

This is an old revision of the document!
How to cite corpora accessed through the CNC
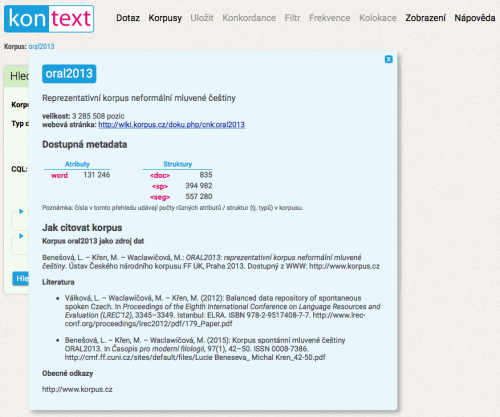
Ways of citing the corpora
There are essentially two ways in which corpora can be cited in an academic text:
- listing the corpus as a reference or source of data;
- listing a reference to the specific article which describes the creation and the structure of the corpus.
It is for the user to decide between these two options, depending also on the specific purpose of the citation; it is, of course, possible to combine the two ways of citing. The specific form of the citation can be found on these wiki pages, on the page dedicated to the given corpus, and also in the KonText interface itself, after clicking on the link containing the name of the corpus.
Citations ad 1) are included without exception, citations ad 2) only in KonText and only for most of the corpora; they are missing in cases where no article with a description of the corpus could be found. In addition to specific bibliographic data, for some of the corpora in KonTextu you can find a direct link to the address from which the article can be downloaded.
Citing non-reference corpora
When citing non-reference corpora which are not an unchangeable reference source, it is necessary to also include the version number and the time of access, similarly as it is done when citing web pages. For every non-reference corpus, information about the current version is available in the Kontext interface as part of the citation information.
When citing a specific text it is also possible to cite the list of sources SYN2000, SYN2005 or SYN2010.
Lemmatization and tagging
If you use lemmatization or morphological tags (attributes lemma or tag in the SYN series corpora), please also cite the following publications:
Jan Hajič: Disambiguation of Rich Inflection (Computational Morphology of Czech). Vol. 1. Karolinum Charles University Press, Praha 2004.
Tomáš Jelínek (2008): Nové značkování v Českém národním korpusu. In: Naše řeč, 91, 1, pp. 13–20.
Drahomíra Spoustová, Jan Hajič, Jan Votrubec, Pavel Krbec, Pavel Květoň: The Best of Two Worlds: Cooperation of Statistical and Rule-Based Taggers for Czech. In: Proceedings of the Workshop on Balto-Slavonic Natural Language Processing. ACL 2007, Praha. pp. 67–74.
Vladimír Petkevič (2006): Reliable Morphological Disambiguation of Czech: Rule-Based Approach is Necessary. In: Insight into the Slovak and Czech Corpus Linguistics (Šimková M. ed.). Veda, Bratislava, pp. 26–44.
Citing specialized applications
SyD program
Cvrček, V. – Vondřička, P.: SyD - Korpusový průzkum variant. FF UK. Praha 2011. Available on WWW: <http://syd.korpus.cz>.
Cvrček, V. – Vondřička, P.: Výzkum variability v korpusech češtiny. In: F. Čermák (ed).: Korpusová lingvistika Praha 2011. 2. Výzkum a výstavba korpusů. NLN. Praha, s. 184–195.
Morfio program
Cvrček, V. – Vondřička, P.: Morfio. FF UK. Praha 2013. Available on WWW: <http://morfio.korpus.cz>.
Cvrček, V. – Vondřička. P. (2013): Nástroj pro slovotvornou analýzu jazykového korpusu. In: Gramatika a korpus 2012. Gaudeamus. Hradec Králové.
KWords program
Cvrček, V. – Vondřička, P.: KWords. FF UK. Praha 2013. Available on WWW: <http://kwords.korpus.cz>.




