

Table of Contents
Menu: Concordance
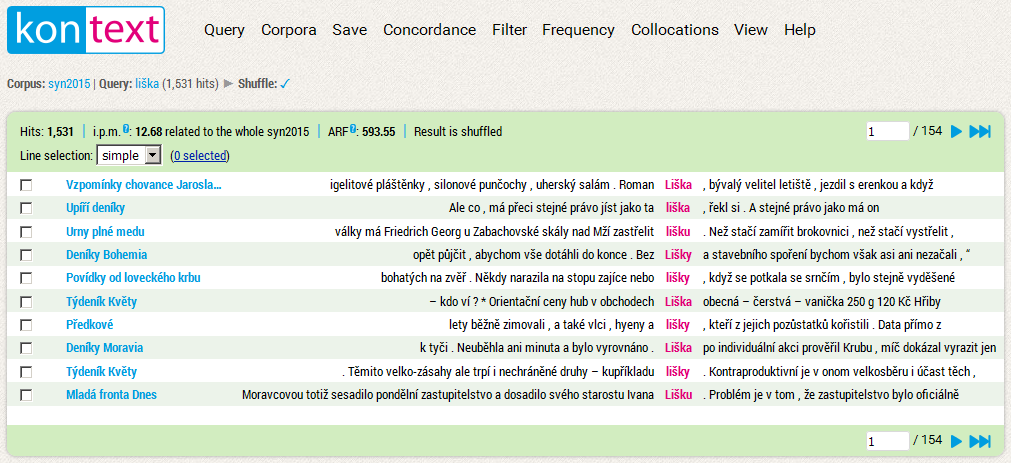
The basic kind of query is concordance, in particular, a concordance list. It is a list of all words or phrases which fit the (KWIC) query, along with their right and left contexts, possibly also with information about the source text. A long concordance list is usually divided into several pages, and it is possible to switch between them with the help of the arrows placed in the header and footer of the concordance list. Display parameter settings (the number of rows on a page, length of context etc.) can be changed using the View menu.
The following sections describe the functionality of the page, basic work with a concordance list, sorting, shuffling the list and creating a sample. Further work with the concordance (i.e. (filtering, frequency, and collocation analysis) is covered on separate pages corresponding to other menu items.
Navigation with concordance editing sequence
Under the KonText logo, a navigation overview provides basic information about the searched corpus (item Corpus) and allows modifying the initial query (item Query), as well as changing any subsequent actions performed on the concordance list (e.g. shuffling, filters etc.).
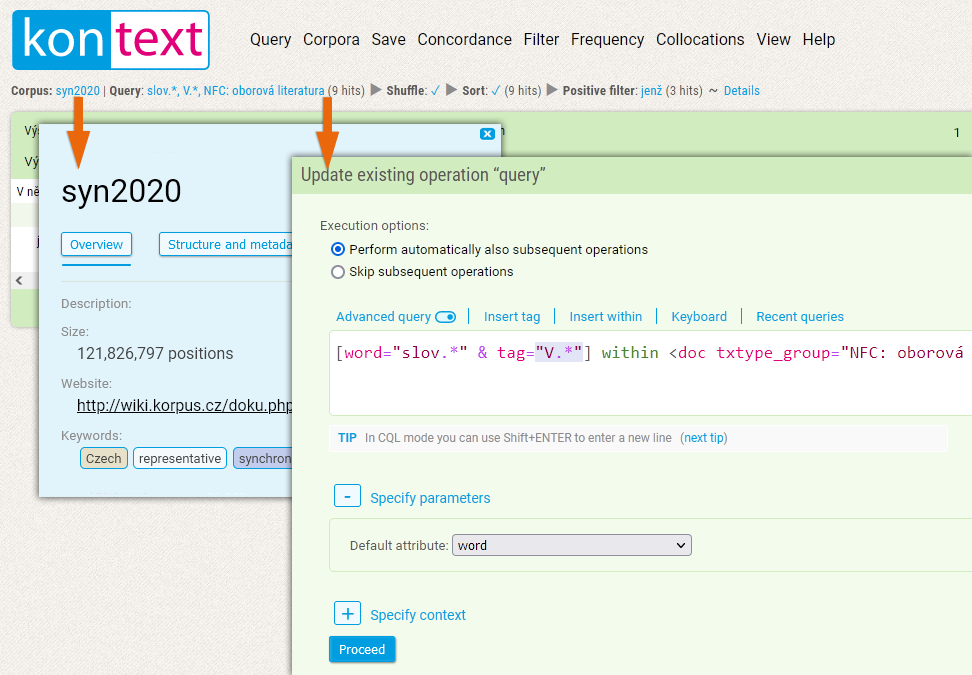
The text of the link in the Query item always shows a simplified representation of the query entered by the user, followed by the number of occurrences in parentheses. The query can be displayed and edited using the link, i.e. its parameters can be changed directly above the search results (without the need to enter a new query). This feature is especially useful if you want to refine or update the original query. When editing a query, you must also decide whether the following operations should be performed on the concordance. These include a useful shuffle option (this can be switched on directly in the query form or run later from the menu Concordance → Shuffle), so it is usually a good idea to leave the option Perform automatically also subsequent operations checked.
The subsequent navigation items represent the steps in the edit sequence that change the form and extent of the concordance. These can be manipulated in a similar way as the initial query.

The query overview with the sequence of all concordance modifications is also available in tabular form by clicking the last link, Details.
Besides editing the query, the user can also return to the form of the concordance from any of the previous steps and intermediate phases. E.g. we can easily return to the default concordance list (including shuffling) using the View link in the second row with the shuffle operation.
The query overview thus allows for an exact query specification for future use, e.g. in a research report, scientific paper etc. It is a more complex and more general variant of the web browser's simple built-in Undo button. While the Query overview allows you to browse and edit operations on a concordance, the Undo button allows you to browse (but only in a fixed order) both the concordance and, say, the frequency or collocation analysis results.
Working with concordances
Introduction
The concordance list is divided into several parts. Highlighted in the centre is the KWIC, which is surrounded by the left and right context. In the left-hand column, each row contains some brief information about the source text (its content depends on the settings in the View) menu. In the header of the concordance, we can find basic information such as absolute frequency, relative frequency (i.p.m.), ARF and concordance status (whether it is sorted or shuffled). Arrows for browsing the individual pages of the concordance are placed on the far right.
Further information about the text
More detailed information about the text from which the specific concordance line originates is displayed after clicking on the metainformation listed in colour on the left of each line. The detailed metainformation then appears in a window at the bottom of the concordance list, which contains all of the information about the given text and the structures in which the KWIC is found (see lists of abbreviations used).
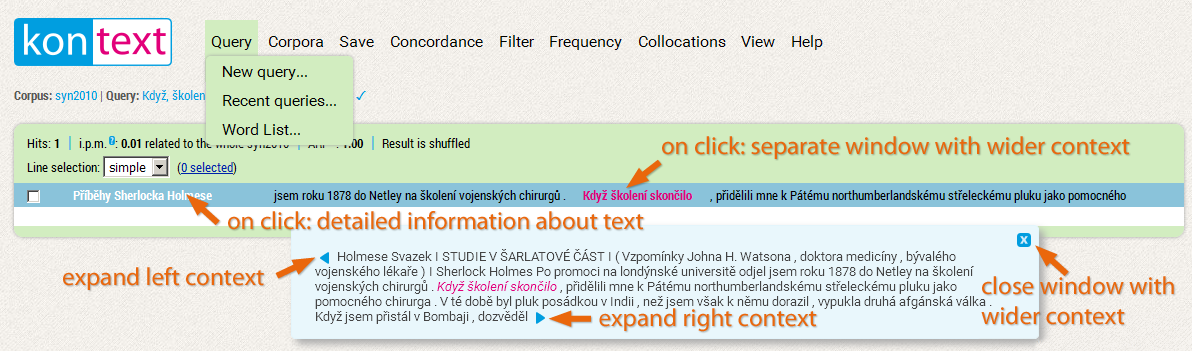
Display context of the KWIC
The context of the key word can be widened either for all concordance lines (see menu View → General view options, option KWIC Context size (positions)), or it is possible to view the wider context of only one concordance line in more detail in a separate window which appears after clicking on the KWIC. Here it is possible (to a limited degree) to widen the context with the help of the blue arrows at the beginning and at the end of the sample.
In newer written corpora (starting with SYN2020 and SYN verze9), it is possible to switch between two text display options: a default view corresponding to the tokenization of the corpus, or the formatted text view preserving to some extent also the typographic form of the source text (this can be used, for example, to display poetry more clearly).
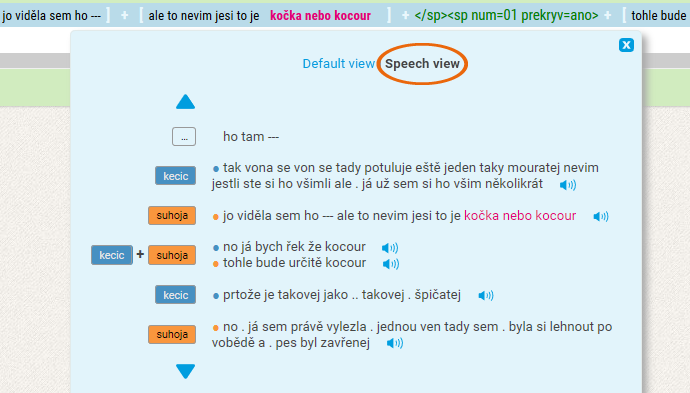
In spoken corpora, switching between two display options – linear display (as in written corpora) or display by individual speakers’ segments – is possible too. Obviously, the Speech view makes it easier to navigate through spoken language transcripts.
Syntactic graph
If the corpus is syntatically tagged (e.g. SYN2015), clicking the ![]() icon between the checkbox and the text meta-information will show the syntactic graph of the given sentence.
icon between the checkbox and the text meta-information will show the syntactic graph of the given sentence.
Manual labelling of concordance lines
At the far left of every line, we can also find a selection box for manual labelling of the individual concordance lines.

Labelling can be done in two modes:
- basic: selection of specific concordance lines with the option of either selecting or not selecting each specific item.
- groups: a general classification of concordance lines into groups (e.g. according to meaning) labelled by numbers which the user picks
During labelling in both modes, a link with the continuously updated number of selected lines appears in the header of the concordance list. The two modes differ in the options of further work with the labelled lines which are available after clicking on the link: while the basic selection only leads to the deletion or preservation of the given lines in the concordance, the options of working with groups are much wider. In this case, however, the first step required by KonText is to save the given group classification, which is necessary for maintaining persistence – after saving the URL changes so that it remains as an unambiguous indicator of the input query and also the classification. Following this, it is possible to view some basic statistics of the given groups, sort the concordance according to them, or also return to further editing of the group classification. Switching to the page with the first selected line at any time is convenient for large, multi-page concordances.
Items in the //Concordance// menu
Sorting
An easy way of finding one’s way around a large concordance is sorting, which lines up the concordance alphabetically, grouping analogous occurrences together.
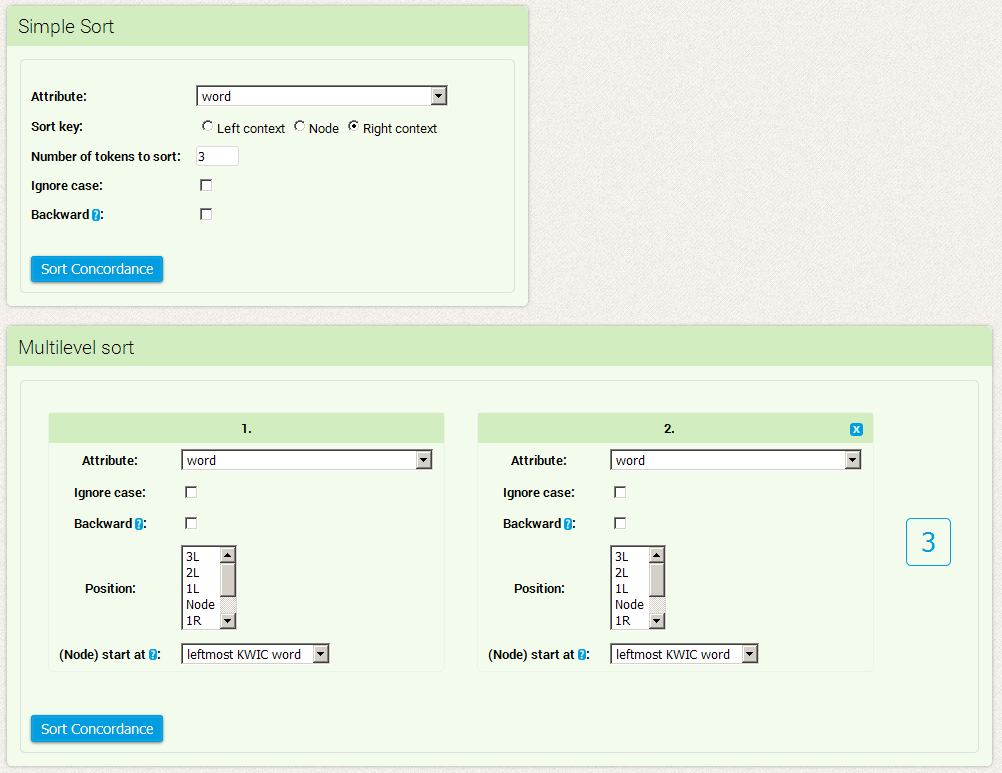
The KonText interface provides several possible ways of alphabetically sorting concordances.
