Obsah
Specifika vyhledávání v paralelním korpusu
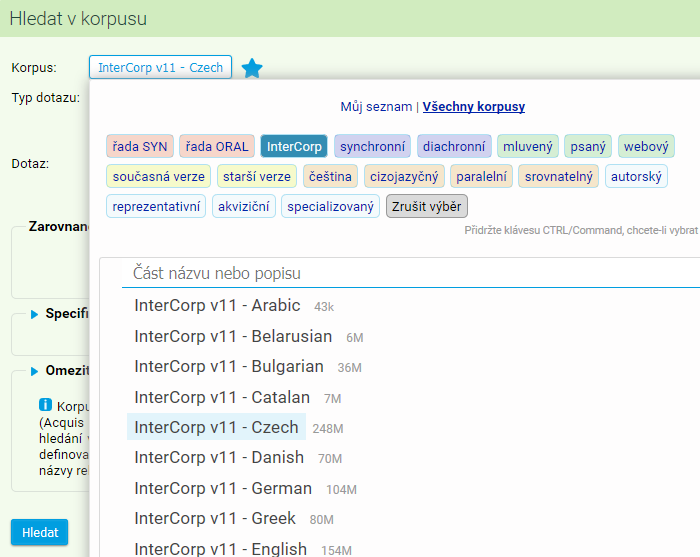
Z výchozího rozcestníku, který obsahuje seznam všech dostupných korpusů, vybereme štítek InterCorp a pak první jazyk, např. InterCorp v15 - Czech (případně jinou jeho verzi, doporučujeme nicméně pracovat vždy s tou nejnovější).
Takto je možné hledat pouze v českých textech zahrnutých do InterCorpu, primárně nás však budou zajímat paralelní konkordance. K tomu je zapotřebí přidat další jazyk. V sekci Zarovnané korpusy si vybereme druhý jazyk (případně jazyky další), který se má zobrazovat v rámci jednoho dotazu, např. InterCorp v15 - English. Nově přidaný jazyk se objeví v samostatném rámečku, který lze pomocí modrého křížku vpravo opět smazat.
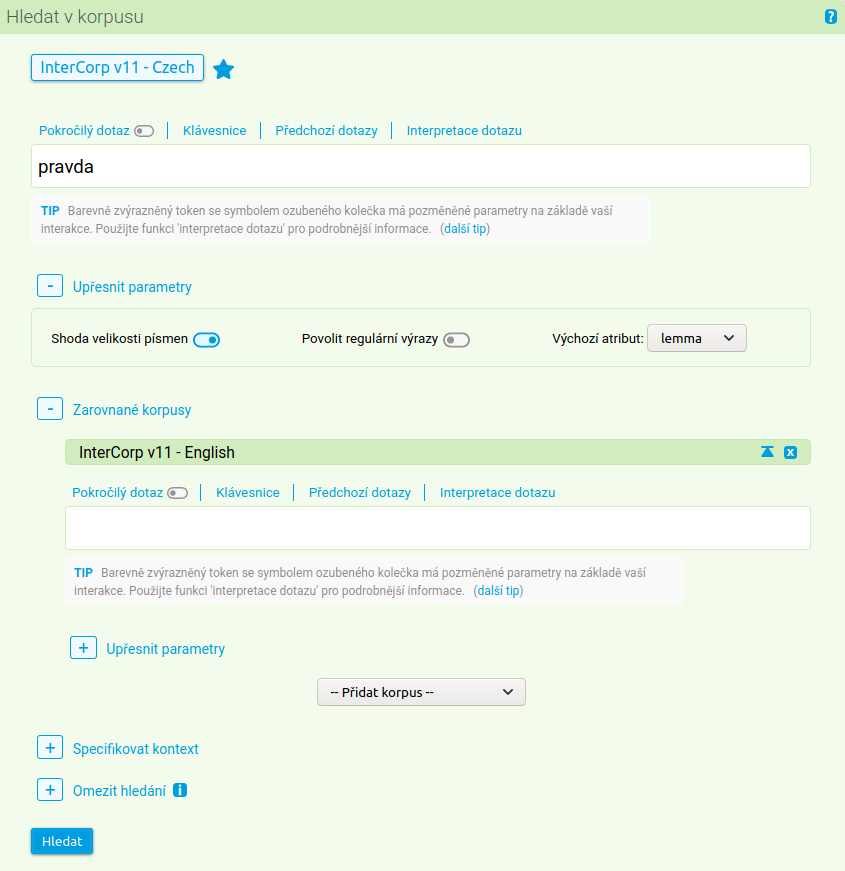
První možností je zadat dotaz pouze do prvního jazyka. Budeme-li hledat například všechny překlady slova pravda, zadáme do prvního jazyka tento výraz s výchozím atributem lemma a dotaz na druhý jazyk necháme prázdný.
