

Table of Contents
Menu: Query
The primary querying method in the corpus is a syntagmatic query, which results in a concordance, i.e. a list of all occurrences (tokens) corresponding to the query together with their immediate context. For a syntagmatic query, use the Query → Concordance option.
An extension of syntagmatic search is the paradigmatic query, which is a combination of several individual syntagmatic sub-queries and yields the intersection of their frequency distributions. Thus, the result of paradigmatic querying is the set of types common to all individual syntagmatic queries. For a paradigmatic query, use the Query → Paradigmatic query option.
Another additional function allows to produce a list of the different words (types) that match the query, along with their absolute frequency, ARF or the number of documents in which the query occurs. To obtain such a list, use the Query → Word list option.
Concordance
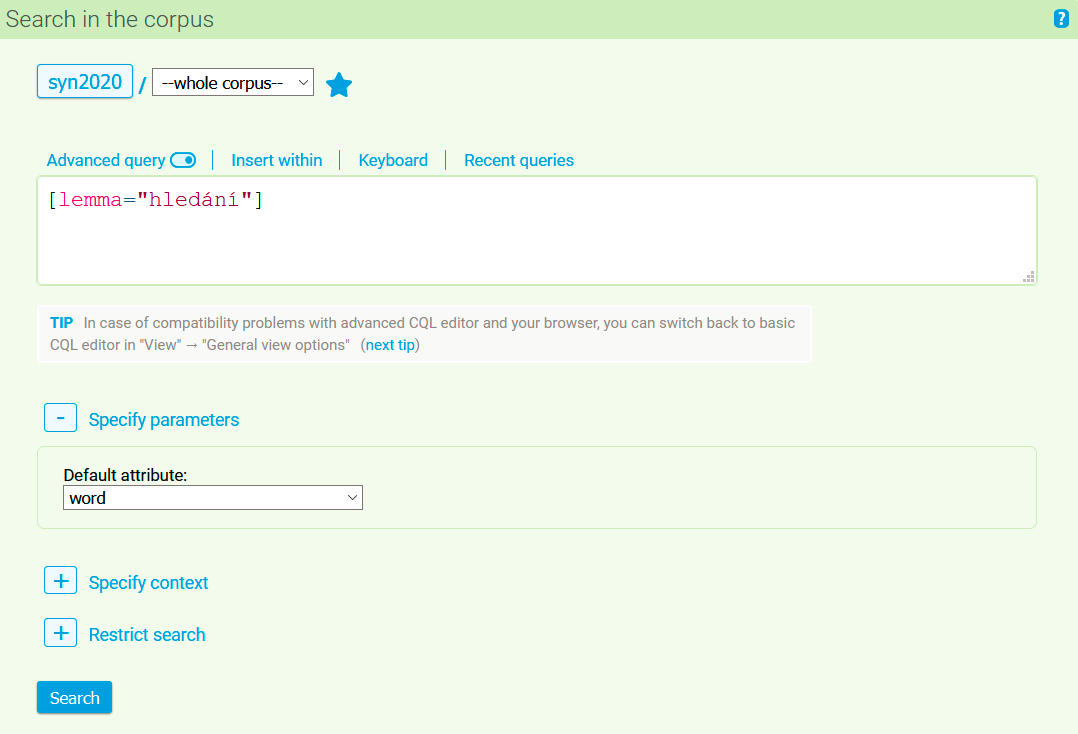
With the selection Query → Concordance, it is always possible to begin a new corpus search. By clicking on this option we abandon our previous query and any results produced with it, and we begin with a new search. The following text primarily deals with creating queries in single language corpora; the specifics of searching the parallel corpora InterCorp are described in detail in the bonus tutorial of the basic course on working with the CNC (Czech National Corpus).
After clicking on the item Concordance, a basic search menu appears for the user. Within this form it is possible to select a corpus in which the search will be conducted and enter a query in the input line below it. You can use the switch to activate the Advanced query function which works with the Corpus Query Language. The form also includes an interactive international keyboard for entering special characters (especially when searching in non-Czech texts and when inserting special characters of the CQL). Previously asked questions can be found either directly in the menu or using the Recent queries link above the query line. The last item in the toolbar above the line is Query interpretation, where the user finds out how his/her query will be evaluated (i.e. translated into CQL) and whether this interpretation is in accordance with his/her intention. This function is not available when switching to advanced mode, but instead it is possible to directly insert interactively generated morphological tags (for corpora that are tagged in this way) or within conditions (see items Insert tag and Insert within).
