

This is an old revision of the document!
Table of Contents
SyD
![]()
The SyD application (for the analysis of Synchronic and Diachronic variants) serves primarily to study competing linguistic phenomena. It serves as a supplementation of the more universal corpus managers, and can quickly and easily provide corpus results to lay users. As its name suggests, the application has two (essentially separate) parts:
- synchronic, in which it is possible to compare variants based on their frequency and distribution in the texts
- diachronic, in which it is possible to map the development tendencies in the use of the variants.
SyD is an online application (the only thing we need to use it is a web browser) and it is accessible without registration to all users at syd.korpus.cz.
It is currently available in the version 2.0, which was published in 2014 (the first version was launched in 2011). The application includes a concise manual, and the displayed results are accompanied by a detailed commentary. Just like in some of the other applications (e.g. in Morfio), a permanent link leading to the input query is available in SyDu making it appropriate for sharing and citing.
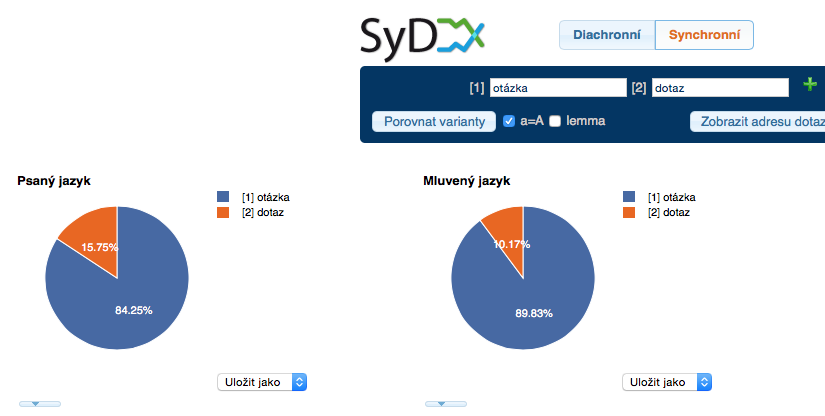
The Synchronic part
In the synchronic part the user can input two (or even more) phenomena which he wants to compare. The opposition may relate to their spelling (eg. filozofie vs. filosofie), or to their morphology (bychom vs. bysme), however it is also possible to study lexicological opposition (stále vs. pořád vs. furt), or even syntax and word order in general (sebe sama vs. sama sebe). The queries can be written very trivially (a simple input of the desired word will suffice) or with the help of a query language, CQL. The application will evaluate all queries and will display the results in the form of tables and graphs.
Corpora used in the SyD application (in the 2.0 version):
- SYN2010 for written (public) language
- KSK-Dopisy for written private (and informal) language
V synchronní části analýzy je možné využívat lemmatizaci (tj. dotazovat se na celý lexém včetně všech jeho tvarů), při vyhodnocování výsledků je však třeba obezřetnosti. Zatímco v korpusech řady SYN se využívá standardní lemmatizace, data pro mluvenou češtinu a pro korespondenci lemmatizována nejsou a je zde proto rozsah lemmatu odhadován na základě psaného jazyka (dotaz je nejprve vyhodnocen v korpusu SYN2010 a na základě tvarů v něm identifikovaných je sestaven dotaz pro nelemmatizované korpusy).
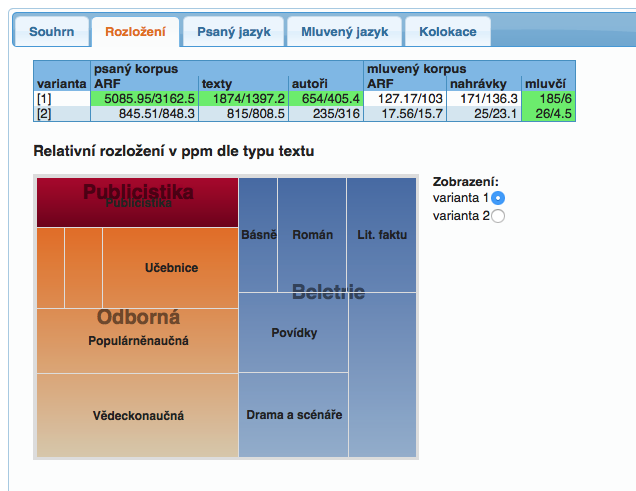
Synchronní část poskytuje informaci o rozložení jevů v psaných textech (na základě strukturních atributů txtype a genre) i v mluveném jazyce (na základě atribtutů pohlaví, věk, vždělání a regionální příslušnost). Všechny údaje jsou relativizovány s ohledem na velikost dané kategorie v korpusech.
