

Toto je starší verze dokumentu!
Obsah
KWords
![]()
Aplikace KWords slouží k analýze textů na základě jejich srovnání s obecným územ (referenčním korpusem). Jejím cílem je identifikovat tzv. klíčová slova (keywords), což jsou slovní tvary nebo lemmata, která se ve zkoumaném textu objevují významně častěji než v referenčním korpusu, který má zrcadlit běžný jazykový úzus. Tato klíčová slova slouží pak jako základ pro textovou analýzu a interpretaci.
KWords je webová aplikace (k jejímu užívání stačí internetový prohlížeč) a je dostupná bez registrace všem uživatelům na adrese kwords.korpus.cz.
První verze aplikace KWords byla vyvinuta pro účely analýzy politických projevů v rámci spolupráce s Brownovou univerzitou. Druhá verze vznikla v rámci projektu Threat-defuser. Tato verze podporuje více než 30 jazyků a umožňuje vedle analýzy klíčových slov i tzv. keymorph analýzu.1)
Prominentní jednotky
Aplikace KWords identifikuje dva typy prominentních slov:
- Klíčová slova (keywords)
- Slova nesoucí tématickou koncentraci (TC) textu
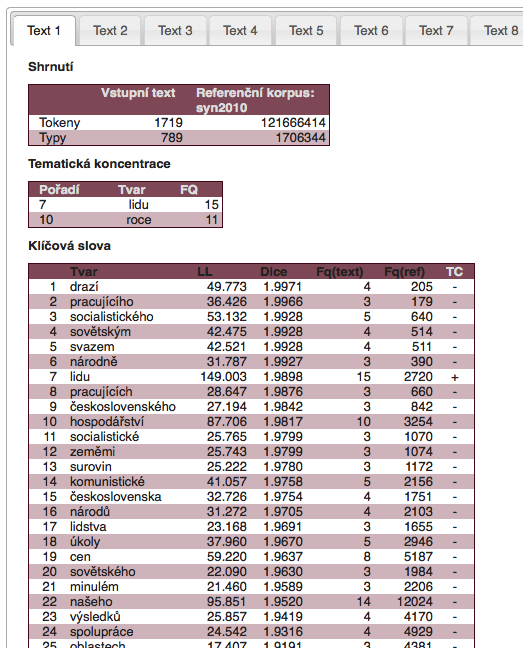
Klíčová slova
Identifikace klíčových slov probíhá na základě srovnání relativní frekvence každého slova ve zkoumaném textu s relativní frekvencí téhož slova v referenčním korpusu. Pro zjištění statistické signifikance rozdílů se užívá několik testů, v rámci KWords jsou implementovány dva: chi2 a log-likelihood.
Výsledky analýzy klíčových slov jsou vždy ovlivněny volbou referenčního korpusu, který je třeba chápat jako neutrální jazykové pozadí, s nímž porovnáváme zkoumaný text. Např. při zkoumání novoročních projevů posledního komunistického prezidenta G. Husáka se jako prominentní ve srovnání se současným územ jeví slova socialistický, soudružky apod., nikoli ovšem při srovnání s dobovým referenčním korpusem. Jako referenční korpus je v aplikaci KWords v současné době možné použít jazykové větvě korpusu InterCorp.
Tématická koncentrace
Slova, která jsou v analyzovaném textu vyznačena žlutým podbarvením, jsou ta, která nesou tématickou koncentraci (TC words). K jejich identifikaci se nevyužívá srovnání s referenčním korpusem, ale pouze jejich umístění ve frekvenční distribuci jednotek analyzovaného textu: seřadíme-li všechna slova v textu od nejfrekventovanějšího po slova, která se objevují pouze jednou, dostaneme tzv. Zipfovskou distribuci. Na této distribuci hledáme tzv. bod h, pro nějž platí, že rank = frekvence (např. 32. nejfrekventovanější slovo má frekvenci 32 výskytů). Všechna plnovýznamová slova nad tímto bodem (tj. v našem případě s frekvencí vyšší než 32) označíme za tématickou koncentraci. Podrobnosti a konkrétní aplikaci tohoto přístupu na literární texty je možné najít např. v článku R. Čecha (2013).
