

Table of Contents
The OnomOs v1 a OnomOs v2 corpora
The OnomOs v1 and OnomOs v2 corpora are linguistically processed databases of texts from the periodicals Rudé právo (published 1920–1995) and Právo (1995–present). The OnomOs v1 corpus includes one randomly selected issue from each decade in which Rudé právo was published. The composition of the corpus is detailed in Figure 1; the corpus contains a total of 255,149 tokens.
The OnomOs v2 corpus includes all the texts from the OnomOs v1 corpus, plus an additional issue from each five-year period that is not represented in the randomly selected issues of OnomOs v1. For example, if an issue of Rudé právo from March 12, 1979 was selected for the 1970s in the OnomOs v1 corpus, then OnomOs v2 adds another issue randomly selected from the 1970–1974 five-year period. Decades are defined as commonly referred to in colloquial usage of “-ties”; for example, the 1970s (“seventies”) are defined as the period from 1970 to 1979. Figure 2 illustrates the issues that were added to the OnomOs v2 corpus as compared to the OnomOs v1 corpus. Its total size of the corpus is 505,102 tokens.
The corpora include texts dominated by the linguistic component; therefore, advertisements, theatre, cinema, and radio programs, certain types of sports section texts (e.g., results overviews and player rosters), comics, and crossword puzzles were excluded.
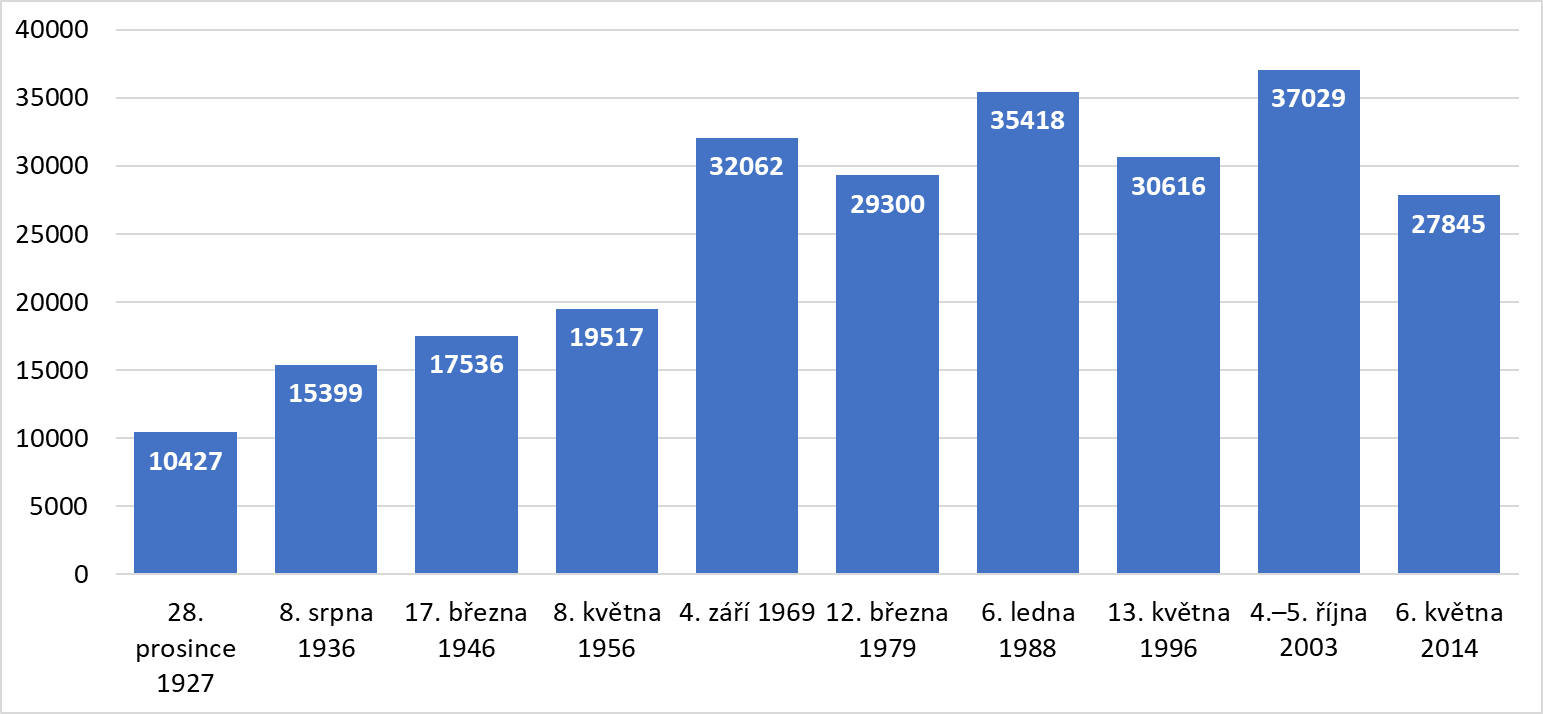
Figure 1 – The OnomOs v1 corpus structure (in tokens)
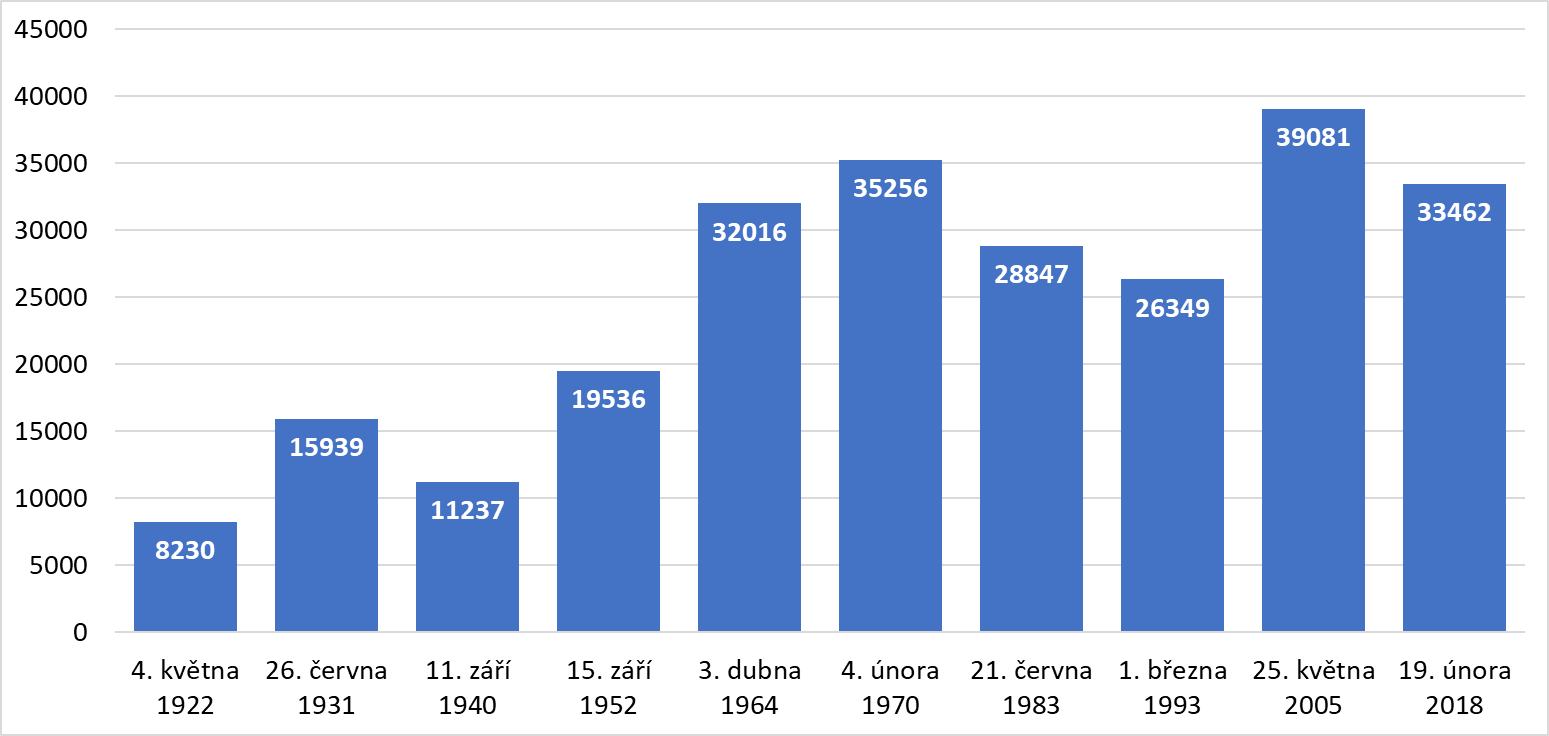
Figure 2 – The structure of the parts added to the OnomOs v2 corpus (in tokens)
A characteristic feature of the corpora is the tagging of proper names, which could serve as a methodological foundation for similar projects in the future. For the OnomOs v1 corpus, the annotation was performed using the NameTag 2 software (Straková – Straka – Hajič, 2019; Ševčíková – Žabokrtský – Krůza, 2007; see here: https://ufal.mff.cuni.cz/nametag/2), while the OnomOs v2 corpus utilized the NameTag 3 software (Straková – Straka, 2025; see here: https://ufal.mff.cuni.cz/nametag/3). Thus, the annotations of both corpora may slightly differ from each other.
