

This is an old revision of the document!
Table of Contents
KWords
![]()
The KWords application is used for the analysis of texts based on their comparison with the general usage (reference corpus). Its aim is to identify so-called keywords, which are word forms appearing in the inspected text with a significantly higher frequency than in the reference corpus which should reflect the common usage. These key words serve as a basis for textual analysis and interpretation.
KWords is an online application (the only thing we need to use it is a web browser) and it is accessible without registration to all users at kwords.korpus.cz.
The KWords applcation was originally created for the purpose of analyzing political speeches, and is being developed further in cooperation with Brown University. It is currently implemented for the analysis of Czech and English texts of up to approx. 20 thousand words.
Prominent units
The KWords application identifies two types of prominent words:
- (Keywords)
- Words bearing the thematic concentration (TC) of the text
Keywords
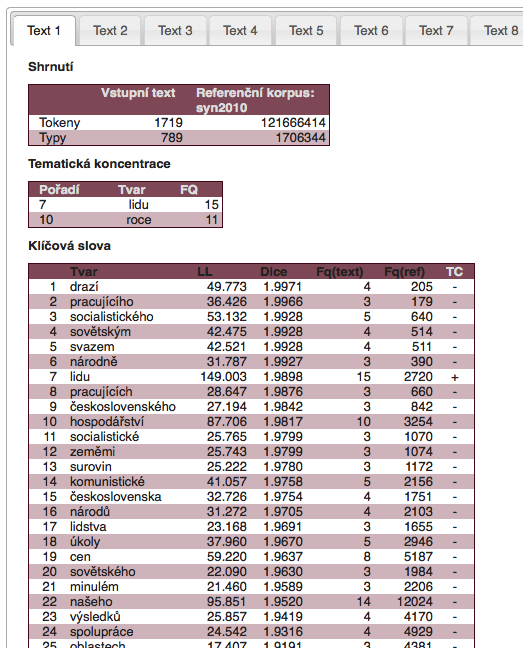
The identification of keywords takes place based on a comparison of each word's relative frequency in the given text with the same word's relative frequency in the reference corpus. Several tests are used to determine the statistical significance of the differences, two of which are implemented in KWords: chi2 and log-likelihood. Keywords in the analyzed text are marked red.
The results of the keyword analysis are always influenced by the choice of reference corpus, which should be seen as a neutral language background with which we compare the analyzed text. For example, when analyzing the New Year speeches of the last Communist president G. Husák, we notice that compared to current usage there is a high frequency of words such as socialistický (socialistic), soudružky (comrades) etc., but this i not the case when compared to a reference corpus from the same period. Currently, the following reference corpora can be used in the KWords application:
- for Czech
- diakon19 – ad hoc corpus created from available data in the diachronic part of the CNC covering the 19th Century
- totalita – a corpus of ideological texts and official journalism from the period of Communist totalitarianism
- for English
- BNC – British National Corpus
- InterCorp-EN v8 – the English section of the parallel corpus InterCorp
Thematic concentration
Words which are highlighted in yellow in the analyzed text are those which bear thematic concentration (TC words). They are not identified through comparison with a reference corpus, but only by their placement in the frequency distribution of the units in the analyzed text: when we arrange all the words in the text from those which are most frequent and down to words which appear only once, we get a so-called Zipf distribution. In this distribution we are looking for a so-called h point, for which we can say that rank = frequency (e.g. 32nd most frequent word has a frequency of 32 occurrences). All autosemantic words (bearing meaning independent of context) above this point (i.e. in our case with a frequency higher than 32) we label thematic concentration. More details and a specific application of this approach to literary texts can be found for example in the article of R. Čech (2013).
Princip fungování
Text vložený uživatelem se nejprve roztokenizuje způsobem, který je identický s tokenizací korpusových dat. V druhém kroku je spočtena frekvence všech slov v analyzovaném textu (s výjimkou těch, které uživatel z analýzy vyloučí prostřednictvím tzv. stop-listu, např. předložky, spojky, čísla apod.). Následuje porovnání frekvencí v textu a v referenčním korpusu. Pro jednotky, u nichž byl zaznamenán statisticky signifikantní rozdíl (podle zvoleného statistického testu – chi2 či log-likelihood), je dále vypočítána hodnota DIN (difference index) vypovídající o relevanci daného rozdílu:
$$DIN = 100 \times \frac{RelFq(Ttxt) - RelFq(RefC)}{RelFq(Ttxt) + RelFq(RefC)}$$
kde $RelFq(Ttxt)$ je relativní frekvence jevu ve zkoumaném textu (target text) a $RelFq(RefC)$ je relativní frekvence téhož jevu v referenčním korpusu. Hodnoty DIN, podle nichž jsou klíčová slova ve výpisu programu seřazena, mohou dosahovat hodnot od -100 do 100, přičemž platí, že:
- hodnota -100 znamená, že daný jev se ve zkoumaném textu nevyskytuje, je pouze v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 0 znamená, že daný jev má zhruba stejnou relativní frekvenci ve zkoumaném textu i v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 100 značí, že slovo se vyskytuje pouze ve zkoumaném textu (může se tedy jednat o velmi prominentní slovo1))
V textech o rozsahu do 20 tisíc slov a při analýze slovních tvarů je možné považovat hodnoty DIN v rozmezí 75-100 za velmi zajímavé a značí, že se jedná pravděpodobně o prominentní jednotku, která může dobře posloužit jako východisko pro interpretaci celého textu.