Analýzou paralelních konkordancí následně můžeme dojít k tomu, že nejčastějším ekvivalentem českého lemmatu pravda v angličtině jsou adjektivní tvary right a true a substantivní truth. Podobné výsledky zprostředkovává i nástroj Treq – 5 nejčastějších protějšků z této databáze se objeví v Kontextu nalevo od paralelních konkordancí. Zaškrtnutím okénka vedle těchto ekvivalentů se příslušný výraz či výrazy podbarví v pravé části paralelní konkordance.
Okénko s rozšiřujícími informacemi lze zavřít (a znovu otevřít) kliknutím na modrou ikonku vlevo nahoře, případně stisknutím klávesy E.
Zároveň lze kliknout levým tlačítkem myši na libovolné slovo v paralelní konkordanci, to se podbarví a rozhraní se v paralelní části pokusí vyhledat jeho cizojazyčný ekvivalent (na základě nejčastějších protějšků podle aplikace Treq).
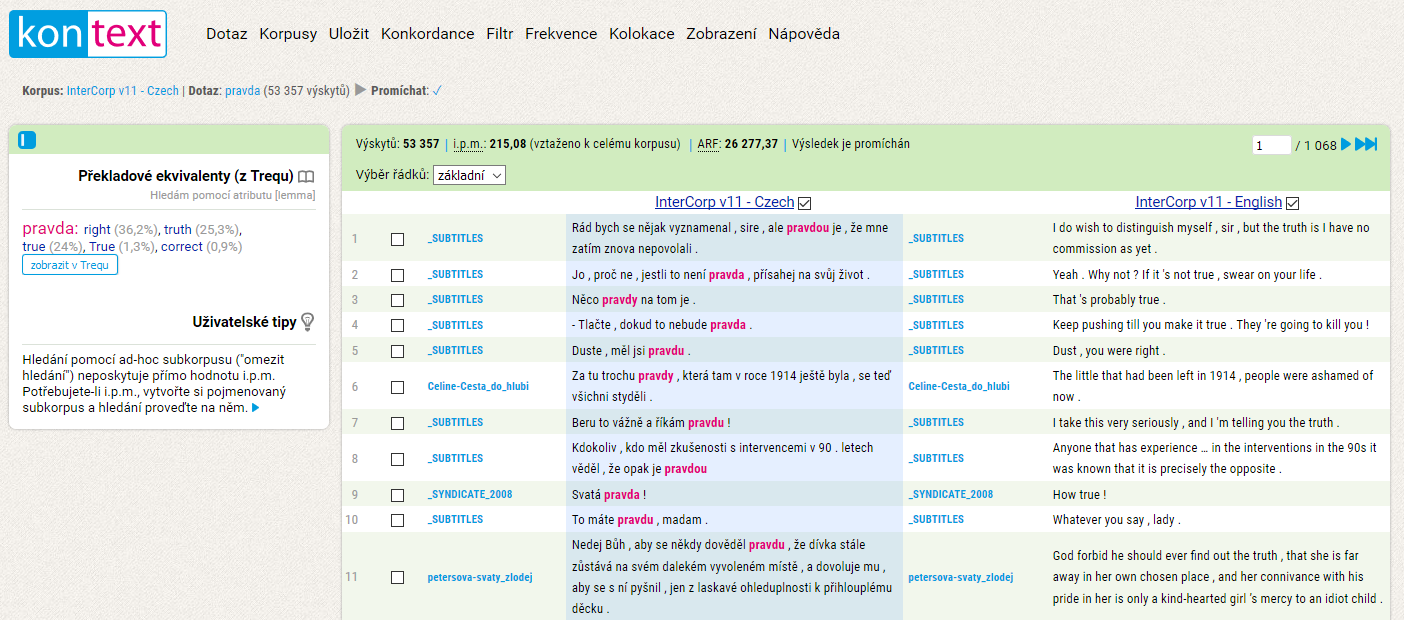

Pokud chceme prozkoumat věty, kde je pravda přeložena jako truth, můžeme položit dotaz v obou jazycích. Výsledek je pak omezen pouze na seznam konkordančních řádků, kde se objevují obě hledaná slova (nikoliv však nutně jako vzájemné ekvivalenty). Výsledná konkordance by měla vypadat takto:
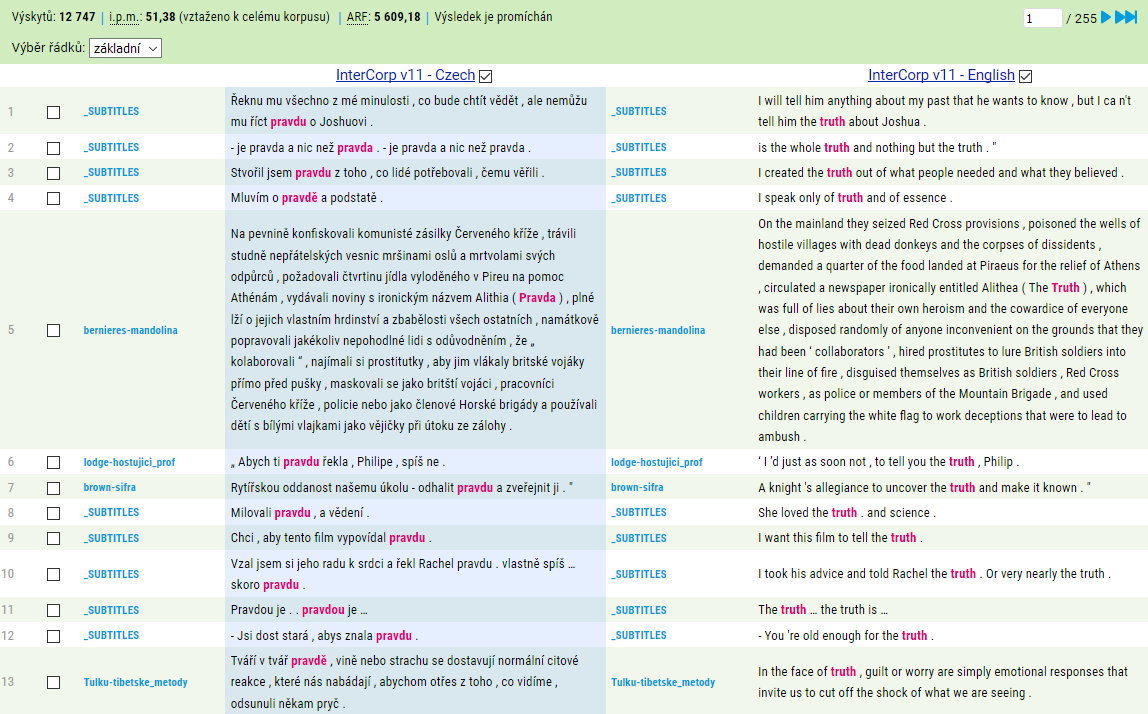
Ve dvou sloupcích vidíme segmenty (věty nebo spojení vět), které odpovídají našemu dotazu v obou jazycích. Tmavším pozadím je označen sloupec, který je aktivní a s nímž můžeme dále pracovat (v našem případě čeština). Pokud bychom chtěli za aktivní sloupec označit anglickou část, stačí kliknout na záhlaví sloupce. Veškeré statistické nástroje KonTextu (např. frekvenční distribuce nebo kolokace) pak pracují s takto vybraným sloupcem.
