

WaG: Slovo v kostce
![]()
Aplikace Slovo v kostce (Word at a Glance, WaG) slouží k vytvoření základního přehledu o tom, jak se používá zadané slovo či sousloví. Soustředí v sobě informace, které lze získat z korpusů ČNK pomocí dostupných nástrojů, a vytváří tak přehledný profil slova z různých perspektiv.
Aktuálně je WaG implementován pouze pro české zdroje a obsahuje tři základní moduly:
- profil slova či víceslovné jednotky v češtině (modul Vyhledat slovo)
- komparace profilů dvou (či více) českých slov či sousloví (modul Porovnat slova)
- informace o možných překladech zadaného slova do jiných jazyků (modul Hledat ve dvou jazycích)
Výsledky analýzy zadaného slova jsou v aplikaci uspořádány do dlaždic. Každá dlaždice obsahuje informaci o tom, z jakého zdroje údaje pocházejí, odkaz vedoucí do některé z aplikací pro práci s korpusy ČNK, kde lze zpravidla vyhledat detailnější údaje, a rovněžstručná nápověda, která poskytuje dodatečné informace o zdrojích dat a o možnostech interpretace výsledků. V některých případech lze údaje v dlaždici zobrazit ve formě tabulky či upravit výsledky dodatečným nastavení volitelných parametrů. Dlaždice jsou seskupeny do tematických celků (Frekvenční informace, Psaný jazyk, Mluvený jazyk).
Všechny prezentované údaje jsou získány automatickou analýzou – přesnost a věrohodnost frekvenčních informací závisí na tom, jak spolehlivá je anotace v korpusech. Klíčová je přitom především role lemmatizace (tj. přiřazení základního tvaru) a morfologického značkování, jejichž chybovost ani s použitím nejmodernějších nástrojů nemůže být nulová. Pro podrobné a spolehlivé vyhodnocení je tedy klíčové ověřovat výsledky ve zdrojových datech, a to zejména s ohledem na adekvátnost anotace.
Aplikace je dostupná na adrese: https://www.korpus.cz/slovo-v-kostce/ nebo přímo z dotazovacího okna na hlavní straně portálu ČNK.
Přehled jednotlivých prvků
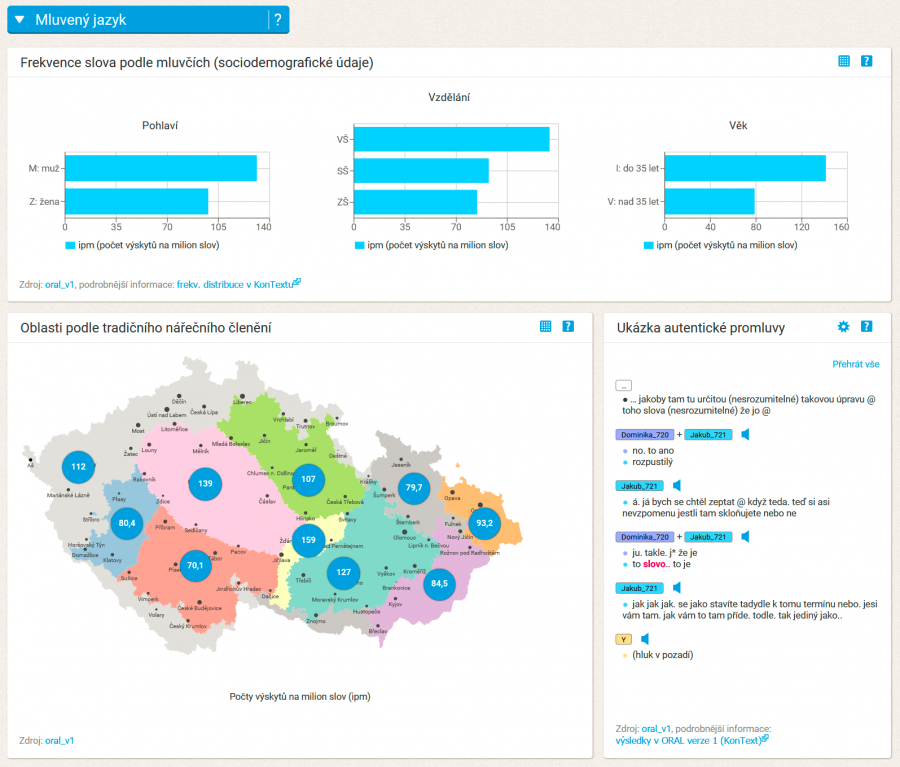
Frekvenční informace
Lemma
ukazuje, jak jsme zadané slovo interpretovali. Pokud jste zadali slovo v jiném než základním tvaru (například kočku), základní tvar neboli lemma jsme mu přiřadili (kočka). Vyhledány jsou pak všechny tvary tohoto slova (tedy kočky, kočce, kočkách atd.). Případné ostatní interpretace se zobrazí nahoře pod vyhledávacím políčkem, kde lze také vybrat, jakou interpretaci chcete dále analyzovat (např. tvar sní může být zařazen k lemmatu snít nebo k lemmatu sníst).
