

How to cite corpora accessed through the CNC
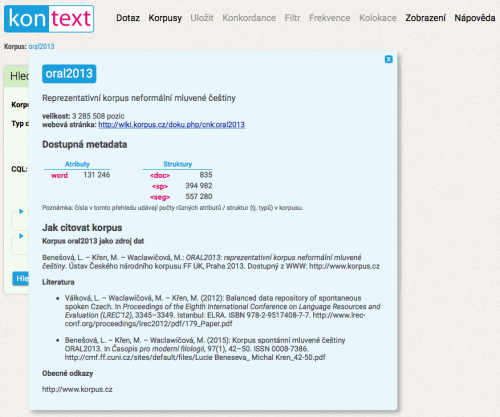
Ways of citing the corpora
There are essentially two ways in which corpora can be cited in an academic text:
- listing the corpus as a reference or source of data;
- listing a reference to the specific article which describes the creation and the structure of the corpus.
It is for the user to decide between these two options, depending also on the specific purpose of the citation; it is, of course, possible to combine the two ways of citing. The specific form of the citation can be found on these wiki pages, on the page dedicated to the given corpus, and also in the KonText interface itself, after clicking on the link containing the name of the corpus.
Citations ad 1) are included without exception, citations ad 2) only in KonText and only for most of the corpora; they are missing in cases where no article with a description of the corpus could be found. In addition to specific bibliographic data, for some of the corpora in KonTextu you can find a direct link to the address from which the article can be downloaded.
Citing non-reference corpora
When citing versioned corpora, it is necessary to also include the version number. The version number is available in the KonText interface as part of the citation information.
When citing a specific text it is also possible to cite the list of sources SYN2000, SYN2005 or SYN2010.
Lemmatization and tagging
- If you use lemmatization, morphological or verb tags (attributes lemma, tag or verbtag in the SYN series corpora), please also cite one of the following publications:
Tomáš Jelínek, Jan Křivan, Vladimír Petkevič, Hana Skoumalová, Jana Šindlerová (2021): SYN2020: A new corpus of Czech with an innovated annotation. In: K. Ekštein – F. Pártl – M. Konopík (eds.), Text, Speech, and Dialogue. TSD 2021. Lecture Notes in Computer Science, vol. 12848. Cham: Springer, pp. 48–59.
Křivan, J. – Šindlerová, J. (2022): Změny v morfologické anotaci korpusů řady SYN: nové možnosti zkoumání české gramatiky a lexikonu. Slovo a slovesnost, 83, 2/2022, pp. 122–145.
- You can also cite any of the following articles that relate to the annotation used:
Jan Hajič: Disambiguation of Rich Inflection (Computational Morphology of Czech). Vol. 1. Karolinum Charles University Press, Praha 2004.
Milena Hnátková, Michal Křen, Pavel Procházka, Hana Skoumalová (2014): The SYN-series corpora of written Czech. In: Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14), pp. 160–164. Reykjavík: ELRA. http://www.lrec-conf.org/proceedings/lrec2014/pdf/294_Paper.pdf
Vladimír Petkevič (2014): Problémy automatické morfologické disambiguace češtiny. In: Naše řeč, 97, 4, pp. 194–207.
Milan Straka, Jana Straková, Jan Hajič (2019): Czech Text Processing with Contextual Embeddings: POS Tagging, Lemmatization, Parsing and NER. In: Proceedings of the 22nd International Conference on Text, Speech and Dialogue - TSD 2019, Lecture Notes in Computer Science, ISSN 0302-9743, 11697, pp. 137-150.
- For the lemmatization and tagging of the spoken ORAL corpus, you can also cite:
Marie Kopřivová, Zuzana Komrsková, David Lukeš, Petra Poukarová (2017): Korpus ORAL: sestavení, lemmatizace a morfologické značkování. In: Korpus – gramatika – axiologie, 15, pp. 47–67.
Citing specialized applications
Word at a Glance (WaG)
Tomáš Machálek (2019): Word at a Glance – application for word profile aggregation. FF UK, Praha. Available from <http://korpus.cz/slovo-v-kostce/>.
Tomáš Machálek (2019): Word at a Glance – a Customizable Word Profile Aggregator. In: Proceedings of the CLARIN Annual Conference 2019, s. 85–88.
Tomáš Machálek (2014): KonText – application for working with language corpora. FF UK, Praha. Available from <http://kontext.korpus.cz>.
Václav Cvrček – Pavel Vondřička (2011): SyD – corpus study of variants. FF UK, Praha. Available from <http://syd.korpus.cz>.
Václav Cvrček – Pavel Vondřička (2011): Výzkum variability v korpusech češtiny. In: František Čermák (ed.): Korpusová lingvistika Praha 2011. 2. Výzkum a výstavba korpusů. NLN, Praha, s. 184–195.
Václav Cvrček – Pavel Vondřička (2013): Morfio – application for analyzing morphological relations. FF UK, Praha. Available from <http://morfio.korpus.cz>.
Václav Cvrček – Pavel Vondřička (2013): Nástroj pro slovotvornou analýzu jazykového korpusu. Gramatika a korpus 2012. Gaudeamus, Hradec Králové.
Václav Cvrček – Pavel Vondřička (2013): KWords – application for the extraction of keywords. FF UK, Praha. Available from <http://kwords.korpus.cz>.
Martin Vavřín – Alexandr Rosen (2015): Treq – database of translation equivalents. FF UK, Praha. Available from <http://treq.korpus.cz>.
Michal Škrabal – Martin Vavřín (2017): Databáze překladových ekvivalentů Treq. Časopis pro moderní filologii 99 (2), s. 245–260.
Michal Škrabal – Martin Vavřín (2017): The Translation Equivalents Database (Treq) as a Lexicographer’s Aid. In: I. Kosem et al. (eds): Electronic lexicography in the 21st century. Proceedings of eLex 2017 conference. Lexical Computing CZ, s. r. o., Leiden, s. 124–137.