Princip fungování
Text vložený uživatelem se nejprve roztokenizuje způsobem, který je identický s tokenizací korpusových dat. V druhém kroku je spočtena frekvence všech slov v analyzovaném textu (s výjimkou těch, které uživatel z analýzy vyloučí prostřednictvím tzv. stop-listu, např. předložky, spojky, čísla apod.). Následuje porovnání frekvencí v textu a v referenčním korpusu. Pro jednotky, u nichž byl zaznamenán statisticky signifikantní rozdíl (podle zvoleného statistického testu – chi2 či log-likelihood), je dále vypočítána hodnota DIN (difference index) vypovídající o relevanci daného rozdílu:
$$DIN = 100 \times \frac{RelFq(Ttxt) - RelFq(RefC)}{RelFq(Ttxt) + RelFq(RefC)}$$
kde $RelFq(Ttxt)$ je relativní frekvence jevu ve zkoumaném textu (target text) a $RelFq(RefC)$ je relativní frekvence téhož jevu v referenčním korpusu. Hodnoty DIN, podle nichž jsou klíčová slova ve výpisu programu seřazena, mohou dosahovat hodnot od -100 do 100, přičemž platí, že:
- hodnota -100 znamená, že daný jev se ve zkoumaném textu nevyskytuje, je pouze v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 0 znamená, že daný jev má zhruba stejnou relativní frekvenci ve zkoumaném textu i v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 100 značí, že slovo se vyskytuje pouze ve zkoumaném textu (může se tedy jednat o velmi prominentní slovo2))
V textech o rozsahu do 20 tisíc slov a při analýze slovních tvarů je možné považovat hodnoty DIN v rozmezí 75-100 za