

This is an old revision of the document!
OnomOs Corpus
The OnomOs corpus is a linguistically processed database of texts from the periodicals Rudé právo (published 1920–1995) and Právo (1995–present). It always contains one issue from each decade in which (Red) Právo was published. The corpus includes texts in which the language component dominates; therefore, e.g. advertisements and advertisements, cinema, theater and radio programs, some types of texts from the sports section (e.g. results overviews and player lists), comics or crosswords were not included. The structure of the corpus is presented in more detail in Figure 1. In total, the corpus contains 255 149 tokens.
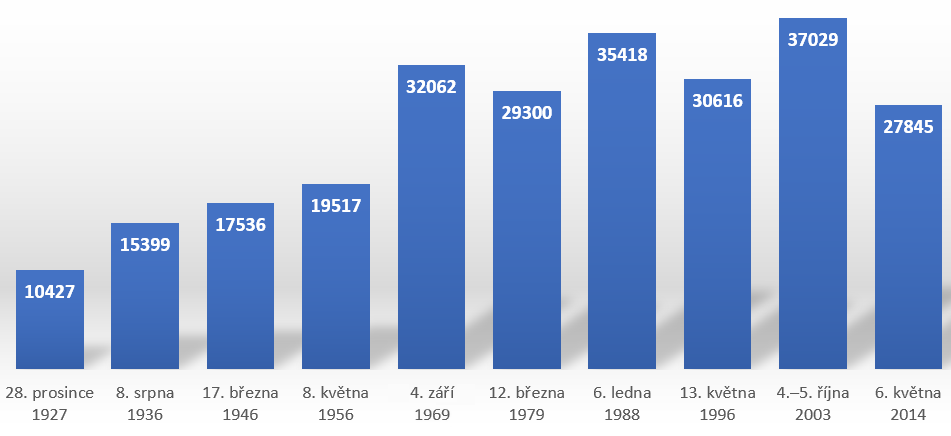
Figure 1 – OnomOs corpus structure (in tokens)