Corpus selection
The selection of a corpus suitable for solving the given research question is an important decision which must be made before taking any other steps in the research. The range of corpora made available through the project of the Czech National Corpus is constantly widening, as can be seen on the list of corpora. It has therefore been necessary to adjust the corpus selection on the KonText interface in order to accommodate their growing number. Until the autumn of 2015, the corpus selection had the shape of a hierarchically organized tree; this system had several disadvantages: from the not always definite placement of the given corpus within the hierarchy, to a great increase in the number of new corpora and their versions. As a result of this, the hierarchical organization stopped being clear and sustainable in the future, which is why we have switched to the new, label-based system. Its aim is primarily to facilitate orientation in the large number of existing corpora, while simultaneously simplifying work for those users who use only a small number of favorite corpora.
After clicking on the name of the corpus (in the default setting it is always the most recent representative corpus of synchronic written Czech, currently SYN2010) a frame for the selection of a corpus appears, containing two main sections:
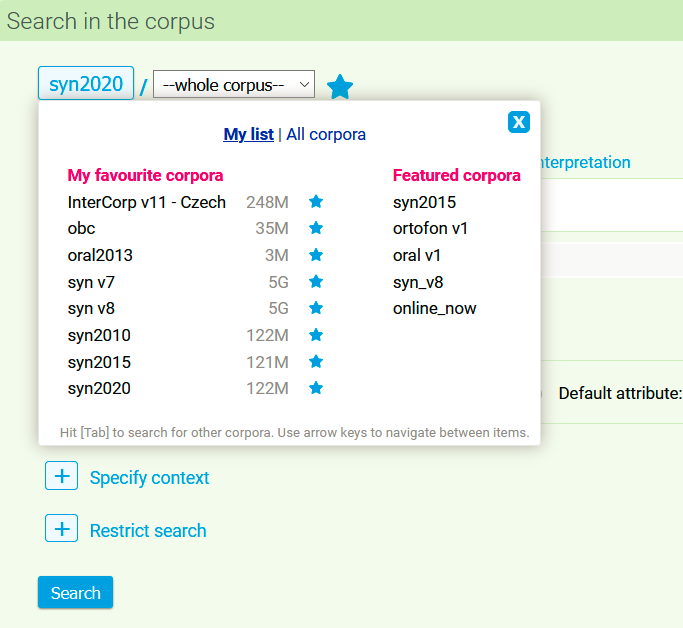
- My list with a quick, single click selection of corpora. This quick selection contains favourite corpora, which can be selected by the user, and also the so-called featured corpora: a default list of several corpora, which the CNC considers to be particularly important in the individual areas of production. Having them all in one place simplifies the selection of a corpus especially for beginning users of the CNC. Favourite corpora can be selected either on the page with all the available corpora, or when working with them at the time of query input (such corpora are labelled with a yellow star).
- All corpora with the possibility of searching all available corpora with the aid of so-called labels, which are used to characterize the corpora (a typical corpus has several labels, e.g. SYN2010: written, synchronic, Czech, SYN family, representative). For example, if you are looking for a web corpus of Czech, all you have to do is select the labels “Czech” + “web”, and all the relevant corpora made available by the CNC will appear. The search may be further refined by typing part of the corpus name or its description into the search bar, and the resulting list of corpora is interactively filtered based on the keywords. However, it must be noted that for spatial reasons the list only shows the first 25 items; if the list is too long, the query must be specified further with the addition of another label, or by searching for a part of its name.
Example: The user searches in the All corpora tab for a current version of the English section of the parallel corpus InterCorp. He first selects the labels “InterCorp” a “current version ”, the first 25 corpora which conform to the specified conditions appear on the list, although InterCorp contains many more languages. The corpora not displayed can be accessed with the help of further filtering, for example by typing part of the corpus name or language (please note that the names of the individual InterCorp versions are in English). After finding the desired corpus and clicking on it, the corpus becomes the current corpus for searching, and it is at the same time possible to mark it as favourite with a star. The corpus is added to the list of favourite corpora and can be accessed quickly and easily with a single click.
Query types
There are two query types in the current version of KonText: simple a advanced.
Previous versions of KonText worked with six query types: basic, lemma, phrase, word form, character, and CQL. The current simple query covers the first five query types, as their functionality can be achieved by altering the simple query settings, e.g. the default attribute and/or regular expressions (see below). The current advanced query fully corresponds to the CQL query type.
The default setting is the simple query with case-insensitive matching (the Match case switch is off), without regular expressions (the Allow regular expressions switch is off) and with the default attribute set to lemma|word (lemma|sublemma|word in SYN2020). The latter setting denotes searching not only for the input word form (given by the word attribute), but also other word forms subsumed under lemma or sublemma, provided the input word can also be interpreted as a lemma or sublemma (remark: this is exactly the behaviour of the basic query of the previous versions of KonText, that has only been extended to sublemma). Apart from the individual words, it is also possible to input multi-word phrases. The search can be further specified either by using the add-on for suggesting variants (SYN2020 only, see next section), or by changing the default attribute, and/or toggling the case-sensitivity switch. Furthermore, regular expressions can be used in the simple query mode after toggling the Allow regular expressions switch.
