

This is an old revision of the document!
Table of Contents
KWords
![]()
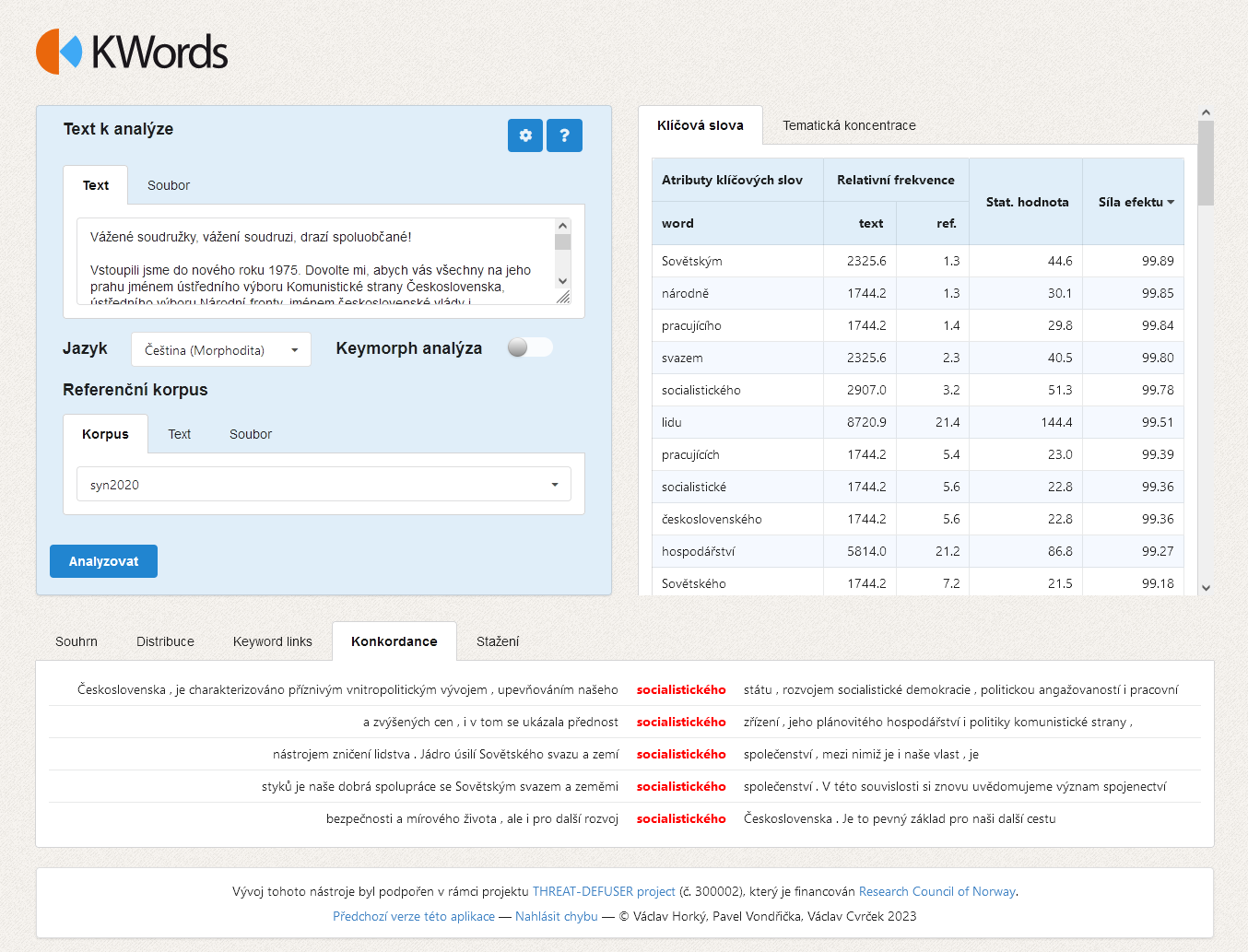
The KWords application is used for the analysis of texts based on their comparison with the general usage (reference corpus). Its aim is to identify so-called keywords, which are word forms appearing in the inspected text with a significantly higher frequency than in the reference corpus which should reflect the common usage. These key words serve as a basis for textual analysis and interpretation.