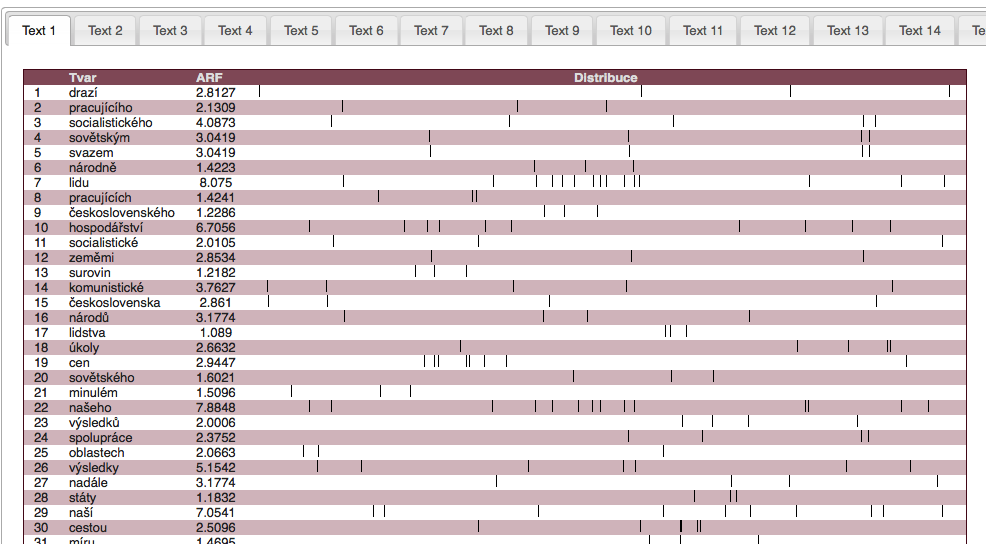
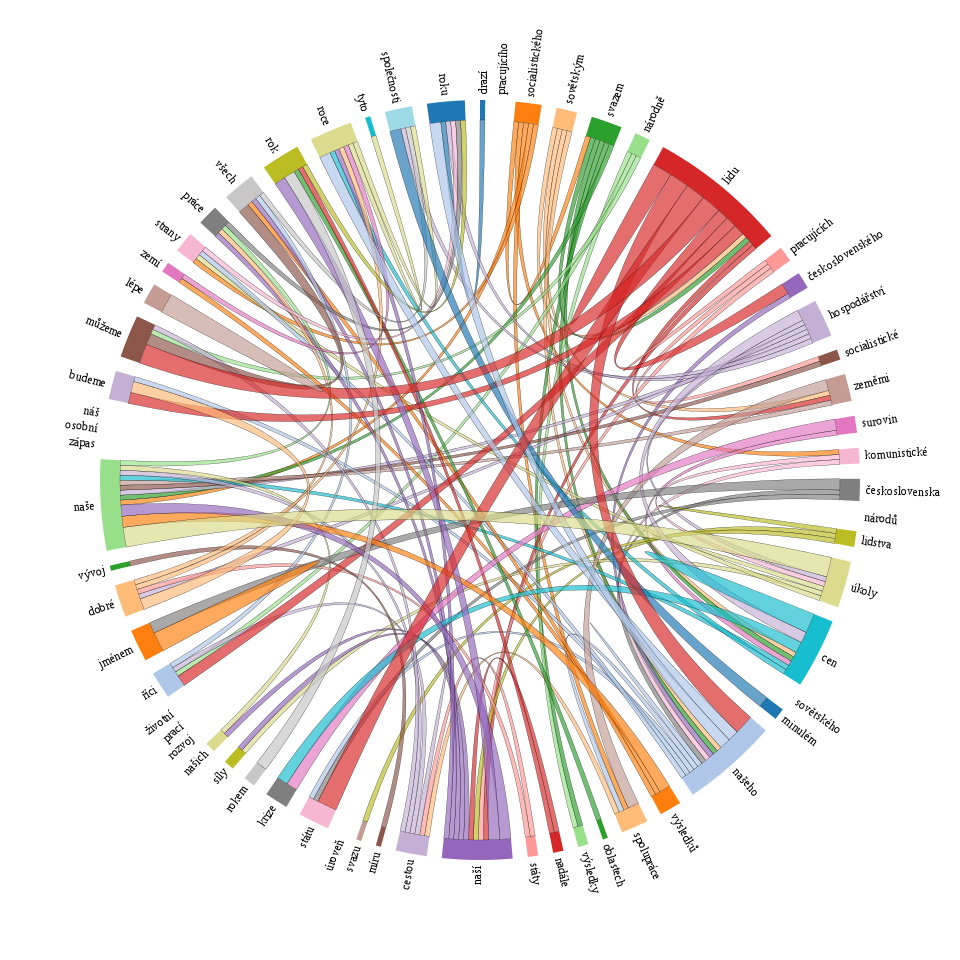
Aplikace KWords dále nabízí celou řadu doplňujících informací pro práci s klíčovými slovy. Vedle seznamu klíčových slov spolu s jejich hodnotami je to především graf disperze dat (ukazující postavení jednotlivých klíčových slov v textu), graf tzv. keyword links, tj. vztahů mezi klíčovými slovy v textu a také konkordanci klíčových slov pro analýzu jejich bezprostředního okolí.
Aplikace KWords byla navržena také pro vytváření analýz časových (nebo jiných) sérií dat. Pokud uživatel vloží na vstupu do aplikace víc textů (maximální množství je 20), aktivuje režim tzv. multi-analýzy. V něm jsou analyzovány všechny vložené texty a výsledky z jednotlivých analýz porovnány na základě DIN.
Application images

Related links
KonText interface • SyD • Morfio • Treq • Corpus manager • Corpus tools