Advanced query mode is activated by a switch above the input line. This mode fully corresponds to the CQL query mode of the previous versions of KonText. When entering a CQL query, KonText automatically checks and highlights the query syntax. If the syntax is not valid, it notifies the user and lets them edit the query. Since CQL is quite complex, the syntax checking may occasionally issue a warning also in case of a valid query.
Once the query has been entered, the search can be started either by clicking on the Search button, or by pressing the Enter key (provided the focus is on the input line).
Query evaluation
If the search is successful, the concordance list page is displayed. Its use is described in detail on the Concordance page.
Search suggestions
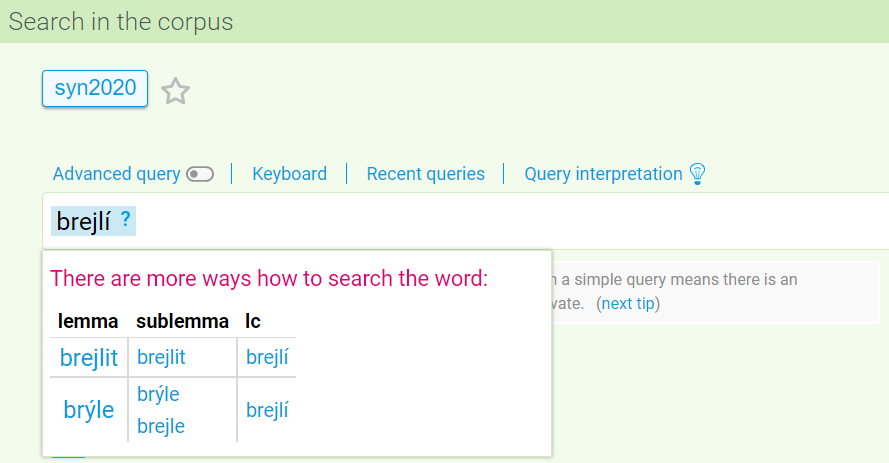
For corpora with two-level lemmatization (starting with SYN2020 and SYN version 9), KonText can suggest alternative ways of formulating a given query. Query terms with suggestions available are indicated by a blue background and a little question mark next to them. Ctrl/Command-clicking on such a term pops up a menu of lemmas, sublemmas and lc (case-insensitive forms), from which the most appropriate interpretation can be selected. After tweaking a query term in this way, its background changes to red and the Query interpretation option above the input line is highlighted.
For instance, when a user types in the form brejlí, KonText notifies them that this form is annotated as two different lemmas in SYN2020 (brejlit and brýle), and furthermore, it shows that lemma brýle includes two sublemmas, namely stylistic variants brýle and brejle. Thus, the user has the option to modify their query to search for either (i) all forms matching the lemma in the chosen row (by picking an option in the lemma column, e.g. brýle), or (ii) forms matching only a specific sublemma within the lemma (cf. the sublemma column, e.g. brejle), or (iii) only a concrete case-insensitive form within the lemma (cf. the lc column, e.g. brejlí under the brýle lemma). Similarly, KonText notifies the user if lemmas differ only in terms of case, e.g. Procházka (common surname) vs. procházka (a walk).
Specify parameters
As mentioned above, one can also specify additional parameters that influence the interpretation of a query. Apart from the default positional attribute, there are two more switches available in the simple query mode: case-sensitivity and allowing the use of regular expressions in a query.