velmi zajímavé a značí, že se jedná pravděpodobně o prominentní jednotku, která může dobře posloužit jako východisko pro interpretaci celého textu.
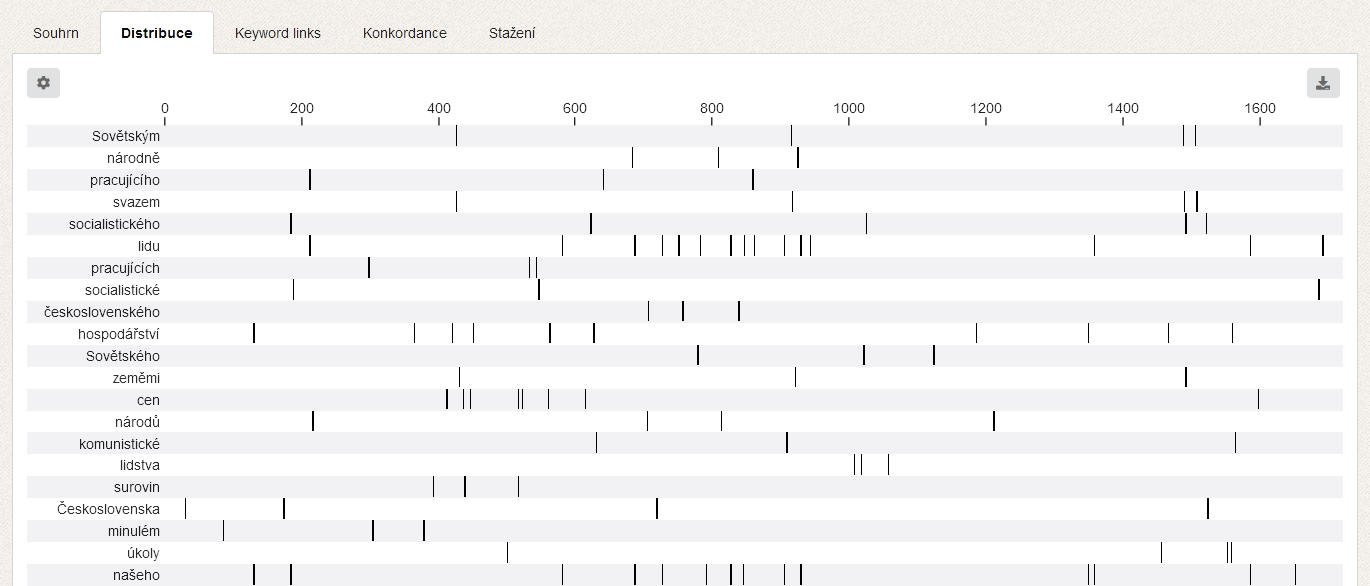
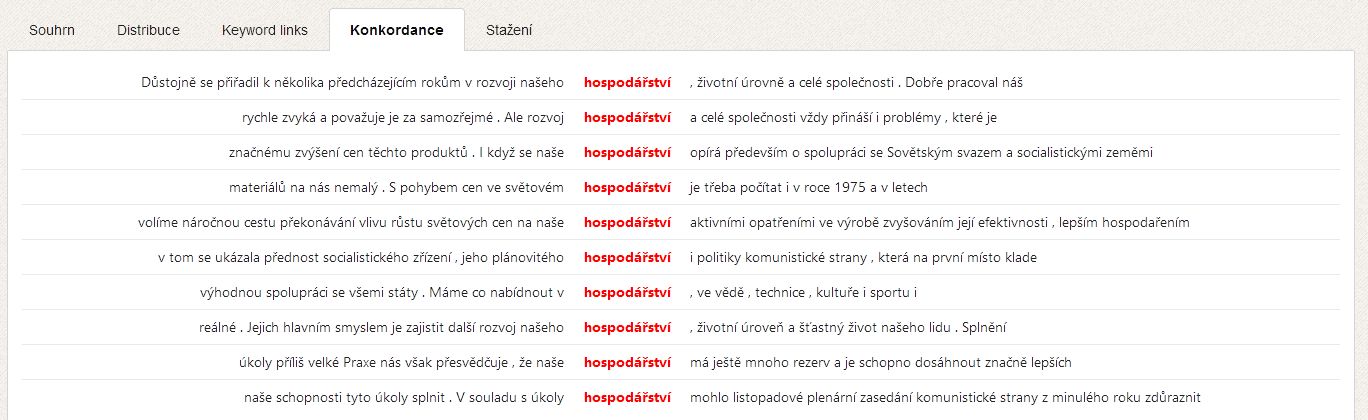
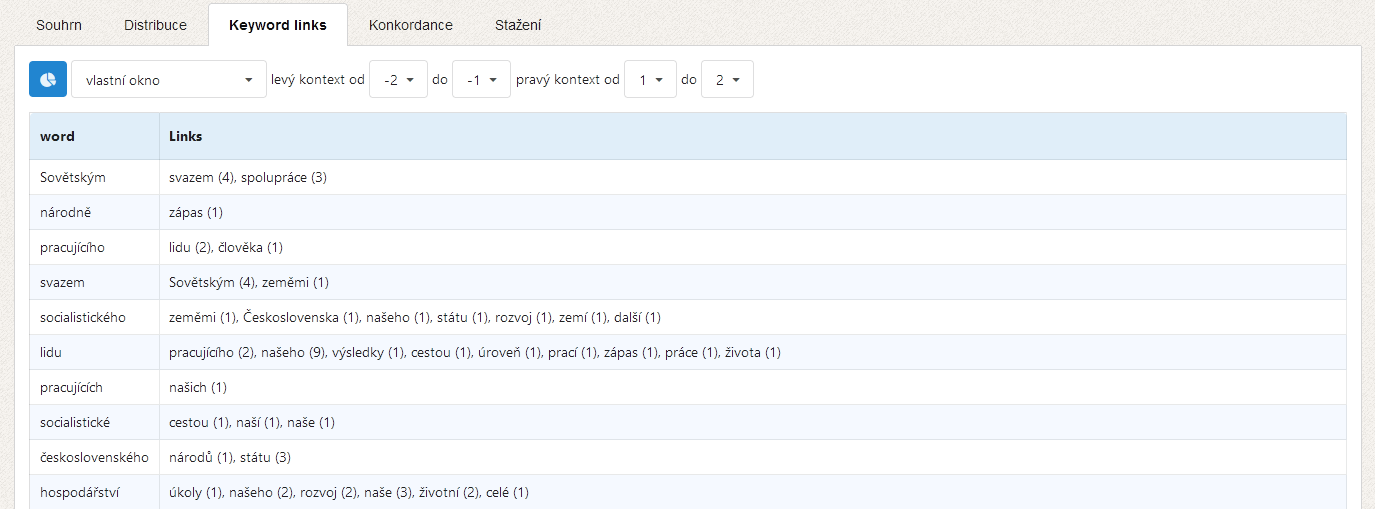
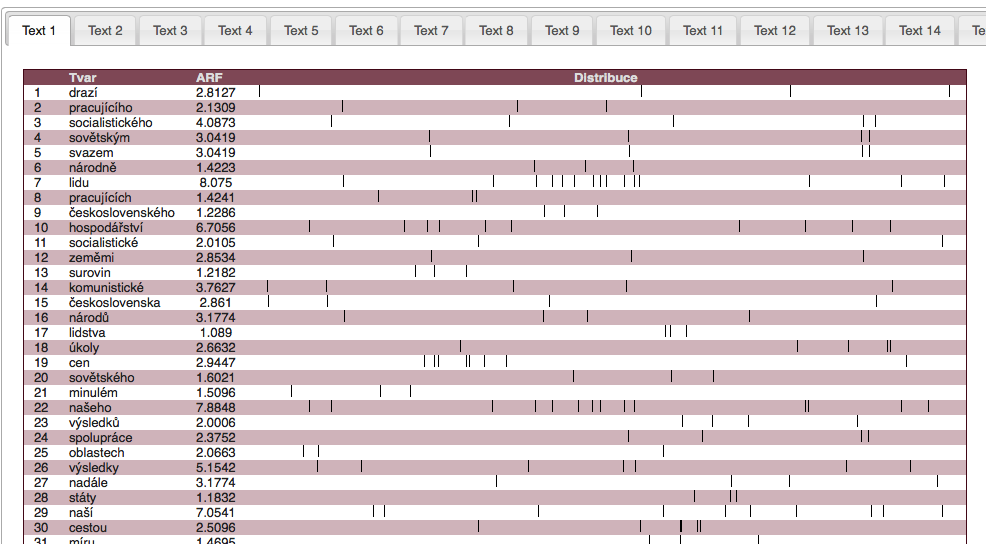
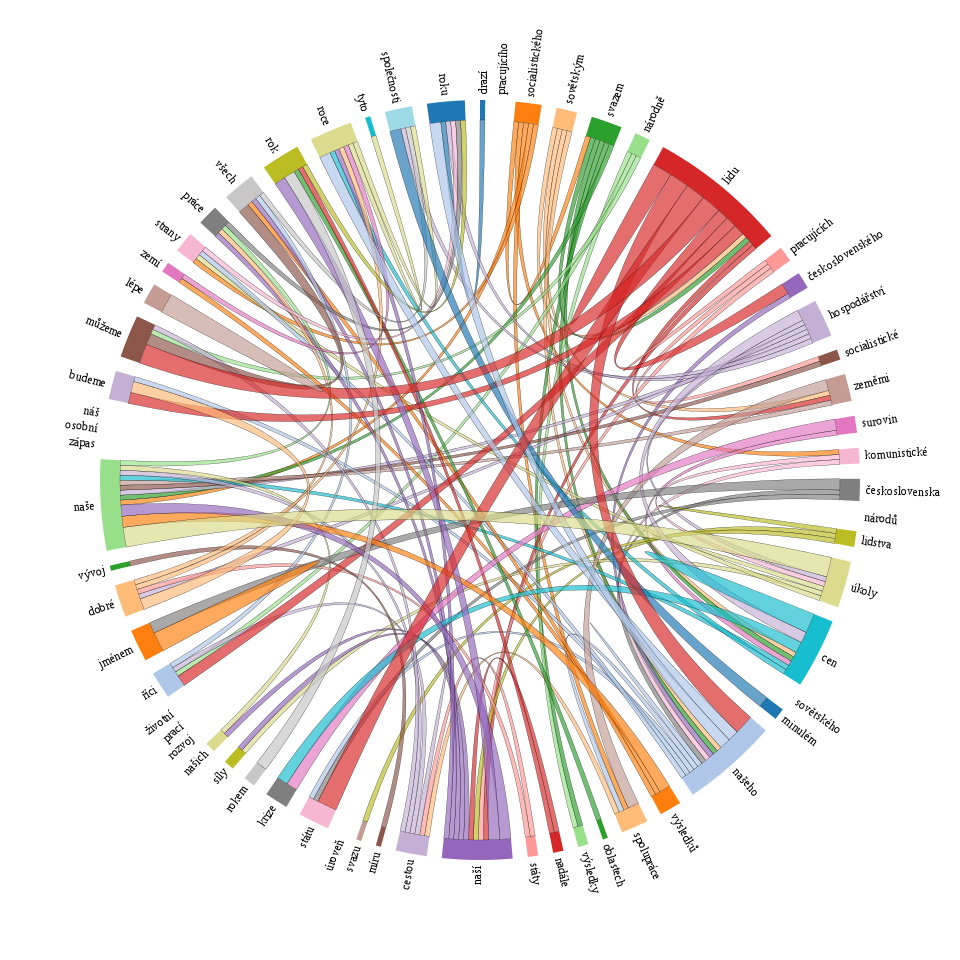
Aplikace KWords dále nabízí celou řadu doplňujících informací pro práci s klíčovými slovy. Vedle seznamu klíčových slov spolu s jejich hodnotami je to především graf disperze dat (ukazující postavení jednotlivých klíčových slov v textu), graf tzv. keyword links, tj. vztahů mezi klíčovými slovy v textu a také konkordanci klíčových slov pro analýzu jejich bezprostředního okolí.