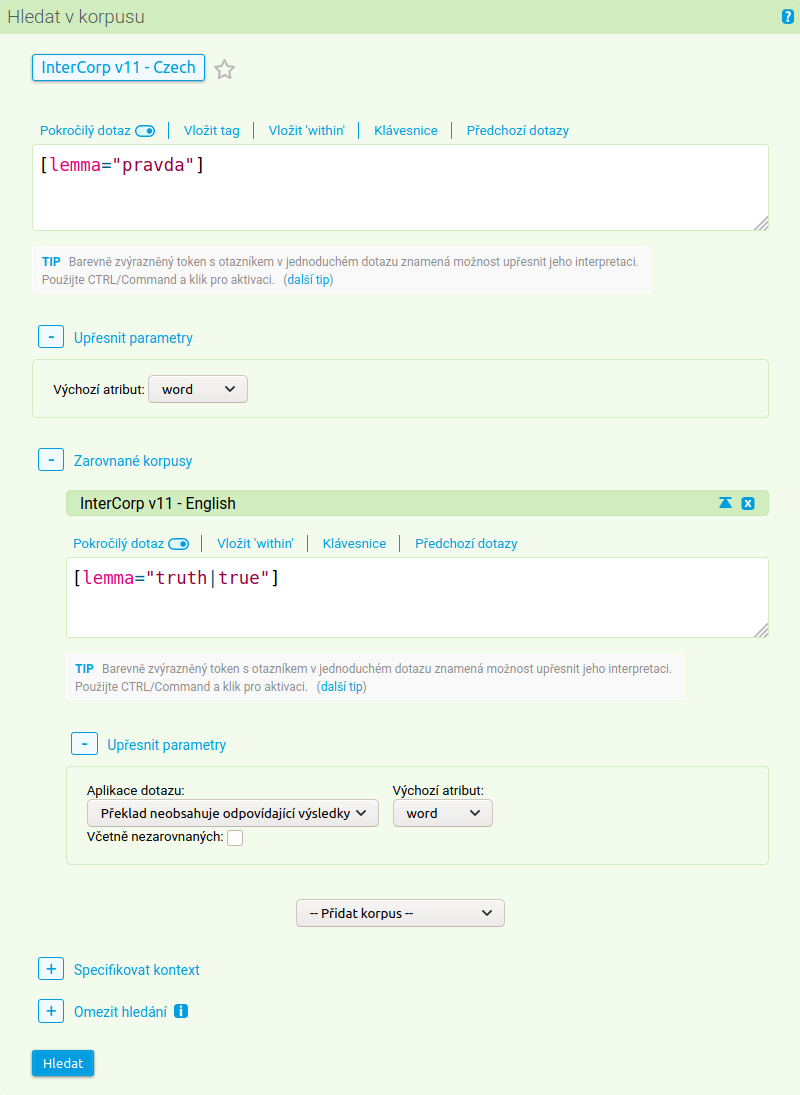
Pokud nás zajímají méně standardní překlady, můžeme dotaz položit obráceně. Na české straně vybereme lemma pravda a na anglické zvolíme lemma truth nebo true – případně obojí: [lemma="truth|true"] –, ale s volbou Příklad neobsahuje odpovídající výsledky.
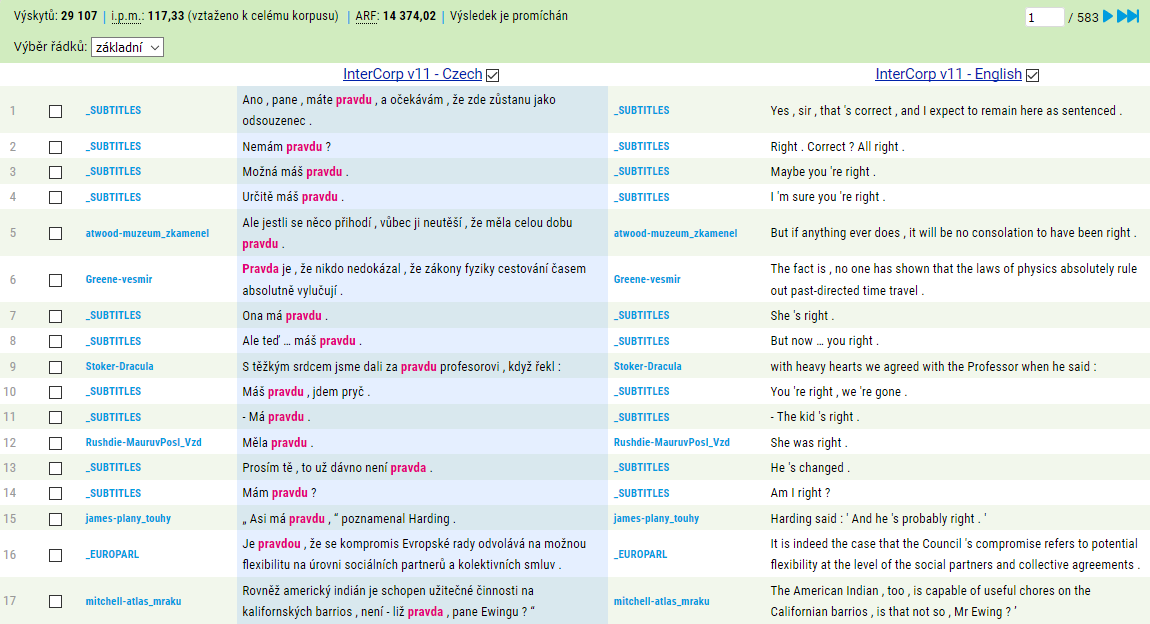
Takto získaný seznam konkordancí můžeme dále třídit pomocí filtrů.