Specify context
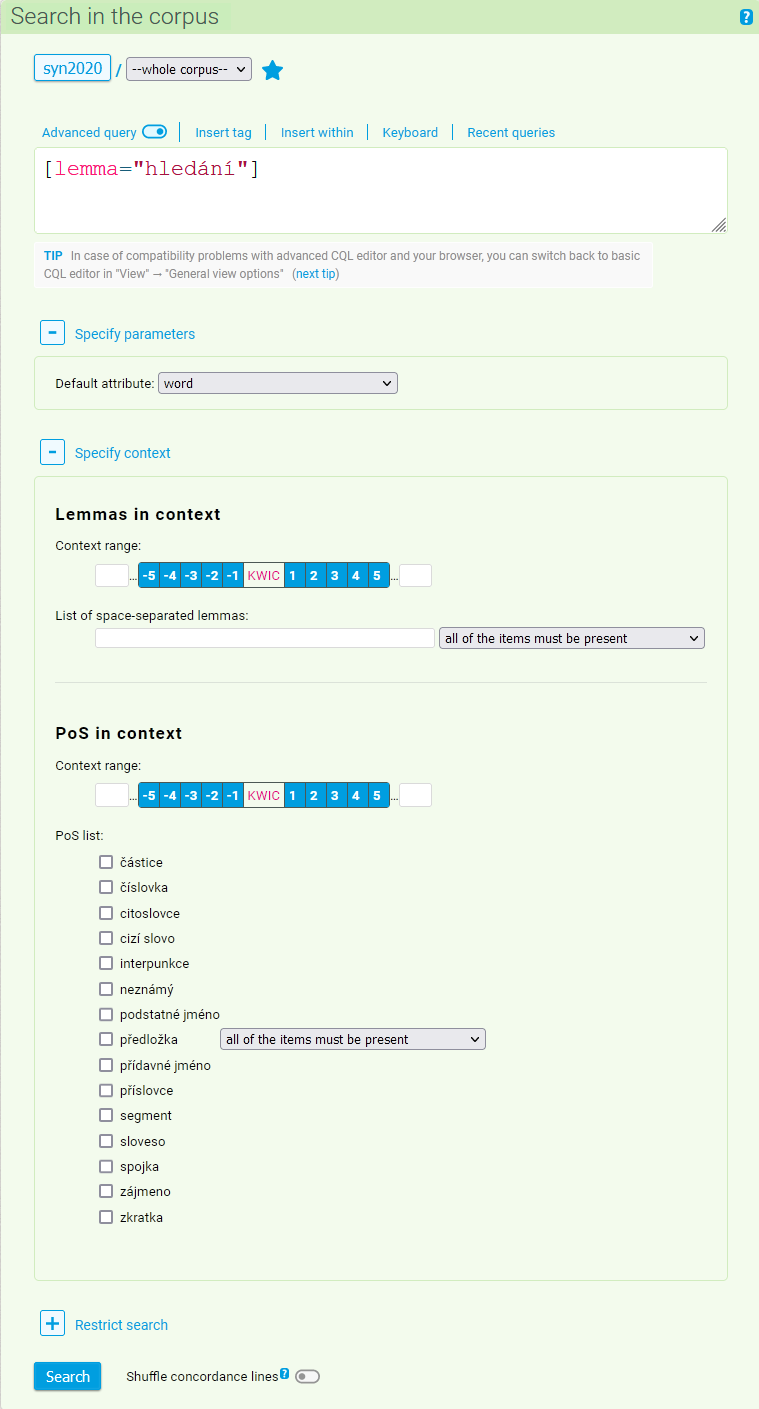
Every query can be further specified based on the context (the surrounding text) in which the search word or phrase can appear. The context menu, which is used for the specification of a query, can be found in the bottom section of the query form (it is hidden in the basic settings and it is necessary to activate it by clicking on Specify context).
Searching the context essentially means additionally filtering the basic concordance which is specified by the query already in the query form. The user can set the span of the context to which the additional filter condition will be applied, particular lemma(s), or word class(es).
In general, it can be said that any given search in context can be rewritten as an ordinary query which is then filtered (with the aid of positive and negative filters). Any filtering can also be carried out with the help of query language, performing the identical operation in a single step. The reality is that there are always more ways to achieve the same result, and it is entirely up to the user to decide which option he/she is most comfortable with.
Restrict search
We have two options if we need to search only in a narrowly defined group of texts in the entire corpus. Either we create our own virtual subcorpus, which we will then be able to select within the offered corpora, or we can restrict the query with several conditions (typically with the command within). As a rule, we choose the first option when we know that we will need the subcorpus for a longer time or when its specification is complex. We use the second option when conducting ad hoc searches within some clearly defined text categories specified with the help of the basic structural attributes.
The query form allows for simplification by way of an additional Restrict search tab located underneath the context search and activated with a click, similar to the (above-mentioned) context specification.