The classification of proper names used by NameTag 2 and 3 has, however, been adjusted to align with the linguistic and onomastic concepts of proper names (see Šrámek, 1999, and relevant entries in the New Encyclopedic Dictionary of the Czech Language online: Karlík – Nekula – Pleskalová, 2017) and contemporary onomastic terminology. The basis of this classification consists of higher-order categories, represented by anthroponyms (personal names; A), toponyms (place names; T), and chrematonyms (names of human-made products and creations; C). Each of these categories is further divided into lower-order categories (e.g., AF – first names, TT – names of territories, CF – names of companies and corporations). The two-letter coding for lower-order categories is derived from their English names or closely related terms (e.g., currencies are labelled as CM, based on the English word “money”); the letters “X” and “Y” are reserved for less specified groups (underspecified; e.g., CX). Expressions with numerals (n), including numbers in addresses (a), and some other categories not considered proper names in Czech tradition (e.g., email addresses [me], internet links [mi], measurement units [oe], academic titles [pd], and most time expressions, such as names of months [tm]) are excluded from the classification. The transformation of the NameTag 2 and 3 categories into the new onomastic classes is comprehensively presented in Table 1.
| Higher-order category (NameTag 2 and 3) | Lower-order category (NameTag 2 and 3) | Lower-order category (OnomOs) | Higher-order category (OnomOs) |
|---|---|---|---|
| p - Personal names | pf - first names | AF: first names | Antroponyma (A) |
| pm - second names | |||
| pc - inhabitant names | AI: inhabitants | ||
| pp - relig./myth persons | AM: religious and mythological names | ||
| ps - surnames | AS: surnames | ||
| p_ - underspecified | AX: underspecified anthroponyms | ||
| g - Geographical names | gl - nature areas / objects | TN: nature names | Toponyma (T) |
| gh - hydronyms | |||
| gq - urban parts | TS: settlements | ||
| gu - cities/towns | |||
| gr - territorial names | TT: territories | ||
| gt - continents | |||
| gc - states | |||
| gs - streets, squares | TU: urbanonyms | ||
| g_ - underspecified | TX: underspecified toponyms | ||
| i - Institutions | ia - conferences/contests | CC: conferences, contests and events | Chrématonyma (C) |
| if - companies, concerns… | CF: companies | ||
| ic - cult./educ./scient. inst. | CI: cultural and educational institutions | ||
| io - government/political inst. | CP: politics | ||
| i_ - underspecified | CX: underspecified institutions | ||
| m - Media names | mn - periodical | CN: periodicals | |
| ms - radio and TX stations | CT: radios and TVs | ||
| o - Artifact names | oa - cultural artifacts (books, movies) | CA: art products | |
| or - directives, norms | CD: directives and norms | ||
| om - currency units | CM: currencies | ||
| op - products | CR: products | ||
| o_ - underspecified | CY: underspecified artifacts | ||
| t - Time expressions | tf - feasts | CH: feasts |
Table 1 - Modification of proper name classification in NameTag 2 and 3 for the purposes of the OnomOs v1 and v2 corpora
The OnomOs v1 and OnomOs v2 corpora were compiled by researchers of the “Ostrava Onomastics School,” which, within the scope of the research at the Department of Czech Language, Faculty of Arts, University of Ostrava, focuses on the implementation of quantitative linguistic methods into the science of proper names. The corpora were created with the support of grant projects SGS02/FF/2023 OnomOs – Ostrava Corpus of Proper Names and SGS02/FF/2024 Czech Linguistics of the 21st Century – Interviews, Topics, Analysis, which were conducted at the Faculty of Arts, University of Ostrava.
