

Obsah
Menu: Filtr
Filtrování výsledku hledání (konkordance) slouží k zpřesnění původně položeného dotazu dodatečnou podmínkou. Obecně je možné říct, že jakýkoli filtr je možné nahradit složitějším CQL dotazem, nicméně v některých typech výzkumu je lepší postupovat od obecnějšího zadání postupným specifikováním výsledku, kterého chceme dosáhnout. Výhodou takové cesty je možnost průběžné kontroly toho, jaké výsledky se v konkordanci objevují.
Základními typy jsou filtry pozitivní a negativní specifikované dalším filtrujícím dotazem. Ve zvláštních případech se vyplatí použít připravený filtr odstranění vnořených shod a vyfiltrování prvních výskytů v dokumentech nebo ve větách.
Pozitivní filtr a negativní filtr
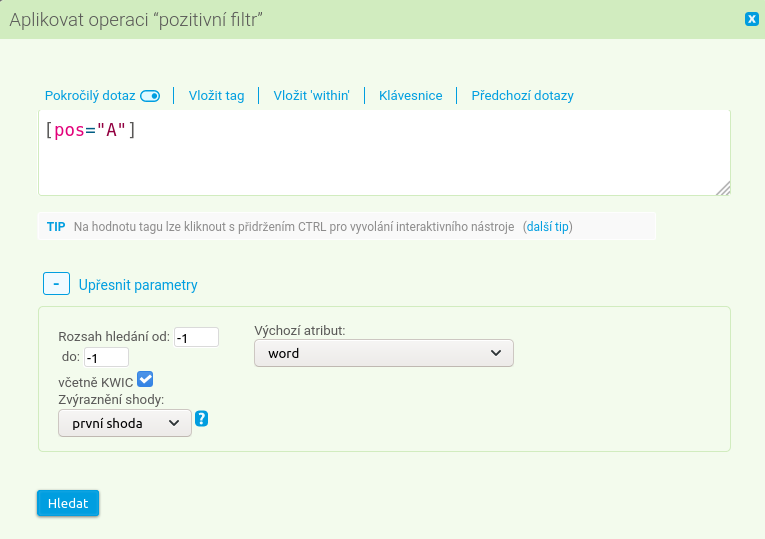
V rozhraní KonText máte na výběr ze dvou základních typů filtrování. Vyvolávají se přes položku Filtr > Pozitivní… a Filtr > Negativní… anebo stisknutím klávesy F:
- P-filtr (pozitivní filtr)
- N-filtr (negativní filtr)
Zatímco pozitivní filtr slouží k výběru podmnožiny konkordancí z výchozího seznamu, negativní filtr umožňuje některé nehodící se konkordance ze seznamu vyřadit. V případě P-filtru tak uživatel specifikuje podmínku, jejíž splnění podmiňuje ponechání řádku v konkordančním seznamu. N-filtr na základě uživatelovy specifikace naopak identifikuje ty konkordance, které je třeba z výsledku vyřadit (to, co odpovídá podmínce, je vyloučeno).
Nastavení filtru
V rámci formuláře je třeba vybrat nastavení specifikující podmínku (ta je ve své podstatě dalším dotazem aplikovaným na výsledky původního hledání), zejména formulovat samotný filtrující dotaz (ať už jednoduchý, nebo pokročilý) a následně ve zvláštním oddílu formuláře upravit upřesňující parametry:
- Rozsah hledání, tj. rozsah kontextu, v němž se filtrovaný jev bude hledat; implicitně je nastaven na hledání v okolí pěti tokenů nalevo i napravo od KWICu (-5 5) včetně KWIC. Pokud chceme filtr omezit například jen na KWIC, změníme rozsah na nulový (0 0) včetně KWIC.
- Další parametry jsou stejné jako u úvodního dotazu: výchozí poziční atribut, který je při filtrování implicitně nastaven jako
word; v režimu jednoduchého dotazu je to dále zohlednění velikosti písmen (case-sensitivity) a také povolení použití regulárních výrazů.