Korpus InterCorp obsahuje velké množství textů, které jsou zpracované a zarovnané automaticky. Mnohdy je proto výhodnější vytvořením vlastního subkorpusu omezit hledání pouze na tu složku InterCorpu, která obsahuje ručně zarovnané texty, tzv. jádro (core). Toho lze nejsnáze dosáhnout vytvořením subkorpusu zvolením atributu korpusu div.group s hodnotou Core.
Pokud vytváříte subkorpus pomocí jiných parametrů, mějte na paměti, že omezení se týkají vždy pouze jazyka, na jehož základě subkorpus vytváříte.
Specifika korpusů řady InterCorp
Popisu celého korpusu InterCorp se věnuje tato stránka, zde vyjímáme několik zásadních upozornění:
- Ne každý jazyk v korpusu InterCorp je lemmatizovaný nebo tagovaný, tj. morfologicky označkovaný (např. u nizozemštiny či maďarštiny chybí ve verzi 9 lemmatizace), viz seznam.
- Způsob tagování je pro různé jazyky odlišný – může se lišit repertoárem a obsahem morfologických kategorií i způsobem jejich zápisu. Výjimkou je verze 13ud, která je anotována morfologicky i syntakticky podle zásad mezinárodního projektu Universal Dependencies, které jsou pro všechny jazyky jednotné.
- Korpusy jednotlivých jazyků se výrazně liší co do složení textových typů i žánrů, většinou tedy nejsou mezi sebou snadno srovnatelné.
- Velikost korpusu nekoreluje s počtem mluvčích daného jazyka (s jeho „velikostí“), je dána dostupností textů a aktivitou koordinačního týmu pro daný jazyk.
- U textů se značkami a lemmaty mohou přímočaře formulované dotazy na spřežková slova zůstat bez odpovědi. To se týká například anglických tvarů can’t nebo I’m, které tagger rozdělí na dvě slova (ca n’t a I ’m) s odpovídajícími lemmaty a značkami. Podobně je tomu i s polskými tvary typu byłam nebo gdybyś, rozdělenými na była m a gdyby ś). Je třeba počítat i s chybným rozdělením: gdzie ś za Wisłą. Dotaz na celou spřežku je nutné zadat v souladu s dělením podle příslušného taggeru a části spřežky oddělit mezerou.
- Paralelní korpus InterCorp se liší od korpusů řady SYN i některými strukturními jednotkami a jejich atributy. (Na strukturní značky a atributy se lze podívat nebo si je zvolit k zobrazení volbou Zobrazení → Korpusová nastavení.)
Srovnávací výzkum na korpusu InterCorp verze 15
Primárně jsou paralelní korpusy určeny pro provádění kontrastivního výzkumu. Lze je ovšem využít i pro srovnávání vlivu překladovosti v rámci jednoho jazyka.
Projevuje se v distribuci přivlastňovacích zájmen v češtině a angličtině typologický rozdíl mezi jazyky? Zaměřte se na distribuci posesiva his v různých korpusech a subkorpusech:
- BNC1)
- InterCorp – anglická složka
- InterCorp – subkorpus obsahující pouze původní, nepřekladovou angličtinu
Postup
- Nejprve je dobré zjistit tag daného zájmena, to kvůli možné tvarové homonymii (his by mohla být např. nějaká zkratka). Seznam tagů je k k dispozici v popisu korpusu, konkrétně anglický tagset je zde. Stejně tak je ale možné zadat do příslušného korpusu lemma his a podívat se do výsledků Frekvence → Vlastní, kde si nastavíme atribut tag. Takto přijdeme i na to, zda jsou vůbec některé tvary his tagované jinak než jako zájmeno.2)
- Celý postup si ukážeme na InterCorpu ve verzi 15.
- Pro vyhledávání v původní angličtině si vytvoříme příslušný subkorpus (
div.srclang=en).