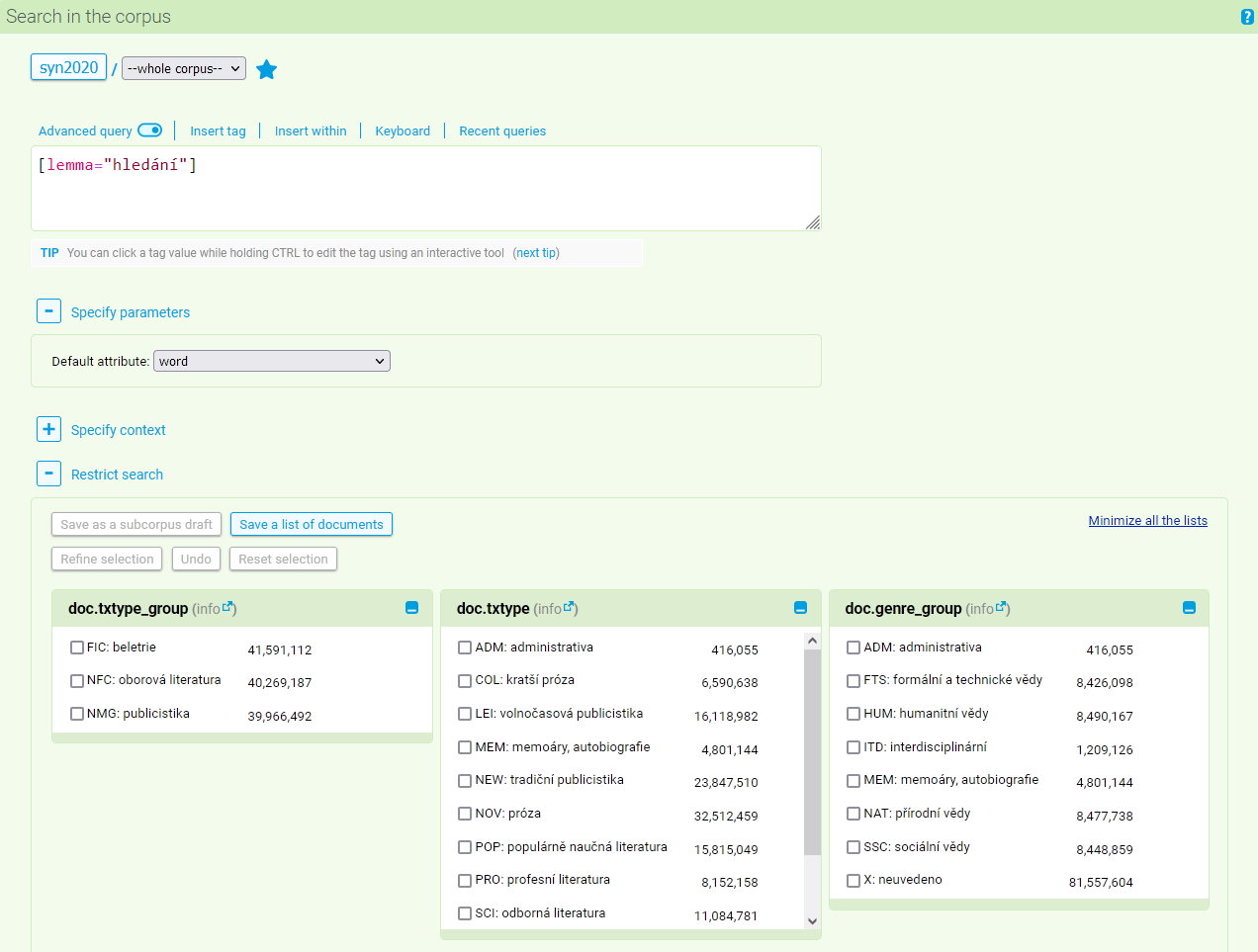
Within this form it is possible to mark off the values of selected structural attributes that interest us. The form does not contain all structural attributes, but only those most often used in the given corpus (e.g. when searching in the SYN2020 it is txtype_group, txtype, genre, srclang). The abbreviations used can be found in the lists section.
In the final column we can find a list of the specific opuses or documents (based on the selected corpus), which correspond to the specified condition. If such a list is too long, the given column contains only the number of items. If we select some categories from the menu, we can view an inventory of texts which meet the given conditions with the help of the button Refine selection. The column containing the list of texts is recalculated according to the currently marked criteria. We can continue this way until we are satisfied with the demarcation of the data we want to use for our search. It is possible to go back (option Undo) or cancel the entire selection (option Reset selection). The selection can also be saved for later use (option Save as a subcorpus draft), creating a new virtual subcorpus. Furthermore, a list of documents in the current selection can be easily retrieved (option Save a list of documents), which can be handy, e.g. if you want to find out which fiction books are in the parallel InterCorp corpus for a given language(s).
For a more detailed specification, it is necessary to use the condition within inside a CQL query.
Paradigmatic query
In addition to the syntagmatic query described above (where we search for the set of tokens matching a query and display them as KWICs in the form of a concordance), we can also use a paradigmatic query. This search actually combines several individual syntagmatic sub-queries and returns the intersection of their frequency distributions. The result of paradigmatic querying is thus the set of types that match all specified syntagmatic queries.
