

Toto je starší verze dokumentu!
Korpus Koditex
Koditex je korpus obsahující 9 milionů textových slov (tedy vyjma interpunkce), který byl vytvořen za účelem multidimenzionální analýzy (MDA) registrové variability češtiny.
| Název | Koditex | |
|---|---|---|
| Pozice | Počet pozic (tokenů) | 10 880 550 |
| Počet pozic bez interpunkce | 9 139 930 | |
| Počet pozic bez interpunkce vstupující do faktorové analýzy (include=„yes“) | 9 039 137 | |
| Počet slovních tvarů (wordů) | 509 764 | |
| Počet lemmat | 205 592 | |
| Struktury | Počet textových vzorků <chunk> | 3 428 |
| Počet vět <s> | 719 739 | |
| Další informace | Referenční | ANO |
| Reprezentativní | ANO | |
| Rok zveřejnění | 2018 | |
Při vytváření korpusu byl důraz kladen zejména na pestré složení, které odráží variabilitu češtiny ve všech jejích módech (psaná, mluvená, internetová komunikace), a na bohatou anotaci (texty byly lemmatizovány, morfologicky označkovány dvěma různými systémy, dále v nich byly anotovány frazémy a tzv. pojmenované entity – named entities). Z hlediska psanosti se tak jedná o korpus smíšený, dalšími jeho atributy jsou: synchronní, reprezentativní a referenční, tj. neměnný.
Název Koditex odkazuje jednak k osobě Viléma Kodýtka, který se jako první pokusil replikovat MDA na češtinu po vzoru D. Bibera, a zároveň je zkratkovým slovem pro korpus diverzifikovaných textů.
Složení korpusu
Na rozdíl od ostatních synchronních korpusů ČNK (např. SYN2015) se Koditex neskládá z celých textů, ale pouze ze vzorků originálních textů, které jsou označeny pomocí struktury <chunk>.
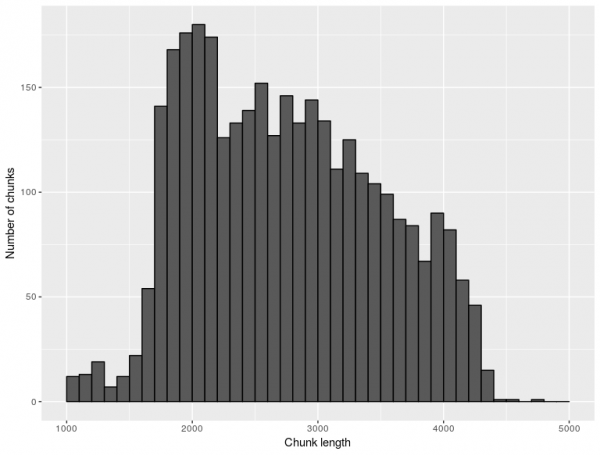
Ještě před samotným vzorkováním shromážděných dat a jejich začleněním do finální podoby korpusu jsme se rozhodli texty přesahující délku 5000 slov rozdělit do souvislých vzorků (chunks) o délce 2000–5000 slov (se zachováním hranic vět). Toto řešení představuje řadu výhod, a to zejména celkově větší rozmanitost korpusu, co se týče jak registrů, tak žánrů / textových typů.
Korpus tvoří texty ze tří komunikačních módů (mode):
- psaného jazyka (wri),
- mluveného jazyka (spo) a
- internetové komunikace (web).
Každý ze tří módů se dále dělí do dvou a více divizí (division; např. v rámci psaného jazyka se jedná o beletrii, oborovou literaturu, noviny a časopisy a soukromou komunikaci). Divize se dále dělí do tříd (class; například kriminální román), s cílovou délkou přibližně 200 000 slov na třídu (v závislosti na dostupnosti dat). Pro psaný mód byl ještě zaveden mezistupeň tzv. nadtřídy (superclass), která seskupuje některé třídy textů.