- Volba Zvýraznění shody (s hodnotami první shoda, poslední shoda) má smysl pouze při pozitivním filtrování:
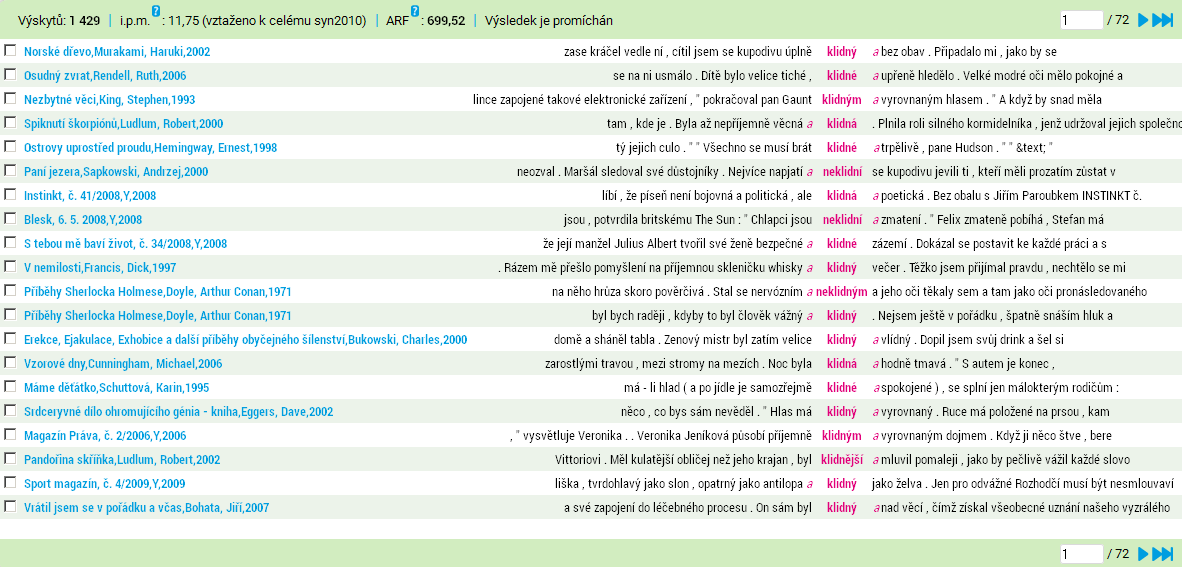
Zvýraznění shody
Nastavení specifikuje, které z kontextových slov má být označeno jako kookurence ke KWICu v případě, že se v jeho okolí nachází takových slov víc. Představme si, že při hledání lemmatu klidný najdeme i větu:
Stal se nervózním a neklidným a jeho oči těkaly.
Budeme-li chtít vyfiltrovat pouze ty konkordance, kde se v bezprostředním okolí lemmatu klidný objevuje spojka a, budeme mít v tomto případě dvě možnosti: buď jako kookurenci označíme předcházející spojku, nebo spojku následující za KWICem. Pokud v nastavení filtru zvolíme první shoda vybraný token, bude označen v hledaném kontextovém rozsahu ten nejvíce nalevo, v případě volby poslední shoda bude označen ten nejvíce napravo.
Vyhodnocení filtru
Vyhodnocení filtru automaticky přesměruje uživatele na stránku s aktualizovanou konkordancí. V případě negativního filtru jsou specifikované případy z konkordance vymazány (čímž se sníží počet konkordančních řádků). V případě filtru pozitivního jsou ve výsledné konkordanci pouze vyhovující řádky, celková frekvence je rovněž adekvátně snížena, kookurence v kontextu (jsou-li nějaké) jsou vyznačeny červenou barvou.
Odstranění vnořených shod
Volbu Filtr > Odstranit vnořené shody se vyplatí použít v případě, kdy výsledkům dotazu odpovídají různě dlouhé řetězce (struktury) KWICů, z nichž některé jsou do sebe vnořeny. V takovém případě zůstane po odstranění vnořených shod zobrazena pouze struktura vnější, tj. nejdelší možný řetězec KWICů.
