

Toto je starší verze dokumentu!
Poziční atributy specifické pro některé mluvené korpusy
V některých mluvených korpusech se objevují kromě běžných doplňkových pozičních atributů odvozených procesem morfologického značkování ještě některé další. Souvisejí se specifickou povahou mluvených dat.
Atributy fon, ort a dial
Tyto atributy obsahují alternativní zápisy tokenu zachyceného v primárním pozičním atributu word podle různých přepisovacích pravidel. V případě mluvených korpusů totiž zdrojová data představuje přímo zvuková nahrávka, jakýkoli přepis je již interpretace. Pro různé účely se hodí různé interpretace:
- chceme-li přepis morfologicky značkovat, hodí se, aby byl do jisté míry standardizovaný, aby si s ním uměly poradit nástroje automatické morfologické analýzy
- chceme-li zkoumat specifika mluveného jazyka, hodí se mít přepis co nejvěrněji odrážející skutečně vyslovené
Některé novější mluvené korpusy ČNK si kladou za cíl plnit více těchto funkcí zároveň, a obsahují tedy několik příslušně uzpůsobených paralelních přepisů, přičemž primární vrstva pro daný korpus je vždy v atributu word. Navíc mohou být k dispozici (v závislosti na korpusu) následující alternativní vrstvy:
fon: obsahuje fonetický přepis v korpusu, kde primární vrstvawordobsahuje standardizovaný přepis (např. v korpusu ORTOFON)ort: obsahuje standardizovaný přepis v nářečním korpusu, kde primární vrstvawordobsahuje nářeční přepisdial: obsahuje nářeční přepis v nářečním korpusu, kde primární vrstvawordobsahuje standardizovaný přepis
Nářeční korpus DIALEKT je dostupný v obou výše popsaných variantách, odtud tedy zrcadlová existence atributů ort a dial. Obě varianty jsou pro usnadnění práce paralelně zarovnané.
Atribut uid
Atribut uid sdružuje pozice (tokeny) vyslovené v rámci jedné repliky, přičemž repliku definujeme jako jeden nebo více segmentů (struktur <sp/>) téhož mluvčího navazujících v těsné blízkosti za sebou. Intuitivnější než definice snad bude obrázek:
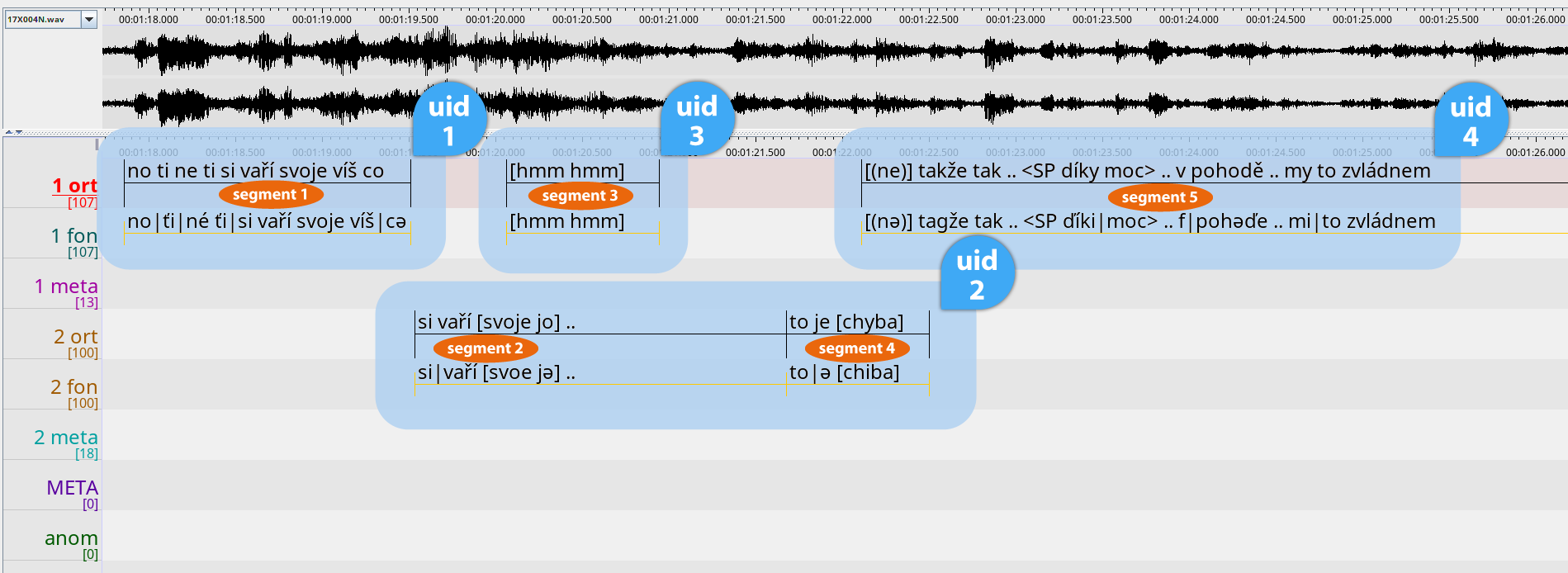
Je patrné, že replika s uid = 2 je rozdělena do dvou segmentů (2 a 4).
Motivace pro tento atribut vychází z povahy mluveného jazyka. Zatímco psané texty jsou primárně lineární, a jakákoli narušení této linearity (textové boxy, poznámky pod čarou apod.) je možné „uzávorkovat“, odstranit z textu, aniž by utrpěla jeho kontinuita, mluvené texty je spíš vhodné popisovat jako multilineární, sestávající z více proudů řeči1) od různých mluvčích, které se mohou nazvájem překrývat či doplňovat, a vypuštěním jednoho z nich vznikne text neúplný.
Pro zpracování v korpusu je ovšem potřeba multilineární interakci linearizovat, přičemž může vzniknout napětí mezi sledováním linie celého rozhovoru (v obrázku výše naznačené číslováním oranžových segmentů) a linie jednotlivých mluvčích (naznačené číslováním modrých uid). Korpusy mluveného jazyka ČNK upřednostňují první linii, která je věrnějším obrazem původní podoby rozhovoru (paralelně vedené segmenty se objeví těsně za sebou), nicméně ta druhá zůstává dostupná právě přes atribut uid.
Ukažme si, jak by vypadala část sondy z obrázku výše převedená do podoby zjednodušené vertikály, tj. podoby strukturně analogické výslednému korpusu. Segmenty jsou vymezené jako struktury <sp/>, jejich čísla jsou uvedená v atributu id. Ostatní řádky představují jednotlivé pozice, přičemž vždy uvádíme samotný token (v korpusech standardně označovaný atributem word) a po několika mezerách pak uid repliky, do které náleží:
<sp id="1"> ... WORD UID víš 1 co 1 </sp> <sp id="2"> si 2 vaří 2 svoje 2 jo 2 .. 2 </sp> <sp id="3"> hmm 3 hmm 3 </sp> <sp id="4"> to 2 je 2 chyba 2 </sp> <sp id="5"> ne 4 takže 4 ... </sp>
Všimněte si, že pozice s uid = 2 netvoří souvislou oblast vertikály, jsou přerušeny pozicemi s uid = 3 ze segmentu 3. Vidíme zde výše zmíněné napětí mezi dvěma způsoby linearizace v praxi: neexistuje způsob, jak segmenty za sebe poskládat tak, aby obě sekvence čísel id i uid byly zároveň monotonně neklesající.
Využití uid pro vyhledávání je bohužel poněkud krkolomné, nicméně ne nemožné. Vyžaduje znalost tzv. globálních podmínek. Následujícím způsobem můžeme např. najít všechny výskyty lemmatu pes nacházející se v okolí 100 pozic nalevo i napravo od výskytu lemmatu kočka, přičemž obě lemmata byla vyřčena v rámci téže repliky (tj. i téhož mluvčího) a je jedno, zda se při linearizaci mezi tyto dva výskyty dostala hranice segmentu:
(meet 1:[lemma="kočka"] 2:[lemma="pes"] -100 100) & 1.uid = 2.uid
Část dotazu, která formuluje požadavek, aby pozice náležely do stejné repliky, je právě globální podmínka & 1.uid = 2.uid.
Kromě proložení replikou jiného mluvčího mohou být repliky rozděleny na více segmentů i v případě, že jsou příliš dlouhé. I v takové situaci lze původní rozsah repliky identifikovat pomocí uid.