How to search for names in the OnomOs v1 and v2 corpora
Proper names in the OnomOs v1 and v2 corpora can be searched using the following CQL command (lower-order categories are specified in quotation marks):
[] within <ne type="TT: territories" />
The resulting concordance, which captures territorial names in the OnomOs v1 corpus, can be found in Figure 3. A shortened command is also sufficient:
[] within <ne type="TT.*" />
If higher-order categories need to be searched, the following command can be used (the first letter of the category – A, C, or T – is specified in quotation marks):
[] within <ne type="T.*" />
An alternative approach is to display the complete frequency list of lower-order categories. In this case, all the words in the corpus can be searched (= by leaving the query line empty), and then “Frequency” and “Custom…” are selected from the toolbar. In the frequency distribution window, select “By text types” and check “ne.type.” A similar procedure can be applied when you work with subcorpora (e.g., with the interwar issues of Rudé právo) or when you wish to display the frequencies of individual lower-order categories for a selected higher-order category (e.g., toponyms; see Figure 4).
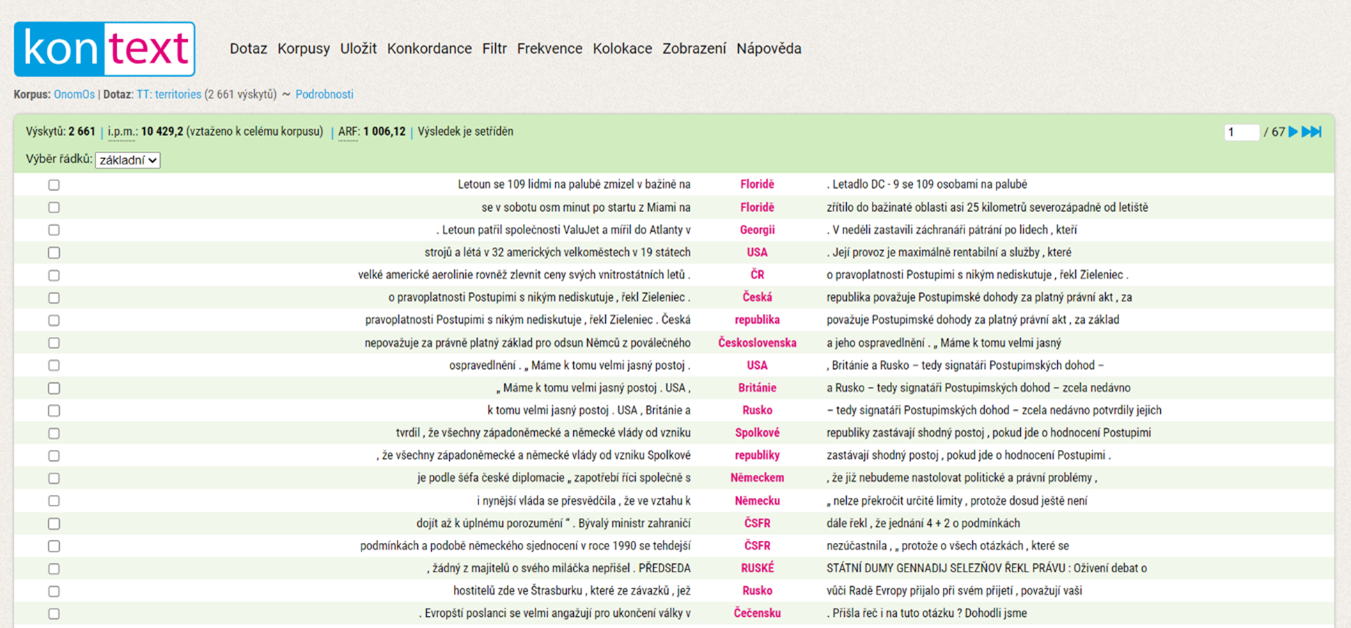
Figure 3 - concordance of all the occurrences of territorial names in the OnomOs v1 corpus
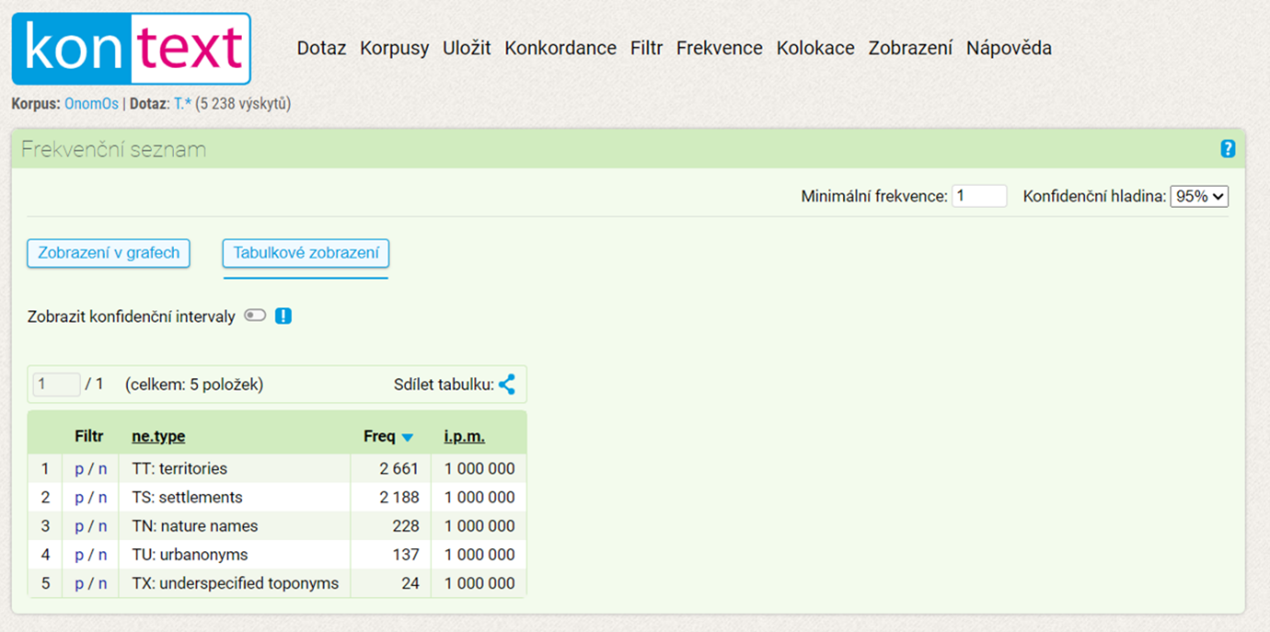
Figure 4 - distribution of the toponym types in the OnomOs v1 corpus.
Citing the OnomOs v1 and v2 corpora