Slovní druh
Zadané slovo bylo námi určitým způsobem interpretováno a přiřazeno k určitému slovnímu druhu. Výsledek je vhodné překontrolovat, zvláště hledáte-li slovo, které může mít více významů (například stát může být slovesem nebo podstatným jménem). Podobně jako v předchozím případě se vám naše interpretace nemusí líbit, vtom případě si ji můžete snadno změnit nahoře pod vyhledávacím políčkem.
Frekvenční pásmo
názorně ukazuje, jak frekventované dané slovo je, tj. jak často ho najdete v českých psaných textech. Čím víc má hvězdiček, tím je častější. Pět hvězdiček má jen velmi malý počet slov, která se ale v psaných textech vyskytují mimořádně často, např. ale, já nebo muset. Čtyři hvězdičky mají velmi častá slova jako český, slovo nebo psát. Naopak jednu hvězdičku mají málo frekventovaná slova, např. chichotání, rozřezávat, pálenice nebo reverzibilní.
Kolikrát v milionu slov
Údaj podobně jako frekvenční pásmo (nebo ipm) ukazuje, jak často se s daným slovem setkáte – zde v přepočtu na korpus o velikosti 1 milion slov. Například hodnota 10 000 znamená, že přibližně každé sté slovo v českých textech bude vámi hledaný výraz, tedy že ho najdete na jedné stránce třeba i několikrát. Hodnota 1 znamená, že se zadané slovo vyskytuje průměrně v milionu slov jen jednou , tzn. že byste museli přečíst třeba i několik tlustých románů, než byste na něj vůbec narazili. (Pro představu, jedno z nejčastějších českých slov že má hodnotu ipm 7923, na druhou stranu slovo kvadrant má ipm 1)
Slova s podobně častým výskytem
je seznam výrazů, které najdete v textech přibližně stejně často jako vámi hledané slovo. Tento výčet není úplný, jde pouze o náhodný výběr z podobně frekventovaných slov.
Slovní tvary
Vyhledány jsou všechny tvary zadaného slova. Pokud jste tedy do vyhledávacího políčka napsali kočka, vyhledali jsme i pádové tvary kočky, kočce, kočkách atd. Četnost těchto tvarů je graficky znázorněna velikostí písma: čím větším písmem je zaznamenán učitý tvar, tím častěji na něj v textech narazíte (barvy jsou vybírány náhodně).
Pomocí ikonky v pravém horním rohu si lze dlaždici přepnout do režimu tabulky. Tak se můžete podívat nejenom na relativní četnost (procentuální zastoupení) jednotlivých tvarů, ale i na absolutní počet, tedy kolikrát jsme daný slovní tvar našli v korpusu SYN2015.
Frekvence podle typu textu
Z grafu je patrné, v jakém typu textů se vyhledané slovo používá nejčastěji. Údaje jsou uváděny v relativní frekvenci, absolutní četnosti výskytů jsou k dispozici v tabulce.
Tip: Pro srovnání si můžete vyhledat slova, která se typicky vyskytují v jednom z typů textů, např.: premiér, nebesa, experiment, prostě.
