamu chceme vidět (tzv. whitelist)
- výrazy pro negativní filtr – soubor2) se seznamem předvybraných slov, která z výsledného seznamu chceme vyloučit (tzv. blacklist)
Mezi nastaveními druhu výstupu najdeme kromě volby mezi absolutní frekvencí, ARF a počtem dokumentů také volbu konkrétního výstupního atributu či atributů. Tyto atributy přitom nemusejí být shodné s pozičním atributem zvoleným v horní části formuláře, na který jsou aplikovány všechny výše uvedené filtry. To umožňuje vytvořit např. frekvenční seznam všech sloves tak, že v horní části zadáme atribut tag, na něj podmínku na sloveso jako V.*, a zvolíme typ výstupu lemma – příklad takového zadání ukazuje obrázek.
Pokud je specifikace seznamu slov obecná a/nebo zvolený korpus rozsáhlý, může vyhodnocení této funkce trvat i několik minut.
Analýza klíčových slov
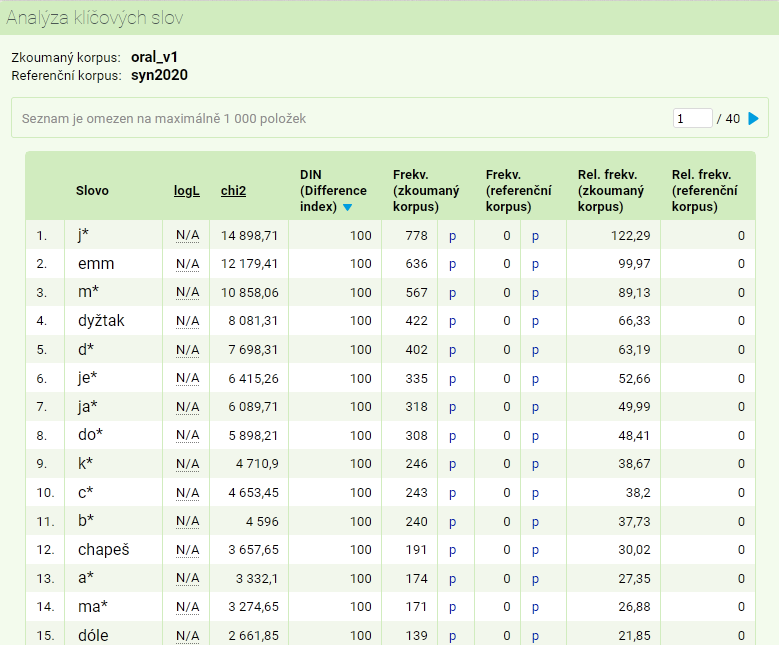
Rozhraní KonText dokáže vygenerovat soupis tzv. klíčových slov (keywords), tedy takových tvarů či lemmat, která se ve vybraném (sub)korpusu objevují nápadně častěji než v (sub)korpusu referenčním, odrážejícím běžný jazykový úzus. (Analýzu klíčových slov ve vlastních textech umožňuje specializovaná aplikace KWords.)
Vedle korpusu, v němž chceme dané výrazy najít, musíme zadat také referenční korpus (příp. též subkorpus, např. chceme-li nějaký korpus tvořený převážně publicistickými texty, tj. korpusy řady SYN, konfrontovat se subkorpusem beletristických textů: SYN2020-BEL). Dále určíme, podle kterého pozičního atributu se výrazy mají vyhledávat, podle které metriky mají být tříděny (v nabídce jsou tři: Log-likelihood, Chi-square a Difference index), eventuálně zadáme i požadovanou minimální či maximální frekvenci. Hledané výrazy lze dále vyfiltrovat pomocí regulárního výrazu; defaultně nastavený výraz .* zobrazí všechny výsledky (resp. prvních 1000 výskytů).
Výsledný seznam klíčových slov ve formě tabulky je seřazen podle zvolené metriky, přičemž zbylé dvě se zobrazují taktéž, v dalších sloupcích následují hodnoty absolutní a relativní frekvence v obou korpusech. Soupis vyhledaných výrazů si lze zobrazit v obou korpusech v příslušné konkordanci přes pozitivní filtr (p vpravo od hodnoty absolutní frekvence).
Předchozí dotazy
Položka zobrazí přehled posledních kladených dotazů (zkrácený seznam dříve kladených dotazů je přístupný i přímo z dotazovacího formuláře prostřednictvím odkazu nad vstupním řádkem). Tyto dotazy lze filtrovat podle aktuálně používaného korpusu či podle typu dotazu a také lze zobrazit pouze dotazy archivované. Kliknutím na vybraný dotaz vložíme dříve specifikované zadání do dotazovacího formuláře a dotaz můžeme buď beze změny ihned vyhodnotit, nebo jej dále modifikovat (např. změnit korpus, na němž bude vyhodnocen, typ dotazu nebo specifikovat jeho kontext).
Kliknutí na ozubené kolo a následně na volbu Archivovat umožňuje dotaz pojmenovat a trvale jej uložit do archivu položených dotazů. Ukládá se přitom kompletní stav formuláře, tedy např. i vybrané typy textů.