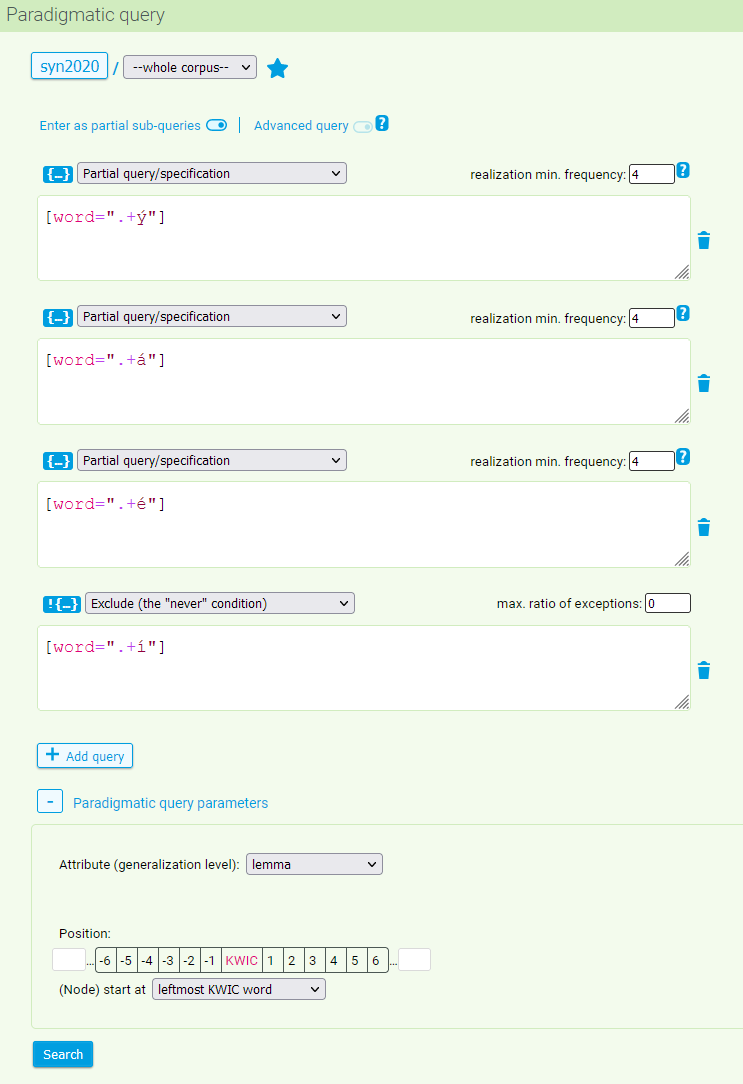
In the query form, partial syntagmatic sub-queries should be entered in separate boxes (additional boxes can be added using the + button at the bottom or removed by clicking on the trashcan icon on the right). One can also specify parameters such as the default attribute, the minimum frequency of each syntagmatic query, and the position at which the frequency distribution will be applied to each of them.
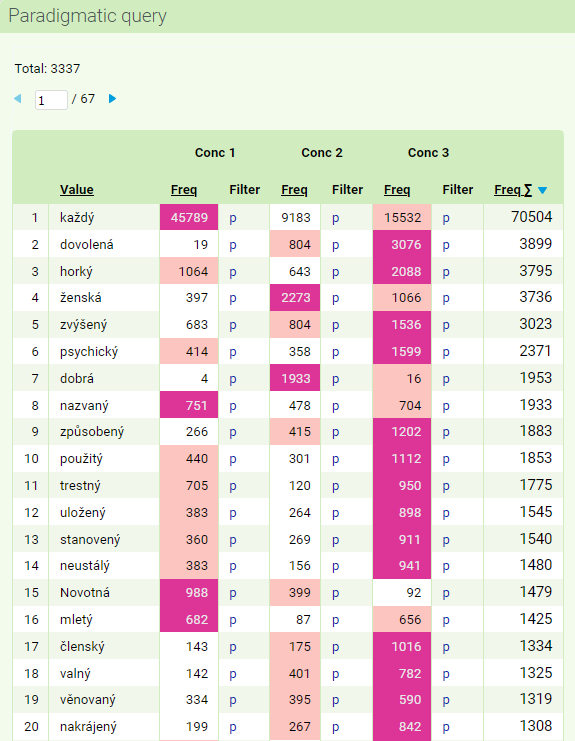
By default, the resulting inventory of words matching all queries (i.e. the intersection of individual sub-queries) is sorted by the last column (total absolute frequency). The sorting can be changed by clicking on any column header (absolute frequency of each query). The horizontal order of the partial frequencies is indicated by color coding.
Example
Searching the SYN2020 corpus for all lemmas whose forms sometimes end in -ý, sometimes in -á, and sometimes in -é, we can recover (albeit not 100% exactly) the group of adjectives inflected following the mladý paradigm (hard declension) whose nominative singular forms for all three genders (mladý, mladá, and mladé) can be found in the corpus. Partial syntagmatic sub-queries may look like this (these can only be entered using CQL):
[word=".+ý"][word=".+á"][word=".+é"]
Attribute (generalization level): lemma
Realization minimum frequency: 4
In the results, we find adjectives such as nový, celý, velký, pronouns and numerals with adjective declension každý, druhý, který, but also words with another declension type that only show formal similarity to the query, e.g. the pronoun svůj (whose paradigm includes, among others, the forms svý, svá, and své). On the other hand, we will not find lemmas for which one of the forms is missing or too sparsely documented in the corpus (e.g. šestatřicetiletý, as its form šestatřicetileté only occurs three times in SYN2020, which is below the minimum frequency limit).
The "never" and "always" conditions
Paradigmatic queries can be further refined using the conditions never (Exclude) and always (Restrict search to), which can be selected using the drop-down menu above each sub-query.
The never condition allows you to exclude cases matched by the specified sub-query. If we were to add a fourth sub-query to the above example with the specification that it is a “never” condition, namely:
4. [word=".+í"]
we will find only such lemmas with adjective declension that do not typically form the nominative plural, such as každý, celkový, dostatečný, for which the forms *každí, *celkoví a *dostateční are not attested with above-limit frequency.
The always condition defines a superset of types from which only those fully specified by the sub-queries (i.e., those having no occurrences outside of those queries and outside of the specified superset) are selected. Thus, the results cannot contain types that have realizations which are not matched by at least one sub-query. If we add a fourth condition to the example above with the specification Restrict search to (the “always” condition) and the value
4. [lemma=".+ý"]
we find only those lemmas ending in -ý that are entirely determined by conditions 1-3, i.e., they have no other realizations that remain unfound by these sub-queries. This corresponds to the lemma odmaštěný, which only occurs in SYN2020 in the forms odmaštěný, odmaštěná, odmaštěné, and all of them have at least four occurrences.
The “always” and “never” conditions can be applied strictly, or their effect can be mitigated by putting a maximum percentage of exceptions in the results (the field max. ratio of exceptions above the query box). For example, suppose we are looking for words that never occur in the imperative. By increasing the percentage of exceptions to 1% (the value needs to be entered in the form 0.01), we can include verbs in which the imperative is represented by at most one percent of their forms.
Word list
The basic output of any query is a concordance, i.e. a list of all the occurrences (tokens) matching the query, along with their text surroundings. The Word list function evaluates the query in such a way that the result is a list of various words (types), matching the query, together with their absolute frequency, ARF or number of documents in which the wanted phenomenon occurs. In this respect, the Word list function is analogous to frequency distribution, however its advantage is its speed and low computational complexity, because the extra step involving the concordance is not needed with the Word list.
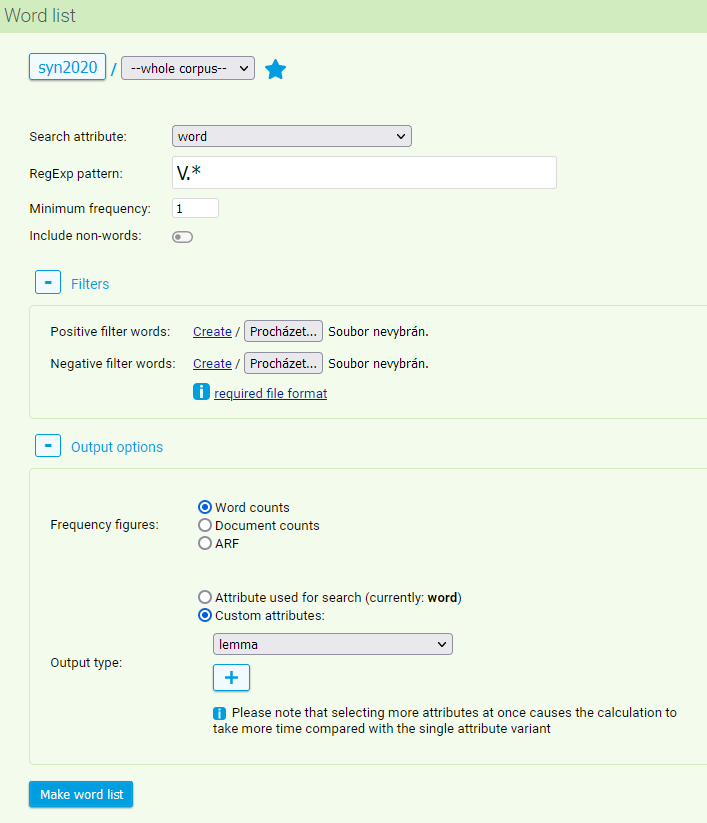
Various search parameters can be set in the form:
- corpus (or its subcorpus), in which the word list will be created
- attribute (positional or structural), which is to be included in the list
- RE pattern (regular expression), to which the resulting words must correspond (if it is not submitted, the list will contain all items in the corpus if they fulfill the other specifications in the form)
- minimum frequency
- option “Include non-words”, which widens the search to words which are not composed only of alphabetic characters
- whitelist – a list of pre-selected words (in a separate file) which we want to see in the resulting list
- blacklist – a list of pre-selected words (in a separate file) which we want to exclude from the resulting list
Among the output option settings we can find a selection of either the absolute frequency, ARF or a document count. Furthermore there is also the possibility to choose a specific output attribute (or attributes). These attributes need not be identical to the positional attribute selected in the top section of the form, on which all the above mentioned filters are applied. This enables us to create e.g. a frequency list of all verbs by selecting the attribute tag in the top section, applying the condition for a verb as in V.* and finally by “switching” the output type to lemma – an example of such a query is shown in the picture.