Psaný jazyk
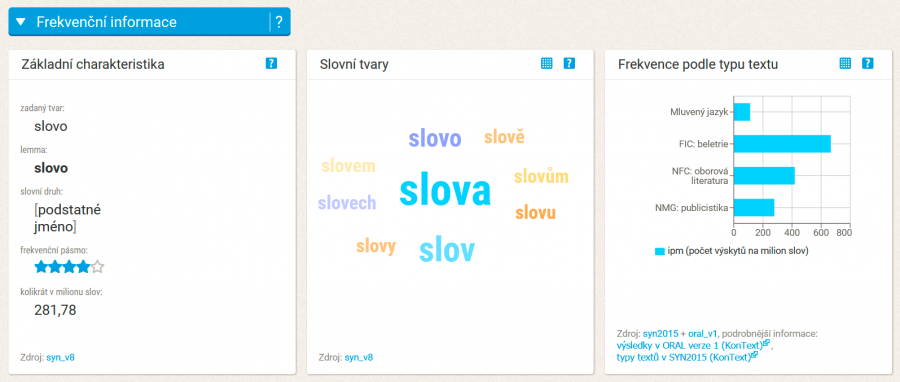
Kolokace
Kolokace jsou ustálená (tj. nenahodilá) smysluplná spojení slov v blízkém kontextu. Příkladem můžou být třeba kolokace letní prázdniny, zavázat (si) tkaničky, hladká mouka, vypálit (někomu) rybník nebo tmavě modrá. K nalézání kolokací se užívají statistické metody (tzv. asociační míry). Čím větším písmem je dané slovo zaznamenáno, tím silnější kolokaci se zadaným slovem tvoří (barvy jsou vybírány náhodně).
Kliknutím na ikonku nastavení můžete omezit prohledávaný kontext pouze na levou, či pravou stranu. Najetím kurzoru na konkrétní slovo se podbarví odpovídající příkladová věta v dlaždici vpravo. (Pozor! Kolokace může překračovat hranici věty, a kolokát se tudíž nemusí v příkladové větě objevit.)
Příklady použití kolokací v autentických psaných textech vidíte na vedlejší dlaždici Ukázky kolokací v textech. Informační ikonka skrývá údaje o textu (např. autor, rok vydání, typ textu).
Frekvence výskytu slova v čase
Graf naznačuje trend v užívání slova za poslední dvě desetiletí, především však v jazyce publicistiky (která tvoří cca 90 % korpusu SYN verze 7). Hodnoty za jednotlivé roky zaznamenávají počet výskytů v milionu slov.
Tloušťka čáry v grafu se odvozuje od tzv. konfidenčního intervalu, který udává, jak spolehlivá data pro výzkum zadaného jevu máme. Čím je čára tlustší, tím méně spolehlivá data pro identifikaci daného trendu máme.
Kliknutím na ikonku nastavení můžete výsledky porovnat s vývojem jiného slova (porovnejte např. slova média a tisk).
Podobně používaná slova
Dlaždice ukazuje slova, která jsou kontextově podobná slovu zadanému. Vzhledem k tomu, že kontext slova lze chápat jako věrné zrcadlo jeho funkce a významu, můžeme předpokládat, že slova vstupující do společných kontextů mají také podobný význam či funkci.
Pro určení podobných slov byl použit program Wang2Vec (alternativa k známějšímu Word2Vec) s metodou pro výpočet parametrů modelu Noise Contrastive Estimation.