KWords is an online application (the only thing we need to use it is a web browser) and it is accessible without registration to all users at kwords.korpus.cz.
The first version of KWords was developed for the purpose of analyzing political speeches in collaboration with Brown University. The second version was developed as part of the Threat-defuser project. This version supports more than 30 languages and allows keyword analysis as well as keymorph analysis.1)
Prominent units
The KWords application identifies two types of prominent words:
- (Keywords)
- Words bearing the thematic concentration (TC) of the text
Keywords
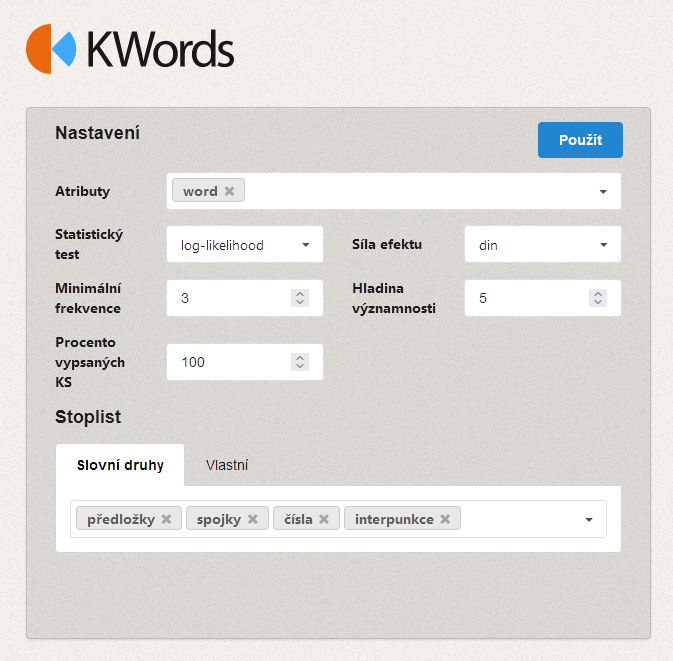
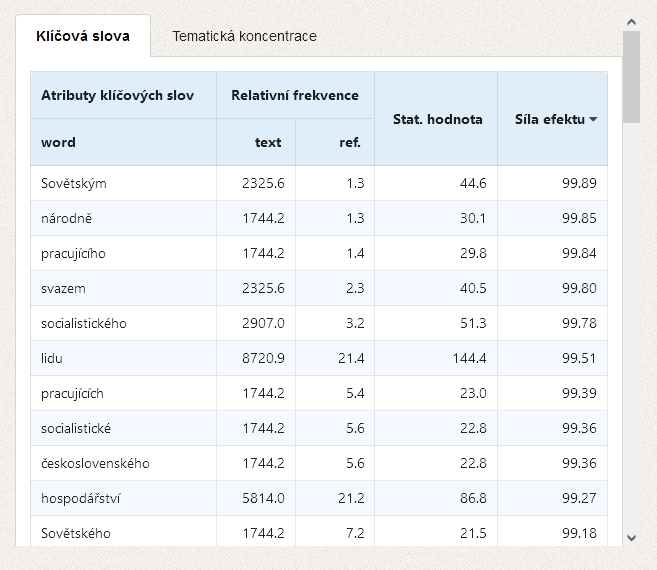
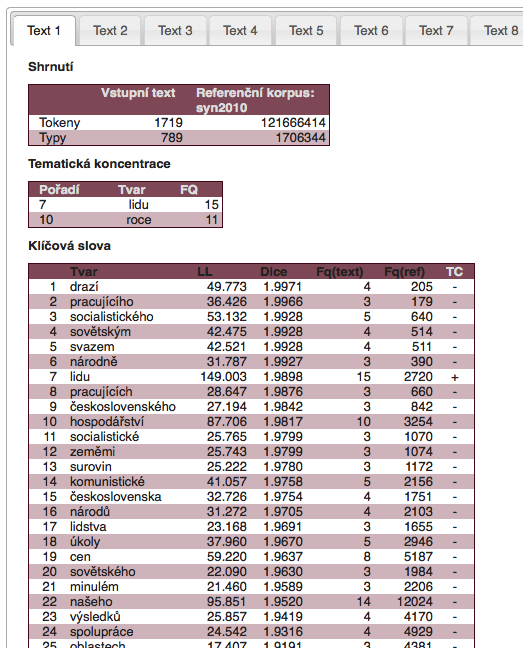
The identification of keywords takes place based on a comparison of each word's relative frequency in the given text with the same word's relative frequency in the reference corpus. Several tests are used to determine the statistical significance of the differences, two of which are implemented in KWords: chi2 and log-likelihood. Keywords in the analyzed text are marked red.