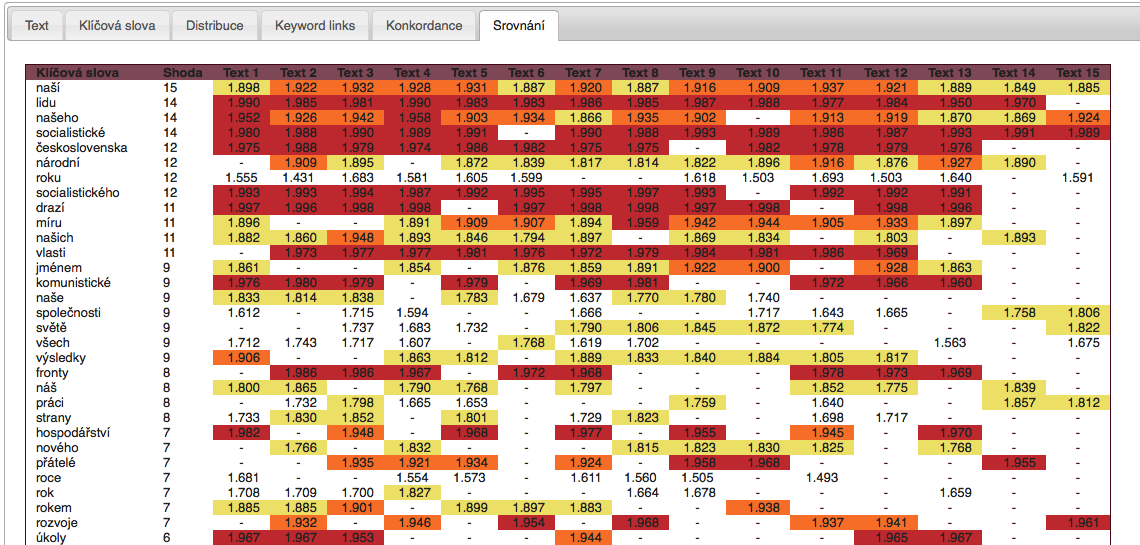
Aplikace KWords byla navržena také pro vytváření analýz časových (nebo jiných) sérií dat. Pokud uživatel vloží na vstupu do aplikace víc textů (maximální množství je 20), aktivuje režim tzv. multi-analýzy. V něm jsou analyzovány všechny vložené texty a výsledky z jednotlivých analýz porovnány na základě DIN.
