

Table of Contents
Menu: Corpora
The first menu item Available corpora shows a list of accessible corpora which can be filtered according to various criteria.
The remaining three items are dedicated to virtual subcorpora (i.e. subsets of texts from the original corpus). Here it is possible both to create your own subcorpus and to manage existing subcorpora (work on a subcorpus draft, view existing subcorpora, archive them, delete them, etc.).
Subcorpora are tied to the user account. Virtual subcorpora are therefore available to registered users from any computer, provided that they sign in with their username and password. The search results in each individual subcorpus are also visible to other users (e.g. by sending a link to concordances or frequency distribution tables created on the subcorpus data). The subcorpus itself can also be made public if the user fills in the public subcorpus description field.
Generally speaking, a subcorpus is only an additional condition which is applied to all queries in the search. For example, if we are searching for the lemma dřevo in the fiction subcorpus SYN2020:beletrie, the query will automatically add the condition within, which specifies the texts of the corpus SYN2020 in which the search is to be conducted.
Available Corpora
A list of all the corpora available to the user are accessible via the menu item Corpora → Available corpora. Due to the large number of corpora and their respective versions, following the first login, the user is shown a pre-filtered list of corpora with the label “Czech” (containing both the SYN series corpora, and the ORAL series, and many specialized and hosted corpora). A complete list of all corpora in alphabetical order appears after clicking on the label “Reset,“ on the far left. With all following visits the KonText interface will remember the user’s most recent settings and will display a list just as how the user had himself compiled it during his last visit.
Next to corpora which are limited in some way, usually due to licensing, there is an icon in the shape of a lock. If the user is interested in gaining access to such a corpus, he can put in his request by clicking on the icon and the corpus will be, if possible, made accessible to him.
Similarly as with corpus selection, the list of corpora can be filtered based on various criteria before the search itself. One of the possibilities is the use of the so-called labels characterizing each corpus. Furthermore it is possible to filter by the name of the corpus or its part, or according to its size (bookmark Advanced). By clicking on the star in the right-hand column we can add the corpus to our Favourites, on the other hand by turning it off we remove the corpus from the favourites.
Subcorpora and parallel corpora in the favourites list
As a favourite item we may label not only an entire independent corpus, but also a corpus including Subcorpora or aligned groups of two or three corpora within a parallel corpus InterCorp, which significantly speeds up our work. Owing to the fact that not all combinations of Subcorpora and/or aligned corpora can appear in the list of available corpora, it is necessary to add them to the Favourites list when they are selected as the current corpus. It is generally the case that by clicking on the star next to the corpus (subcorpus) name at a time when the given corpus (subcorpus) is selected as current for searching, the entire combination is added to the Favourites (including aligned corpora if there are any).
Create a new subcorpus

In the case that we want to, in the long term, work only with a specific group of texts in the given corpus, it pays off to create and save our own subcorpus on the server (on the other hand, with ad hoc searches in a subgroup of texts it is better to select the option Specify query according to the meta-information when typing a new query).
If we select Corpora → Create new subcorpus in the menu, a form for creating a permanent virtual subcorpus will appear. When creating a subcorpus it is necessary to specify:
- a default corpus, from which the text will be selected
- a subcorpus name, an unambiguous identifier which has not been previously used in the list of existing subcorpora
- if we wish the subcorpus to be publicly accessible via the page Corpora → Public subcorpora, we fill in the public description (if the field is left blank, the subcorpus will not appear there, though individual query results will still be public)
- a condition based on which we select the text for the subcorpus
The condition can be specified with a CQL query using the command within, or by selecting values of structural attributes from the ready selection. On the list of structural attribute values are numbers representing the text’s size in the given category (the number refers to the number of words or number of documents in the given category). Based on these numbers it is possible to create subcorpora with specific proportions.
Within this form it is possible to select those structural attribute values that interest us. The form does not contain all the structural attributes, but only those most frequently used in the given corpus (e.g. when searching in SYN2015 or SYN2020 it is txtype_group, txtype, genre, med, srclang). The abbreviations used can be found in the relevant section of lists.
Selection is governed by the same principles as in the case of query specification according to metainformation (see description of item Query). In the last column, a list of specific opuses or documents appears (based on the selected corpus), and these meet a specified condition. If such a list should be too long, the given column contains only the number of items. If we select several categories out of the options, we can then view a list of texts meeting these conditions with the button refine (bottom left). The column containing the list of texts will update itself according to the currently selected criteria. We can continue thus until we are satisfied with the specification of the date which we want to use for our search.