David, J. – Davidová Glogarová, J. – Klemensová, T. – Místecký, M. – Jeziorský, T. – Křen, M. – Březinová, K. – Halatová, H. – Mádrová, J. – Pavlištíková, J. – Polášková, K. – Reclik, A. – Strnadlová, M. Korpus OnomOs v1. Ústav Českého národního korpusu FF UK, Praha 2023. Dostupný z WWW: http://www.korpus.cz.
David, J. – Davidová Glogarová, J. – Jeziorský, T. – Křen, M. – Březinová, K. – Halatová, H. – Mádrová, J. – Klemensová, T. – Místecký, M. Korpus OnomOs v2. Ústav Českého národního korpusu FF UK, Praha 2025. Dostupný z WWW: http://www.korpus.cz.
References
- Karlík, P. – Nekula, M. – Pleskalová, J. (2017, eds.), Nový encyklopedický slovník češtiny online. Brno: Masarykova univerzita. Dostupný z WWW: https://www.czechency.org.
- Straková, J. – Straka, M. (2025). NameTag 3: A Tool and a Service for Multilingual/Multitagset NER. Dostupné z WWW: https://arxiv.org/abs/2506.05949.
- Straková, J. – Straka, M. – Hajič, J. (2019): Neural Architectures for Nested NER through Linearization. In: A. Korhonen – D. Traum – L. Màrquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florencie: Association for Computational Linguistics, s. 5326–5331.
- Ševčíková, M., Žabokrtský, Z., Krůza, O. (2007): Named Entities in Czech: Annotating Data and Developing NE Tagger. In: V. Matoušek – P. Mautner (eds), Text, Speech and Dialogue. TSD 2007. Lecture Notes in Computer Science. Berlin – Heidelberg: Springer, s. 188–195.
- Šrámek, R. (1999): Úvod do obecné onomastiky. Brno: Masarykova univerzita.