Výsledky pro InterCorp v15 a BNC
| dotaz | korpus | abs. frekvence | rel. frekvence (i.p.m.) |
|---|---|---|---|
[lemma="his" & tag="DPS|PNP|UNC"] | BNC | 409 825 | 3684 |
[tag="PP\$" & lemma="his"] | InterCorp v15 | 484 326 | 2885 |
[tag="PP\$" & lemma="his"] within <text srclang="en" /> | InterCorp v15 (text.srclang=en) | 319 740 | 1904 |
BNC má jiné složení než InterCorp. Obsahuje např. i mluvený jazyk, zato mnohem méně právních textů (zastoupených v InterCorpu díky balíčku Acquis Communautaire). Výsledky tudíž nejsou přímočaře porovnatelné.
Po tomto srovnání se podívejme ještě na neoriginální část InterCorpu a výskyt lemmatu his (Frekvence → Podle typů textů → text.srclang):
| zdrojový jazyk | i.p.m. |
|---|---|
| angličtina | 3735 |
| čeština | 5368 |
| španělština | 5857 |
| ruština | 7584 |
| francouzština | 3008 |
| němčina | 1805 |
| švédština | 3013 |
| italština | 1817 |
| srbština | 9573 |
Celkově se tedy zdá, že zájmeno his je v textech distribuováno v závislosti na typu výchozího jazyka velmi nerovnoměrně.
Srovnávací výzkum na korpusu Jerome
Podobné srovnání můžeme provést i pro překladovou češtinu: pokusme se zjistit, jestli je frekvence přivlastňovacích zájmen ovlivněná tím, zda se jedná o překladový, nebo originální text. Této otázce je šitý na míru korpus Jerome. Výchozí úvaha se opírá o otázku, zda se překladatel nechává svést konstrukcemi typu he put on his coat a namísto oblékl si kabát použije oblékl si svůj kabát, nebo zda vliv zdrojového jazyka není patrný.
- Ze seznamu korpusů si pod štítkem specializovaný vyberte korpus jerome.
- Vložte do CQL dotazu patřičný tag:
[tag="P[8S].*"]3) - Zjistěte počet výskytů na milion textových slov v češtině v závislosti na různých zdrojových jazycích.
- Pokud se chcete procvičit, vytvořte si – vedle vyhledávání v korpusu Jerome – i subkorpusy daných jazyků v korpusu SYN2015: pomocí podmínek určitého zdrojového jazyka (
srclang="cs.*"atd.) eliminujte veškeré nepůvodní, překladové texty.
Korpus Jerome v souhrnné statistice (dostupné přes Frekvence → Typy textů úplně dole) uvádí v kolonce opus.status, že se přivlastňovací zájmena v překladech vyskytují v průměru 11 675krát na milion slov, zatímco v nepřekladové, původní češtině jen 10 493krát, což činí rozdíl cca 10 %.4) Nejfrekventovanější zdrojové jazyky jsou současně i typologicky odlišné, a tudíž vhodné k ověření hypotézy týkající se překladů do češtiny: angličtina, němčina i francouzština všechny využívají zájmena (přivlastňovací, ale i jiná) častěji než čeština:
| zdrojový jazyk | čeština | angličtina | němčina | francouzština |
|---|---|---|---|---|
| absolutní frekvence | 445 976 | 311 540 | 71 700 | 50 439 |
| relativní frekvence (i.p.m.) | 10 493 | 11 529 | 11 638 | 14 208 |
V korpusu SYN2015 je situace takováto:
| zdrojový jazyk | čeština | angličtina | němčina | francouzština |
|---|---|---|---|---|
| absolutní frekvence | 698 918 | 300 955 | 55 472 | 37 263 |
| relativní frekvence (i.p.m.) | 8771 | 11 745 | 11 415 | 14 712 |
Výrazně odlišné číslo pro češtinu v obou korpusech vybízí k bližšímu pohledu: jak se to má s přivlastňovacími zájmeny v různých typech textů? (Hledáme v korpusu SYN2015, korpus Jerome neobsahuje žádné publicistické texty.)
| skupina textových typů | relat. frekvence (i.p.m.) |
|---|---|
| beletrie | 11 432 |
| oborová literatura | 9461 |
| publicistika | 8360 |
Je vidět, že překladovost hraje roli, neméně podstatné ale je i to, z jakých textových typů (a žánrů, pokud chceme rozlišovat podrobněji) se skládá korpus, na němž se zakládají konkrétní výsledky.