- Simple sorting
- Multilevel sorting
For simple sorting, we select the criterion based on which we are doing the sorting (we can choose from any positional or structural attribute) and the range of the sorting (whether we are sorting the KWIC, the right or left context). As a result, we can have alphabetically sorted concordances e.g. according to the first preceding word, according to the form of the keyword, or according to the text type.
The option Number of tokens to sort determines the range of the context or KWIC (if it is a multi-word one) on which the sorting mechanism will focus. If we select the value 2 for the right context, the results will be sorted alphabetically according to the first and second words following the KWIC.
The options Ignore case and Backward are applied to both the simple and the multilevel sort. The option Ignore case determines whether lower-/uppercase will be distinguished during the sorting (case-sensitive) or whether they will count as one and the same symbol (case-insensitive). The second option enables traditional alphabetical sorting (unmarked) or retrograde sorting, i.e. alphabetical ordering starting from the end of words (instead of their beginning, as is usual).
Multilevel sort allows for the combination of all possible types of sorting into a hierarchy of maximally three levels. It is therefore possible to sort a concordance on the 1st level according to text type, and concordances with the same text type are then sorted on the 2nd level (e.g. according to the first right-hand context word) and on the 3rd level according to the keyword itself.
That a concordance has been sorted is indicated in the status bar of the concordance (next to its frequency information).
Shuffle
In the default settings, the concordance is ordered according to the order in which the search results (individual concordance lines) are found in the corpus (e.g. in the corpus SYN2015 the first texts are fiction, then non-fiction and finally journalistic). This has the advantage of quickly displaying the first page of results, while more matches are being retrieved in the background. Nonetheless, if the concordance is extensive, and one needs to acquire a representative sample (e.g. for manual analysis), it is preferable to work with randomly shuffled lines. The resulting shuffle of the concordance lines is random yet repeatable.
Shuffling the concordance lines can be achieved in two ways:
- Before starting the search, by selecting the Shuffle concordance lines option on the Query → Concordance page directly in the search form next to the Search button.
- After evaluating the query, by selecting Concordance → Shuffle.
Using the Shuffle option by default is recommended, as it ensures that every concordance, before being displayed, is randomized in this way. (After the first switch, the option remains activated for the following queries.) Such an approach functions as an effective prevention against drawing incorrect conclusions from studying a sample of results which originate from an unrepresentative set of texts.
Note: It is recommended to disable this option only temporarily in cases where a large concordance is expected, typically when searching for a frequent phenomenon in a corpus of billions of tokens. Particularly for these larger results, one should consider that turning on shuffling the lines can significantly increase the time spent waiting for the concordance to be displayed.
If the concordance lines have already been shuffled, the Concordance → Shuffle option will perform another random rearrangement. For each concordance, a reproducible shuffling algorithm causes the results after the first, second, third… n-th shuffle to match on repeated attempts with the same query. This guarantees the repeatability of experiments on corpora even when using a shuffled concordance.
Sample
An alternative to the shuffle, especially when working with an extensive concordance, is the creation of random samples (Concordance → Sample). The main advantage of this approach is the fact that an extensive concordance can be randomly reduced to an extent that will be within the user's powers to analyze. When we limit the concordance range in this way, it naturally also influences the absolute frequency of the results. However, if the sample is large enough, the relative frequency (i.e. the proportions between the studied phenomena) should remain preserved.
Permanent link
The Concordance → Permanent link function generates a permanent link to the concordance, which can be copied to the clipboard or later mentioned in an article, study, etc.
Menu: Query • Corpora • Save • Concordance • Filter • Frequency • Collocation • View • Help