Mluvený jazyk
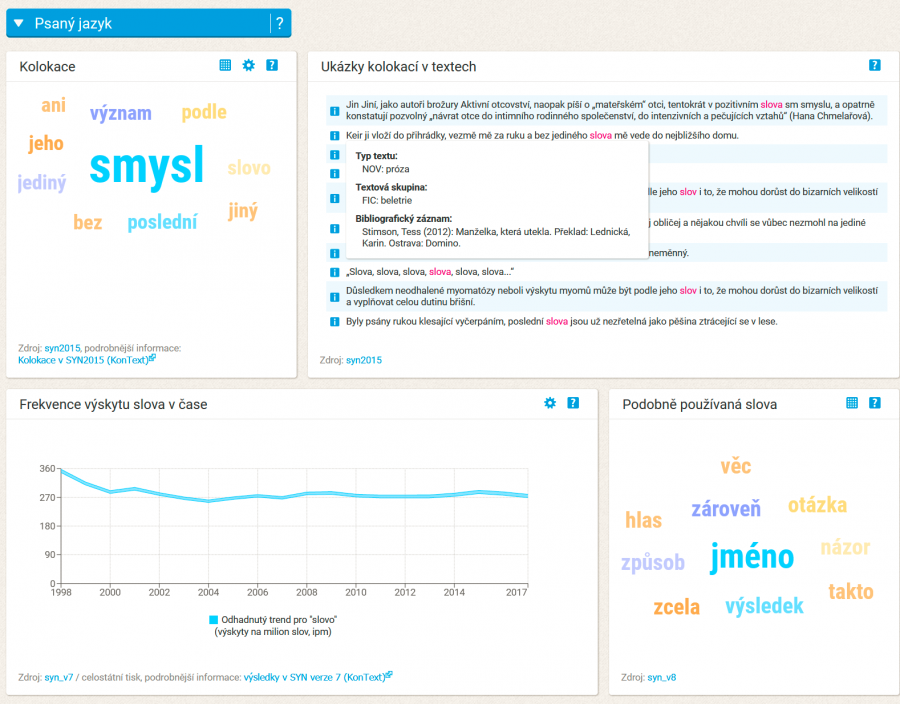
Frekvence slova podle mluvčích (sociodemografické údaje)
Z grafů je patrné, jak často je zadané slovo používáno skupinami mluvčích podle pohlaví, věku a nejvyššího dosaženého vzdělání. Pro představu si můžete vyhledat slova jako vole (lemma vůl), princip nebo řasenka. Všechny frekvenční údaje jsou uváděny v ipm.
Oblasti podle tradičního nářečního členění
Mapa znázorňuje používání zadaného slova v různých nářečních oblastech ČR. Konkrétní nářeční oblast se zobrazí po najetí kurzoru na růžový ovál s informací o frekvenci. Frekvenční údaje jsou uváděny v ipm. Pro představu si můžete vyhledat slova slunko a sluníčko, případně dobře známou dvojici hele a tož, případně podkrkonošské kyselo. Vymezení jednotlivých oblastí je kombinací tradičního nářečního členění podle Jaromíra Běliče a dělení používaného v Českém jazykovém atlase. Pomocí ikonky v pravém horním rohu si můžete dlaždici přepnout do režimu tabulky.
Ukázka autentické promluvy
Ukázky použití slova v autentických promluvách, jak je máme zachyceny v korpusu mluvené češtiny Oral. Kliknutím na šipky směrem nahoru a dolů rozšíříte vybranou ukázku, šipka doprava vybere novou ukázku. Kliknutím na ikonku reproduktoru si lze přehrát krátkou část ukázky, pokud chcete přehrát ukázku celou, klikněte na Přehrát vše.
Překlad na základě paralelního korpusu
Doložené překlady
Dlaždice ukazuje překladové ekvivalenty získané pomocí nástroje Treq, jenž využívá data paralelního korpusu InterCorp. Treq automaticky vyhodnocuje kandidáty na překladové ekvivalenty a řídí se pravidlem, že čím se častěji konkrétní překlad vyhledávaného slova v korpusu objevil, tím je větší pravděpodobnost, že se běžně používá. Výsledek není tedy ručně ověřován. Velikost písma souvisí s četností překladu daného ekvivalentu.
Překlad v různých typech textu
Zde se lze podívat na přehled různých překladů podle jednotlivých typů textů, které často souvisí s jiným kontextem. Např. jinak se bude překládat do angličtiny lexém hustý v publicistice (dense), a jinak ve filmových titulcích (cool). Díky tomuto srovnání lze nahlížet nejen na samotný překladový ekvivalent, ale i na jeho vhodnost s ohledem na určitý žánr.
Ukázky překladu
Ukázky překladu v paralelních textech pocházejí z korpusu InterCorp. Informační ikonka skrývá údaje o textu (např. autor, rok vydání, typ textu)
Jak citovat WaG
Tomáš Machálek (2019): Slovo v kostce – agregátor slovních profilů. FF UK, Praha. Dostupný z WWW: <http://korpus.cz/slovo-v-kostce/>.
Tomáš Machálek (2020): Word at a Glance: Modular Word Profile Aggregator. In: Proceedings of LREC 2020, s. 7011–7016.