Další možné využití korpusu InterCorp: falešní přátelé
Některé etymologicky spřízněné výrazy se významově výrazně rozešly. Z paralelních konkordancí je takový posun jasně prokazatelný. Např. český machr a německý Macher ukazují značný rozdíl – německý chlapík totiž v překladech není namyšlený český floutek, ale docela obyčejný hybatel dění či strůjce, původce.
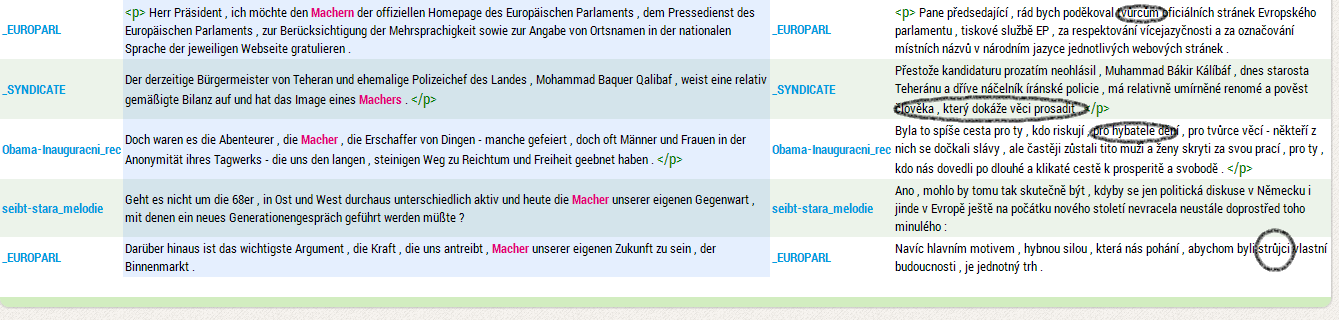
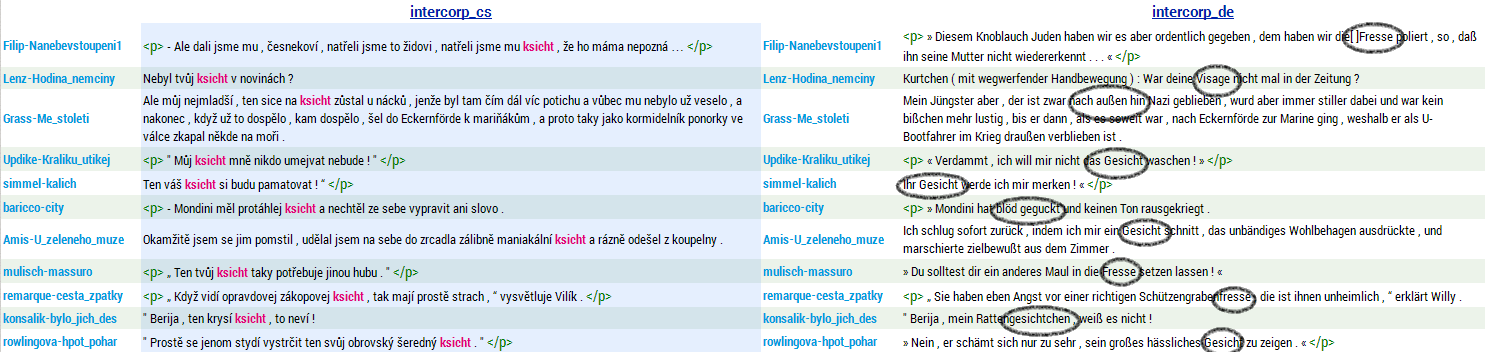
- Vyhledejte si v německé složce InterCorpu verze 15 lemma Gesicht a v jeho české paralele slova obsahující řetězec ksicht:
[word=".*ksicht.*"](nedbejte na zdrojový jazyk). - Naopak v české části najděte lemma ksicht a podívejte se na jeho německé ekvivalenty.
Hledání překladů lemmatu Gesicht jako ksicht a naopak v paralelním korpusu InterCorp v15 dává 190 dokladů. Jasné potvrzení o užitečnosti paralelních korpusů však poskytnou především výsledky pro dotaz čistě po ksichtu, kdy v konkordancích manuálně vyhledáme patřičné významové ekvivalenty: