

Toto je starší verze dokumentu!
Obsah
Specifika vyhledávání v diachronním korpusu
Při vyhledávání v korpusu Diakorp je třeba počítat s tím, že:
- korpus není lemmatizovaný ani morfologicky označkovaný (na rozdíl např. od korpusů řady SYN) - je tedy možné klást pouze dotazy vycházející z konkrétních lexikálních jednotek (nikoli z gramatických kategorií) a pro obecnější zadání (např. mohla v minulosti stát vokalizovaná předložka před slovem začínajícím na samohlásku?) je nutné využít klikacích voleb grafického rozhraní nebo přímo regulárních výrazů;
- texty jsou transkribované a pravidla přepisu se musela vyrovnat jak s dosavadní ediční praxí, tak s faktem, že se v průběhu sedmi staletí vývoje češtiny pravopisné systémy měnily - důsledkem je, že pravopisné jevy lze v korpusu zkoumat jen v omezené míře;
- jedno slovo (slovní tvar) může mít více variant (podobně jako v mluvených korpusech), např. tehdy - tehdyť - tehdyž - tehda - tehdaž - tehdať - tehdas - tehdá - tehdáž - některé z nich bývají uvedeny ve slovnících, je však vhodné zkontrolovat možnosti variant pomocí regulárních výrazů (např.
[word="(?i)tehd.*"])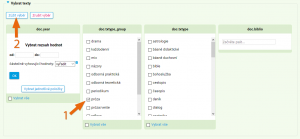 Výběr skupiny textů
Výběr skupiny textů

Jak se v korpusu snadno zorientovat?
Základní přehled o tom, co Diakorp obsahuje, můžeme získat po kliknutí na nabídku Specifikovat dotaz podle metainformací. Zobrazí se seznamy textových kategorií zastoupených v korpusu, obecnější skupina txtype_group a konkrétnější txtype. Pokud nás zajímá některá z kategorií, můžeme hledání rovnou omezit jen na ni.

Podobně je možné prohledávat pouze data z určitého časového období. K urychlení výběru textů podle roku vzniku (tj. aby nebylo nutné zaklikávat všechny jednotlivé roky) slouží textové pole, kam napíšeme počáteční a koncový rok (např. 1460 a 1620). Volbou částečně vyhovující hodnoty > vyřadit můžeme vyloučit texty, které do vybraného úseku patří jen vlivem nepřesné datace (např. 1450±10).
Jak v dotazu využít strukturního značkování textů?
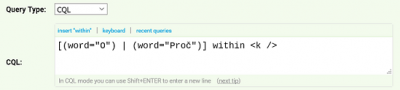
Značky vymezující zvláštní součásti textu (poznámky pod čarou <n></n>, verše <v></v>, nadpisy <k></k>, cizojazyčný text <o></o> ad.) jsou v Diakorpu verze 6 strukturními atributy a lze v jejich rámci hledat pomocí podmínky within. Můžeme např. zjistit, jak často začínaly nadpisy či součásti nadpisů v různých dílech tázacím příslovcem Proč, anebo předložkou O.
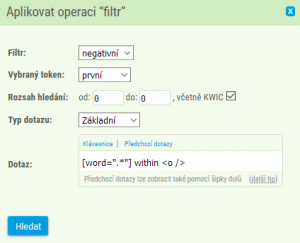
Pomocí strukturních atributů můžeme také odstranit ta vyhledaná klíčová slova (KWIC), která spadají do nežádoucí součásti textu. Hledáme např. slovní tvary s koncovou diftongizací -uo(v) a chceme odfiltrovat všechen cizojazyčný text (např. quo). Po zadání dotazu typu CQL [word=".*uov?"], kterým nalezneme slovní tvary končící jak na -uov, tak na -uo (zápis doslova říká, že koncové -v je „s otazníkem“), zvolíme v horní nabídce rozhraní KonText Filtr > Negativní a zapíšeme, co má být z konkordance vymazáno.
Zápis můžeme číst jako „vymaž jakékoli klíčové slovo (KWIC), které je součástí cizojazyčného textu“.
Počáteční (<k>) a koncovou část atributů (</k>) můžeme použít také samostatně, k vyhledání slovního tvaru stojícího na začátku nebo na konci daného textového úseku. Ani tehdy se strukturní atribut neuvádí v uvozovkách ani v jiných závorkách (např. CQL: <v> [word="A"] - kdy veršovaný úsek začíná spojkou A?)
Jak najít původní podobu upraveného slova?
Pokud se editor setkal s neočekávanou grafickou podobou slova a vyhodnotil tuto odchylku spíše jako záležitost pravopisu než fonologie, podobu slova upravil (emendoval) a původní, transliterovaný zápis uložil do pozičního atributu „e“. Tato informace je užitečná zejména ve dvou případech:
- hledáme v korpusu slovo, na které jsme narazili jinde a je rovněž neobvyklé, např. polowjce (polovina) - standardní dotazy žádný výskyt nenaleznou (např. Slovní tvar:
polovíce; CQL:[word="(?i)poloví[cč].*"]), ale dotaz na opravené podoby ano: CQL:[e="(?i)polowj[cč].*"]. Poziční atribut „e“ se zobrazuje i hledá podobně jako lemma, word a jiné známé atributy. - potřebujeme odfiltrovat emendovaná slova z konkordance - do
Filtr > Negativnízadáme podmínku „kdykoli atribut něco obsahuje“: CQL:[e=".+"](znak+je na místo znaku*právě proto, aby byl vyloučen nulový obsah).
První případ zmiňujeme i proto, že rozhodování mezi emendací (s uložením původní podoby), nebo pouhou transkripcí neprobíhalo u některých méně jasných případů zcela konzistentně (roli hrálo mj. množství editorů, různé stáří textů a rozdíly mezi edičními zásadami uplatňovanými na texty z různých období, doklady nalezené i mimo slovníky apod.). Uživatelům je doporučeno kontrolovat u variantních tvarů s kolísající délkou samohlásky i atribut „e“.