Obrázky aplikace
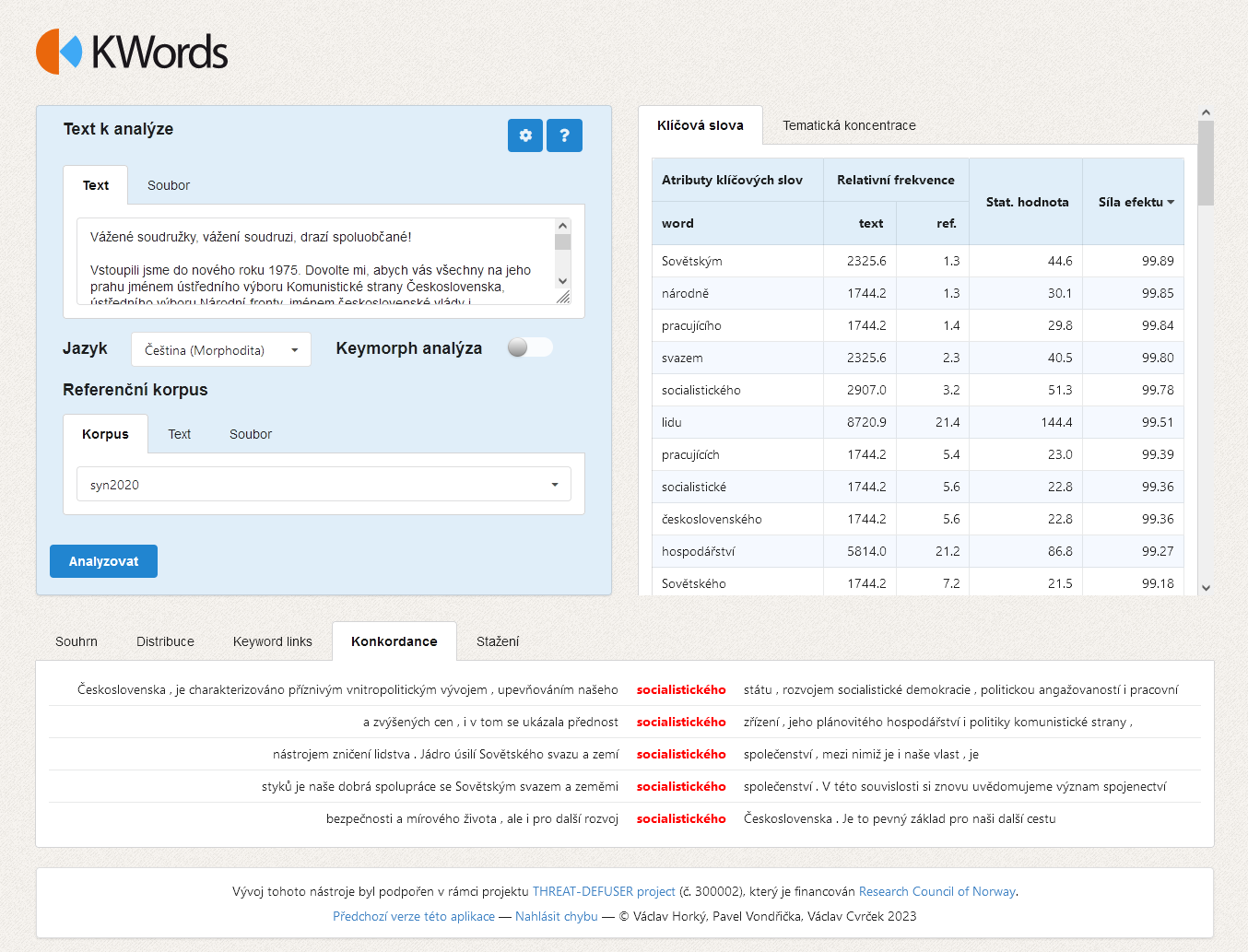
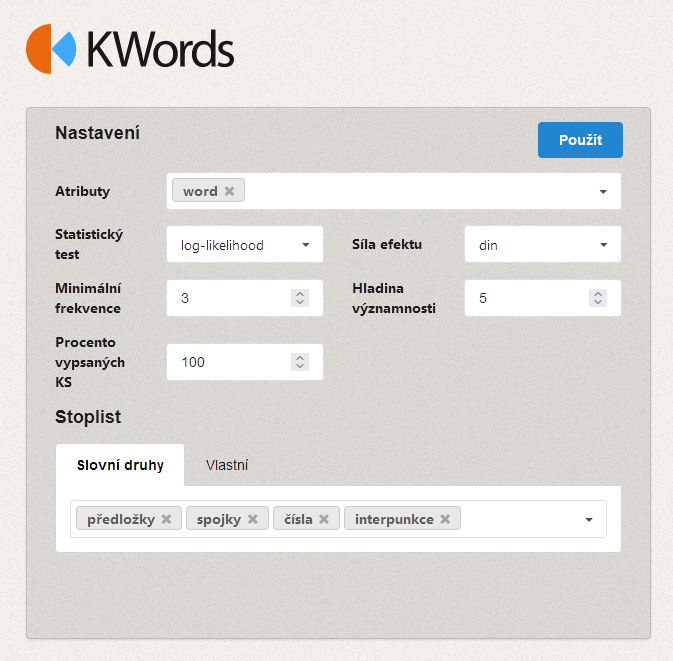
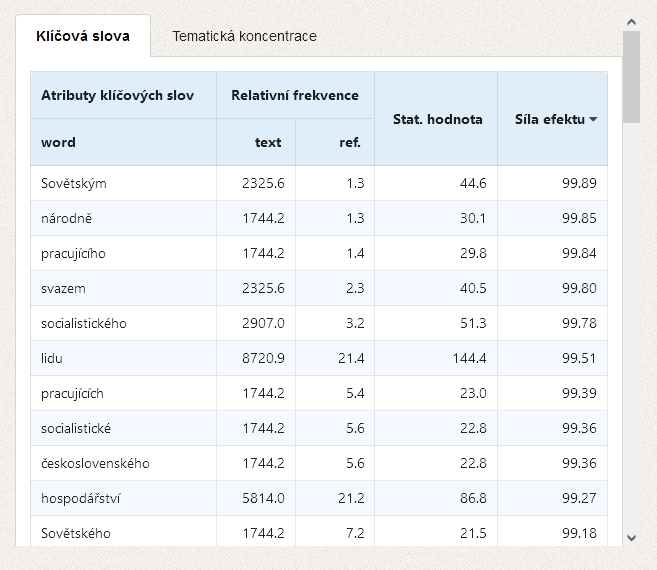
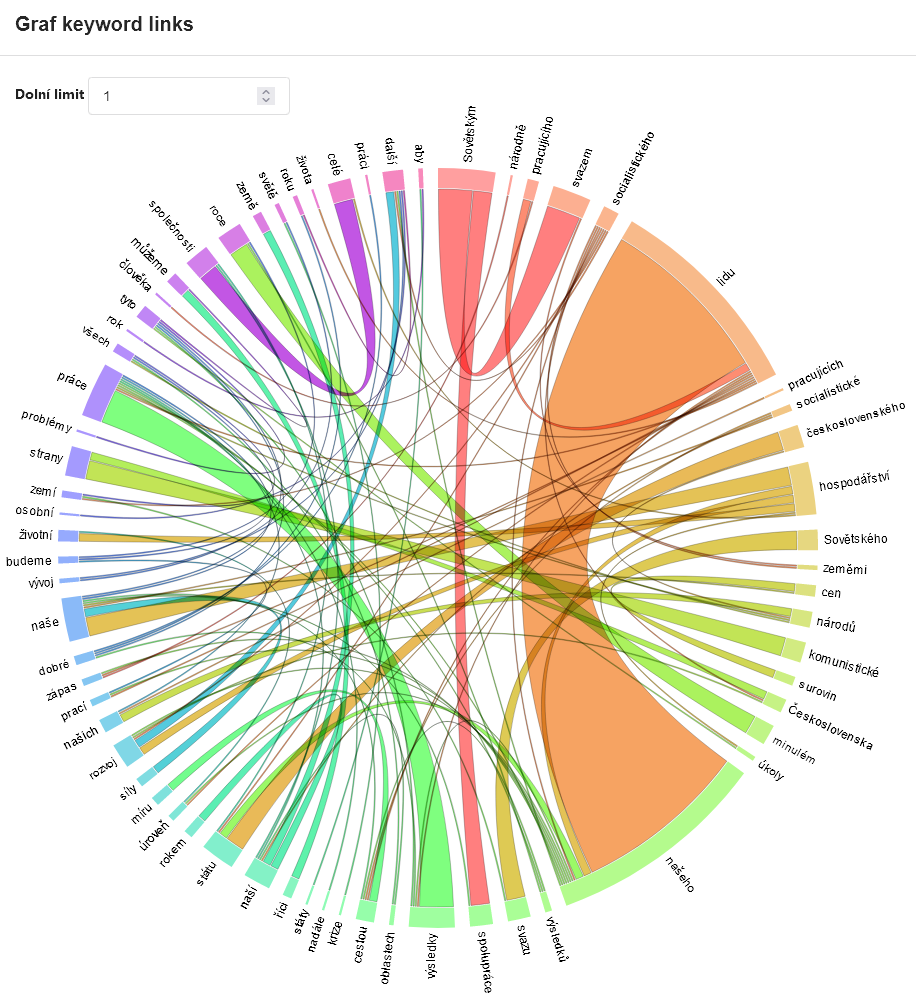
Obrázky aplikace (předchozí verze)

Jak citovat KWords
Cvrček, V. – Vondřička, P.: KWords. FF UK. Praha 2013. Dostupný z WWW: <http://kwords.korpus.cz>.