Například budeme chtít vyhledat doklady citoslovečného výrazu hip hurá, v němž se první slovo může libovolně opakovat. Zvolíme pokročilý dotaz [lc="hip"]+ [lc="hurá"], v němž se nerozlišuje velikost písmen. Výsledkem budou jak konkordance s jedním výskytem slova hip, tak s jeho více výskyty. V případě více výskytů slova hip se však mezi výsledky zároveň objeví i konkordance s jeho nižším počtem výskytů:
Položil jsem sluchátko a zařval jsem Hip hip hurá !
Položil jsem sluchátko a zařval jsem Hip hip hurá !
Po aplikaci filtru zůstane zobrazena pouze konkordance s vyznačeným KWICem Hip hip hurá, tj. vnější struktura s opakováním řetězce hip.
Odstranění vnořených shod je důležité zvláště tehdy, když potřebujeme s výsledky dále statisticky pracovat.
První nálezy v dokumentech a ve větách
Volby Filtr > První nálezy v dokumentech a Filtr > První nálezy ve větách mohou mít částečně podobné využití jako odstranění vnořených shod, ale princip je odlišný.
Tyto filtry použijeme v případě, kdy se uvnitř určitého dokumentu nebo věty vyskytuje více výsledků pro zadaný dotaz, ale nás v nich zajímá pouze jeden (vždy se zobrazí ten první) doklad. Výsledky přitom oproti vnořeným shodám nemusejí být do sebe vnořené.
První nálezy v dokumentech
Volbu první nálezy v dokumentech můžeme například použít v případě, kdy se ve výsledcích objevují konkordance převážně z jednoho nebo jen z několika zdrojů, ale nás zajímají i další užití tohoto slova, která mezi převažujícími konkordancemi zanikají.
Například lemma hnojník má v SYN2020 celkem 111 dokladů, ale celých 79 dokladů je obsaženo jen v jednom dokumentu (Encyklopedie léčivých hub). Slovo hnojník přitom představuje homonymum, které vedle houby může znamenat i skladiště hnoje nebo brouka. Tyto doklady na stránce konkordancí zanikají. Při zobrazení jen prvních nálezů v dokumentech doklady na ostatní významy objevíme snáz. Tato funkce tedy může sloužit jako nástroj pro vytváření zvláštního systematického vzorku (oproti vytváření vzorku náhodného).
První nálezy ve větách
Filtrování pomocí prvních nálezů ve větách použijeme v případě, kdy se výsledky hledání opakují uvnitř jedné věty, ale nás opět zajímá pouze jeden (vždy se opět zobrazí ten první) doklad.
Může jít například o hledání víceslovných spojení pomocí atributu col_lemma, který je k dispozici ve verzovaných korpusech SYN, např. v syn_v11.
Zadáme-li dotaz [col_lemma="bát_se_jako_čert_kříže"], dostaneme mj. těchto pět výsledků:
Jak ji znám , bojí se hospod jako čert kříže !
Jak ji znám , bojí se hospod jako čert kříže !
Jak ji znám , bojí se hospod jako čert kříže !
Jak ji znám , bojí se hospod jako čert kříže !
Jak ji znám , bojí se hospod jako čert kříže !
Totožnou hodnotou atributu col_lemma jsou totiž postupně označeny všechny části daného víceslovného spojení. Po použití filtru se pak už zobrazí jen první doklad, tedy jedna konkordance pro jedno víceslovné spojení (frazém bát se jako čert kříže), pouze s prvním slovem zvýrazněným jako KWIC.
Jak bylo uvedeno na začátku této kapitoly, k podobným výsledkům se lze často dostat různými způsoby. Každá automaticky anotovaná kolokace má zároveň jednoho ze svých členů označeného pomocí dvoumístného pozičního atributu col_type s písmenem H na druhé pozici. Na výše uvedené výsledky bychom tedy mohli uplatnit pozitivní filtr na pozici KWIC s hodnotou [col_type=".H"] nebo bychom úvodní dotaz také mohli přímo formulovat jako [col_lemma="bát_se_jako_čert_kříže" & col_type=".H"] V takovém případě se vždy zobrazí pouze doklad s vyznačeným tvarem kříže, protože jeho hodnota atributu col_type je rovna PH.