Keyword analysis
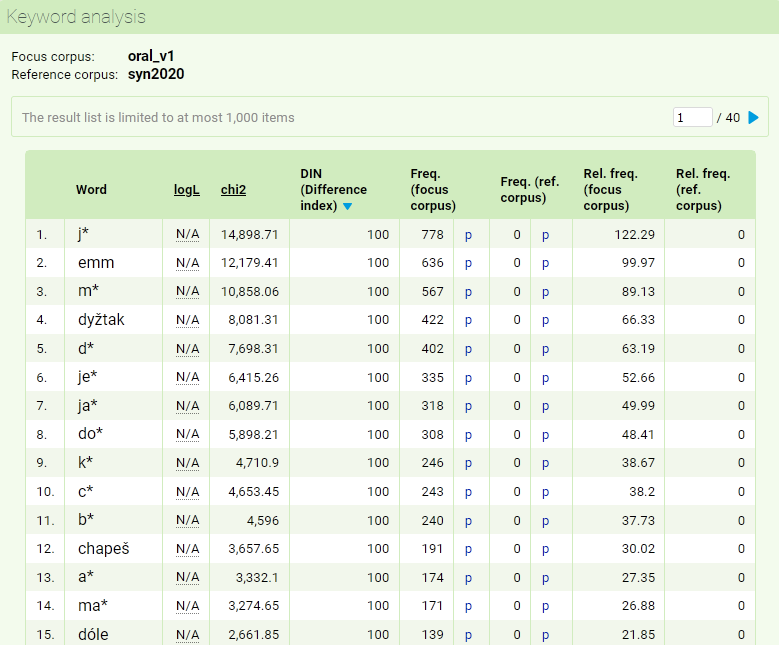
The KonText interface can generate an inventory of keywords, i.e., forms or lemmas appearing in the selected (sub)corpus significantly more often than in the reference (sub)corpus, reflecting common language usage. (The analysis of keywords in the users’ texts is enabled by the specialized KWords application.)
Besides the corpus in which we want to find the terms in question, we also have to specify a reference corpus (or a subcorpus, e.g. if we want to compare a corpus consisting mainly of journalistic texts, such as one of SYN corpora, with a subcorpus of fiction texts: SYN2020-BEL). Next, we specify by which positional attribute the terms should be searched, by which metric they should be sorted (Log-likelihood, Chi-square, or Difference index), and possibly we also specify the desired minimum or maximum frequency. Sought-after terms can further be filtered using a regular expression; the default .* expression will display all results (or, rather, the first 1000 occurrences).
The resulting list of keywords in the form of a table is sorted according to the selected metric, with the remaining two also displayed, followed in the next columns by the absolute and relative frequency values in both corpora. The list of found keywords can be viewed in both corpora in the respective concordance through the positive filter (p to the right of the absolute frequency value).
Recent queries
The item displays an overview of the most recent queries used (a simplified list of previous queries is also accessible directly from the query form, via a link above the input line). These queries can be filtered according to the query type or the currently used corpus, and only archived queries can be viewed as well. By clicking on the link Edit and search, we paste a previously specified constraints into the query form and we may either use it without any changes, or we may modify it further (e.g. change the corpus in which the query will be used, the query type, or we may specify the context).
By clicking on the gear and then on the Archive option, we can name the query and permanently save it to the query history archive for later reuse. The complete status of the query form is saved, e.g. also the selected text types.
Menu: Query • Corpora • Save • Concordance • Filter • Frequency • Collocation • View • Help