If a subcorpus is created by selecting structural attribute values, the resulting subcorpus can be combined in a concordance query with an ad hoc selection of text type values, where the values corresponding to the content of the selected subcorpus are automatically preselected at the beginning. This makes it possible to further refine the desired text types in the subcorpus.
Another option is to automatically sample texts to satisfy user-specified proportions (e.g. 50% of texts from fiction and 50% of journalistic texts). If you want to use this feature, when creating the subcorpus, tick the desired text types within the selected attribute and then click on Refine selection. This will make the Custom text type proportions function available. So, for example, if we want a SYN2015 journalism subcorpus that contains 50% national press and 50% regional press (the default is 75% national press and 25% regional press), we check both desired genres – NTW: national press and REG: regional press – in the doc.genre field and narrow the selection. Then we select the Custom text type ratios function and change the ratios to 50% and 50%. The resulting subcorpus will contain randomly selected texts from both genres in the ratio we chose.
Please be aware that the use of more than one structural attribute can easily lead to specifications that cannot be satisfied by any selection of texts from the original corpus. In this case, no subcorpus will be created.
Creating a subcorpus draft on the concordance query page
The subcorpus can also be created directly on the concordance query page under the Restrict search option. After checking the selected segments just click on the Save as a subcorpus draft option. To make a subcorpus active, you need to go to the menu Corpora → My subcorpora, find the subcorpus draft in the table and use the gear icon to open the subcorpus properties and then finalize it (see the following section).
My subcorpora
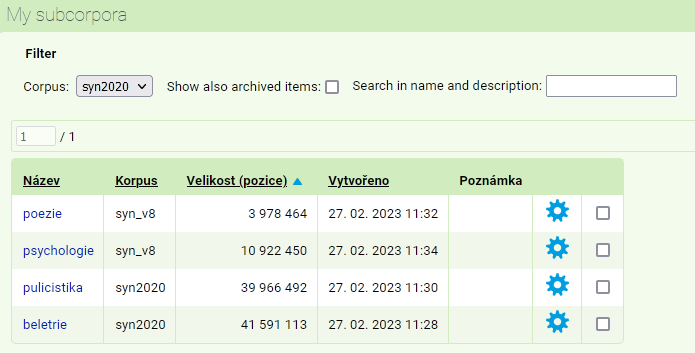
The section Corpora → My subcorpora provides a list of all the subcorpora (including drafts) defined by the user. The table lists their name, their size (as the number of positions) and the date they were created. Each line also contains a gear icon you can use to open a special menu and change the properties of the subcorpus:
- If the subcorpus is in draft status, you can finalize its settings (modify its structure, or add its public description) and convert it to active status by selecting Finalize subcorpus in the File tab.
- Only drafts allow changing the text selection of a given subcorpus using the Subcorpus structure tab. However, if the user changes the structure of an already created subcorpus, the settings can then be simply copied to a new subcorpus using the Save as… option.
- For each subcorpus, the name can be changed and public availability can be modified by adding or deleting the description in the Name and public description tab.
- If the user no longer plans to actively work with the subcorpus, it can be archived (using the Archive button on the File tab). In this case, the subcorpus will be hidden in the My subcorpora list, will not appear on the search pages, and will not be publicly accessible. However, the URLs created for the search results will still work. If necessary, an archived subcorpus can also be displayed in the My subcorpora list at a later time (by checking Show archived corpora as well) and restored to its original state.
- Subcorpora can also be permanently deleted by clicking the Delete button in the File tab. In this case, all subcorpus data is irretrievably removed, and the existing URLs are no longer valid. This procedure is therefore more appropriate for subcorpora that have not yet been shared between users, or if there is a serious reason to remove them.
The list contains all of the user’s subcorpora and allows for filtering based on the original parent corpus. However, it must be repeated that subcorpora ale always tied to the default (original) corpus. Therefore, if we create a fiction subcorpus from the corpus SYN2020 based on a general condition or by selecting one of the options, it doesn’t mean that we will also have at our disposition an analogical subcorpus of fiction from the corpus SYN2015.
Using subcorpora
Searching in the created subcorpus can by initiated by one click in the subcorpus in the menu Corpora → My subcorpora or by selecting a source corpus for the query and subsequently selecting in the drop-down menu, which is found next to the corpus specification.
Public subcorpora
The results of subcorpus searches can be made available to other users by simply sharing a link (assuming the users have access to the original parent corpus from which the subcorpus is derived). However, it is also possible to share subcorpora as a whole, if the user fills in the Public subcorpus description field when creating a subcorpus (on the Corpora → Create new subcorpus page) or editing it (in the menu on the Corpora → My subcorpora page).
Each subcorpus is assigned a unique key (e.g. 7e06d19af7) that can be shared and used to access the corpus from the menu Corpus → Public subcorpora. Alternatively, a public subcorpus can also be retrieved using the author's last name. This unique key is displayed either in the subcorpus properties on the Corpora → My subcorpora page (by clicking on the gear icon), the search results on Corpus → Public subcorpora, or if the corpus is already selected, by clicking on its name at the beginning of the navigation with the concordance editing sequence under the KonText logo.
Menu: Query • Corpora • Save • Concordance • Filter • Frequency • Collocation • View • Help