Texty původně zařazené do korpusu bylo v některých případech třeba z analýzy registrové variability vyloučit. V takovém případě mají v metadatech příznak include=„no“. V podrobné tabulce reflektující složení korpusu Koditex jsou zohledněny pouze texty, které do MDA vstupovaly (tedy s příznakem include=„yes“):
| MODE | DIVISION | SUPERCLASS | CLASS | Tokeny | Vzorky |
|---|---|---|---|---|---|
| spo (mluvená komunikace) | int (interaktivní) | bru (nepřipravené veřejné / vysílané rozhovory) | 221 812 | 90 | |
| eli (formální rozhovor) | 201 690 | 82 | |||
| inf (neformální rozhovor) | 208 565 | 86 | |||
| nin (neinteraktivní) | wbs (připravený/čtený projev) | 213 201 | 71 | ||
| web (internetová komunikace) | mul (mnohosměrná komunikace) | dis (internetové diskuse)† | 197 948 | 87 | |
| fcb (facebookové statusy)† | 199 418 | 91 | |||
| for (webová fóra)† | 200 104 | 85 | |||
| uni (jednosměrná komunikace) | blo (blogy) | 204 356 | 74 | ||
| wik (wikipedie) | 201 691 | 84 | |||
| wri (psaná komunikace) | fic (beletrie) | nov (romány) | crm (detektivky) | 190 026 | 68 |
| fan (fantasy) | 189 432 | 69 | |||
| gen (bez bližšího určení) | 193 667 | 67 | |||
| lov (milostné) | 189 893 | 70 | |||
| scf (sci-fi) | 188 703 | 68 | |||
| col (povídky) | 195 595 | 70 | |||
| scr (scénáře a dramata) | 182 689 | 76 | |||
| ver (poezie a písně) | 205 837 | 76 | |||
| nfc (oborová literatura) | pop (populárně-naučná) | fts (formální a technické vědy) | 207 607 | 68 | |
| hum (humanitní vědy) | 204 837 | 74 | |||
| nat (přírodní vědy) | 204 751 | 71 | |||
| ssc (společenské vědy) | 203 698 | 68 | |||
| pro (profesní literatura) | fts (formální a technické vědy) | 210 010 | 71 | ||
| hum (humanitní vědy) | 207 916 | 69 | |||
| nat (přírodní vědy) | 209 580 | 70 | |||
| ssc (společenské vědy) | 209 385 | 72 | |||
| sci (vědecká literatura) | fts (formální a technické vědy) | 202 932 | 67 | ||
| hum (humanitní vědy) | 204 300 | 71 | |||
| nat (přírodní vědy) | 206 716 | 72 | |||
| ssc (společenské vědy) | 205 358 | 67 | |||
| adm (administrativa)* | 203 542 | 82 | |||
| enc (encyklopedie) | 203 957 | 73 | |||
| mem (auto-/biografie) | 203 390 | 71 | |||
| nmg (noviny a časopisy) | lei (volnočasová publicistika) | hou (bydlení, zahrada, hobby) | 207 499 | 68 | |
| int (zajímavosti ze světa) | 209 232 | 69 | |||
| lif (životní styl) | 203 124 | 72 | |||
| mix (víkendové přílohy) | 205 310 | 75 | |||
| sct (bulvár) | 201 417 | 73 | |||
| spo (sport) | 199 238 | 70 | |||
| new (tradiční publicistika) | com (komentáře) | 205 372 | 68 | ||
| cul (kultura) | 205 690 | 68 | |||
| eco (ekonomika) | 211 481 | 70 | |||
| fre (volnočasové aktivity) | 208 532 | 71 | |||
| pol (politika) | 206 893 | 70 | |||
| rep (reportáže) | 206 377 | 70 | |||
| pri (soukromá komunikace) | cor (dopisy)* | 96 366 | 68 | ||
| Celkem | 9 039 137 | 3292 |
* V těchto třídách byly povoleny vzorky o délce minimálně 1000 tokenů.
† Texty v těchto třídách byly nejprve sjednoceny (podle autora a části dne) a poté rozděleny do vzorků o velikosti 2000–5000 slov.
Vzorky
Původním záměrem bylo mít veškeré vzorky o přibližně stejné délce (mezi 2000–5000 slovy). Ukázalo se, že tento záměr byl u některých tříd nerealistický vzhledem k typické délce textů, která v těchto daných třídách bývá kratší. Nabízela se dvě možná řešení. U některých tříd (např. pri či adm) jsme se rozhodli snížit spodní hranici na 1000 slov, což zároveň snížilo vliv textů, které byly v dané kategorii delší, než je obvyklé.
V jiných třídách (např. fcb) se původní data skládala z velkého množství fragmentů, z nichž většina měla délku méně než 1000 slov. V takových případech došlo nejprve ke shlukování textů podle autora a času a teprve pak se přistoupilo k samotnému vzorkování.
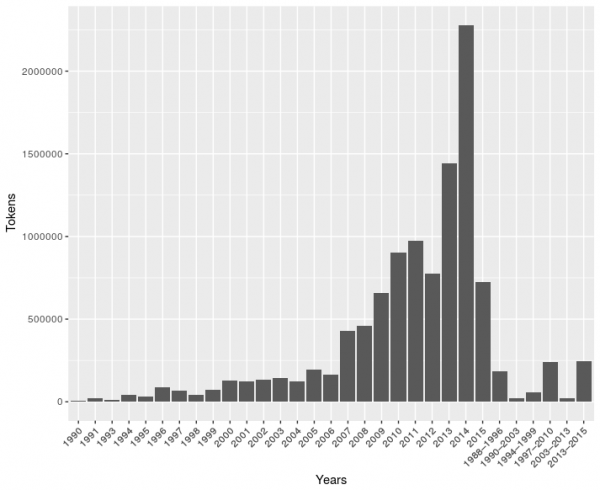
Koditex se zaměřuje na současnou podobu jazyka, přičemž nejstarší texty byly publikovány v roce 1990.
U většiny textů (s pokrytím 76 % všech tokenů) zahrnutých v tomto korpusu se jedná o české originály (tedy nikoliv překlady z jiných jazyků). Jedinou výjimkou jsou textové třídy, u kterých je v češtině výskyt přeložených materiálů zcela běžný. Tyto třídy jsou rozepsány v tabulce níže (u zbytku tříd se jedná o 100% české originály).
| Class | Překlady (slova) | Originály (slova) | % Překladů |
|---|---|---|---|
| LOV | 210,250 | 30,981 | 87.2% |
| CRM | 202,921 | 37,677 | 84.3% |
| GEN | 196,924 | 43,497 | 81.9% |
| FAN | 188,848 | 52,778 | 78.2% |
| SCF | 174,340 | 66,221 | 72.5% |
| MEM | 176,000 | 67,731 | 72.2% |
| HUM | 329,928 | 395,573 | 45.5% |
| NAT | 324,310 | 401,957 | 44.7% |
| ENC | 103,954 | 137,889 | 43.0% |
| SSC | 265,640 | 460,324 | 36.6% |
| FTS | 259,325 | 467,253 | 35.7% |
| VER | 82,101 | 158,634 | 34.1% |
| WIK | 49,150 | 192,765 | 20.3% |
Anotace
Korpusu bylo přidáno několik anotačních vrstev, aby se usnadnila operacionalizace rysů:
- lemmatizace a morfologické značkování; bylo využito dvou systémů: stochastického taggeru MorphoDiTa 1) a hybridního taggeru s použitím stochastické a na pravidlech založené desambiguace 2)
- značkování frazémů za pomoci systému FRANTA 3)
Následující statistické modely byly použitý s nástroji MorphoDiTa a NameTag:
- Straka, Milan & Jana Straková. 2016. Czech Models (MorfFlex CZ 161115 + PDT 3.0) for MorphoDiTa 161115. LINDAT/CLARIN digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University. http://hdl.handle.net/11234/1-1836
- Straka, Milan & Jana Straková. 2014. Czech Models (CNEC) for NameTag. LINDAT/CLARIN digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University. http://hdl.handle.net/11858/00-097C-0000-0023-7D42-8
Zdroje dat
Valná většina materiálů obsažených v korpusu Koditex čerpá ze zdrojů Českého národního korpusu (ČNK); jazyková data, která ČNK obvykle neshromažďuje, byla získána z jiných vědecko-výzkumných pracovišť. Chtěli bychom tímto také poděkovat Karlu Palovi a Vítu Baisovi z Centra zpracování přirozeného jazyka (CZPJ) na Masarykově univerzitě, a dále Josefu Šlerkovi a jeho týmu z Socialinsider za poskytnutí dat pro třídu wik a oddíl mul.
Korpus Koditex byl vytvořen vzorkováním různých zdrojů a s využitím různých nástrojů, zde je uveden jejich výčet:
- Benešová, Lucie, Michal Křen & Martina Waclawičová. 2013. ORAL2013.
- Benko, Vladimír. 2015. Araneum Bohemicum Maius, version 15.04. ÚČNK FF UK.
- Cvrček, Václav, Petr Truneček & Václav Horký. 2015. SPEECHES.
- Čermák, František, Ana Adamovičová & Jiří Pešička. 2001. PMK.
- Hladká, Zdeňka. 2002. BMK.
- Hladká, Zdeňka. 2006. KSK.
- Křen, Michal et al. 2015. SYN2015.
- Straka, Milan & Jana Straková. 2014. Czech Models (CNEC) for NameTag. LINDAT/CLARIN ÚFAL MFF UK. http://hdl.handle.net/11858/00-097C-0000-0023-7D42-8
- Straka, Milan & Jana Straková. 2016. Czech Models (MorfFlex CZ 161115 + PDT 3.0) for MorphoDiTa 161115. LINDAT/CLARIN ÚFAL MFF UK. http://hdl.handle.net/11234/1-1836
- The DIALOG Corpus, version 1.2. 2015. ÚJČ AV ČR. Praha. http://ujc.dialogy.cz
- The EUROPARL Corpus (the Proceedings of the European Parliament). http://www.europarl.eu.int/
Jak citovat Koditex
Zasina, Adrian J., David Lukeš, Zuzana Komrsková, Petra Poukarová & Anna Řehořková. 2018. Koditex (A corpus of diversified texts). Faculty of Arts, Institute of the Czech National Corpus, Charles University in Prague.