Pro analýzu lexikálních odlišností zkoumaných variant poskytuje aplikace SyD i zjednodušenou verzi kolokačních paradigmat k jednotlivým dotazům.
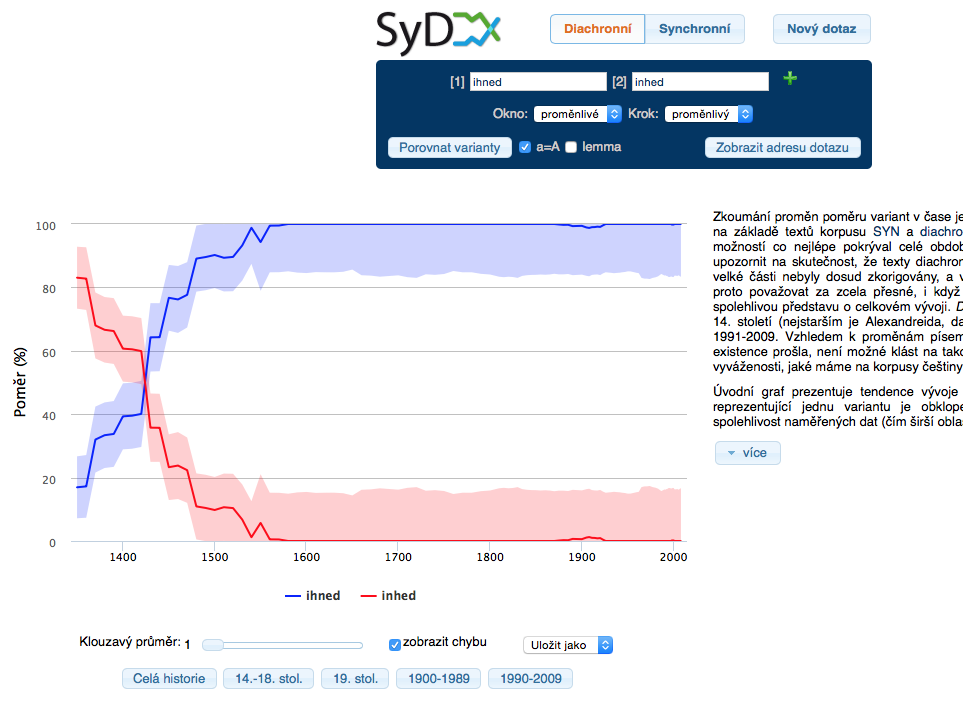
The Diachronic part
The basis for the diachronic analysis is the Diakon corpus which is composed of the Diakorp corpus texts, expanded upon with data from earlier forms of Czech which have not yet been reviewed manually. A makeshift list of source texts before the year 1989 is available in the lists section. The most modern period is represented by a selection from the synchronic corpora of the SYN series. Due to the fact that the older texts are not yet lemmatized, it is possible to use only the word attribute (word form) for queries.
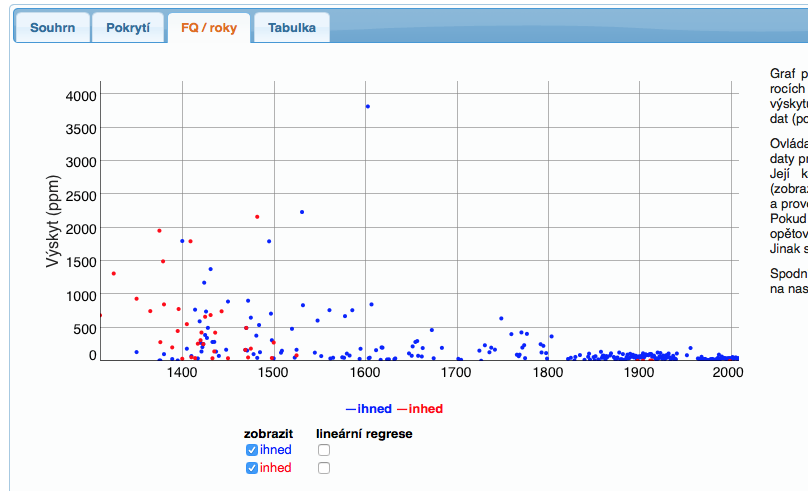
Aplikace SyD všechny zadané dotazy vyhodnotí a zjistí jejich relativní frekvenci v různých letech. Vzhledem k tomu, že pokrytí časové osy stále není optimální, je třeba brát časové údaje spíše orientačně a pro zobrazení trendů se užívá klouzavý průměr (s nastavitelným oknem). Zobrazení na časové ose obsahuje navíc ještě i míru chyby, s níž je třeba při analýze dat počítat.
Application images

Related links
KonText Interface • Morfio • KWords • Treq • Corpus Manager • Corpus Tools




