

This is an old revision of the document!
Table of Contents
Treq

The Treq application serves for searching Czech - foreign language dictionaries, which have been automatically created based on data derived from the parallel corpus InterCorp. It enables users to search for all possible equivalents used in translations, or to find synonyms.
Treq is an online application (the only thing we need to use it is a web browser) and it is accessible without registration to all users at treq.korpus.cz.
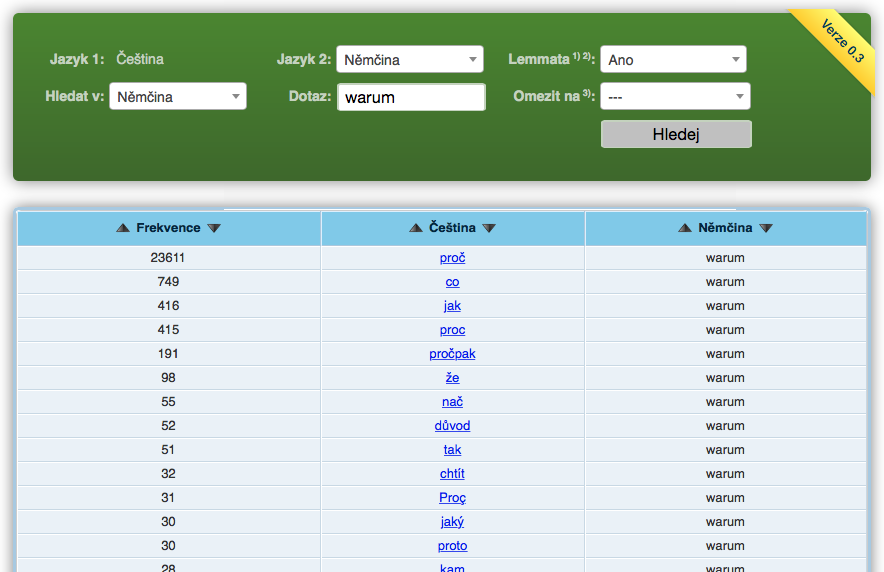
To use Treq, start by specifying the desired language pair by selecting source language (the language of the query) and target language (the language of the potential equivalents). The query can be entered either as a specific word form, as a lemma (Lemma), as a multiword unit (Multiword) or using regular expressions (RegEx). The query can also be made case insensitive (A = a). Depending on the Restrict to: parameter, result retrieval can target different text types: the fiction-oriented core texts, specific collections, or the entire corpus. Then enter your query (Query:) and click Search. The query result is a list of all translation candidates of the given word, sorted by decreasing frequency by default. By clicking on a particular candidate, you can browse its occurrences in InterCorp and check the translation contexts. The reported frequency may differ since the corpus query may also find instances where the potential equivalent corresponds to a different word.
Alignment principle
First of all, when preparing data for Treq, only sentences that are aligned 1:1 are selected from the entire corpus. We restrict ourselves to this simple alignment because it tends to be more reliable; especially in the case of automatically aligned texts, potential errors can be prevented.
The next step is to perform an automatic word-to-word alignment using GIZA++ 1). In older versions of Treq, a method called intersection was used, creating only such alignments where one word in the source language corresponds to one word in the target language, e.g.:


i.e. the first word in the source language (0) corresponds to the first word in the target language (0), the second word (1) corresponds to the third one (2) etc. Starting with release 2.0, apart from this simple alignment method the grow-diag-final-and method has also been used, as it allows to create more complicated alignments of more than one word on both sides of the translation. Such an alignment may look like this:


(Note the difference: the first word in the target language (0) now corresponds not only to the first (0), but also the second (1) word in the target language.) Z takovéhoto zarovnání je následně vybráno co největší množství kombinací slov, které toto zarovnání umožňuje (viz též příklad extrahovaných ekvivalentů níže). From such an alignment we choose, using a simple script, the largest possible number of combinations of words that this alignment allows. In both cases, the aligned pairs of (multiple) words are then sorted and summarized. The result of this automatic excerption is not revised in any way. However, the relative frequency of the corresponding pairs may serve as an indicator of the relevance of the equivalents. The more often the equivalent of the word or multi-word unit occurs in comparison with other equivalents, the greater the likelihood that it is a plausible translation.
The table below indicates in what proportion the frequencies found in the KonText with those displayed by Treq. It also specifies the different data types at each stage of their processing for Treq, considering the IC v9 English component (multi-word variant).
treq-tabulka.jpg_fixme_anglicka_verze
Po dílčích krocích lze sledovat postupný úbytek dat, která jsou ve výsledném slovníku použita. V prvním kroku použijeme pouze zarovnání vět 1:1 – tím přijdeme o 20,7 % vět. Následně se vyberou na základě zarovnání z programu GIZA++ víceslovné ekvivalenty. Vztah mezi velikostí původního korpusu a počtem vyextrahovaných ekvivalentů však nelze jasně předvídat, zvláště pak u víceslovných ekvivalentů, kde vznikají nejrůznější kombinace stejných slov (viz tučně vysázené dvojice níže). Takto by např. vypadal abecedně řazený soupis česko-anglických párů extrahovaných z druhé příkladové věty:
a – and
chybný – bad
krok – move
lidí – people
naštvalo – angry
považovalo – been widely regarded as
považovalo za – been widely regarded as
považovalo za – regarded a
se – made
Spoustu – lot of
to – This
to – very
za – regarded a
. – .
Ve třetím kroku se v rámci celého textu sečtou řádky, které jsou stejné na obou stranách zarovnání. Tak získáme seznam a frekvenci ekvivalentů. Nakonec, v závěrečném kroku, vyřadíme všechny protějšky obsahující interpunkci, čímž obdržíme finální verzi slovníku. U všech jazykových párů, kde je k dispozici lemmatizace na obou stranách zarovnání, aplikujeme stejný postup i na lemmatizovanou podobu dat (na počátek být stvořit vesmír . – in the beginning the universe be create .).
Application pictures

Related links
KonText interface • SyD • Morfio • KWords • Corpus Manager • Corpus tools