The results of the keyword analysis are always influenced by the choice of reference corpus, which should be seen as a neutral language background with which we compare the analyzed text. For example, when analyzing the New Year speeches of the last Communist president G. Husák, we notice that compared to current usage there is a high frequency of words such as socialistický (socialistic), soudružky (comrades) etc., but this i not the case when compared to a reference corpus from the same period. Currently, the following reference corpora can be used in the KWords application:
- for Czech
- diakon19 – ad hoc corpus created from available data in the diachronic part of the CNC covering the 19th Century
- totalita – a corpus of ideological texts and official journalism from the period of Communist totalitarianism
- for English
- BNC – British National Corpus
- InterCorp-EN v8 – the English section of the parallel corpus InterCorp
Thematic concentration
Words which are highlighted in yellow in the analyzed text are those which bear thematic concentration (TC words). They are not identified through comparison with a reference corpus, but only by their placement in the frequency distribution of the units in the analyzed text: when we arrange all the words in the text from those which are most frequent and down to words which appear only once, we get a so-called Zipf distribution. In this distribution we are looking for a so-called h point, for which we can say that rank = frequency (e.g. 32nd most frequent word has a frequency of 32 occurrences). All autosemantic words (bearing meaning independent of context) above this point (i.e. in our case with a frequency higher than 32) we label thematic concentration. More details and a specific application of this approach to literary texts can be found for example in the article of R. Čech (2013).
How it works
The text inserted by the user is first tokenized in a way that is identical to the tokenization of the corpus data. In the second step, the frequencies of all the words in the analyzed text are calculated (except for those which the user has excluded from the analysis with the help of a so-called stop-list, e.g. prepositions, conjunctions, numerals etc.). What follows is a comparison of the frequencies in the text and in the reference corpus. For units which display a statistically significant difference (according to the selected statistical test – chi2 or log-likelihood), the DIN value is subsequently calculated (difference index), which is indicative of how relevant the difference is:
$$DIN = 100 \times \frac{RelFq(Ttxt) - RelFq(RefC)}{RelFq(Ttxt) + RelFq(RefC)}$$
where $RelFq(Ttxt)$ is the relative frequency of the phenomenon in the analyzed text (target text) and $RelFq(RefC)$ is the relative frequency of the same phenomenon in the reference corpus. The DIN values, which determine the order of the keywords in the program's output, can reach values from -100 to 100, it being understood that:
- a value of -100 means that the given phenomenon does not occur in the analyzed text and is only in the reference corpus (therefore the word is not prominent in the analyzed text)
- a value of 0 means that the given phenomenon has approximately the same relative frequency in the analyzed text and in the reference corpus (therefore the word is not prominent in the analyzed text)
- a value of 100 means that the word occurs only in the analyzed text (it can therefore be a very prominent word 2))
In texts of up to 20 thousand words in length and for analysis of word forms, DIN values in the 75-100 range can be considered to be of interest and they indicate that the unit is probably prominent and can be used as a basis for the interpretation of the entire text.
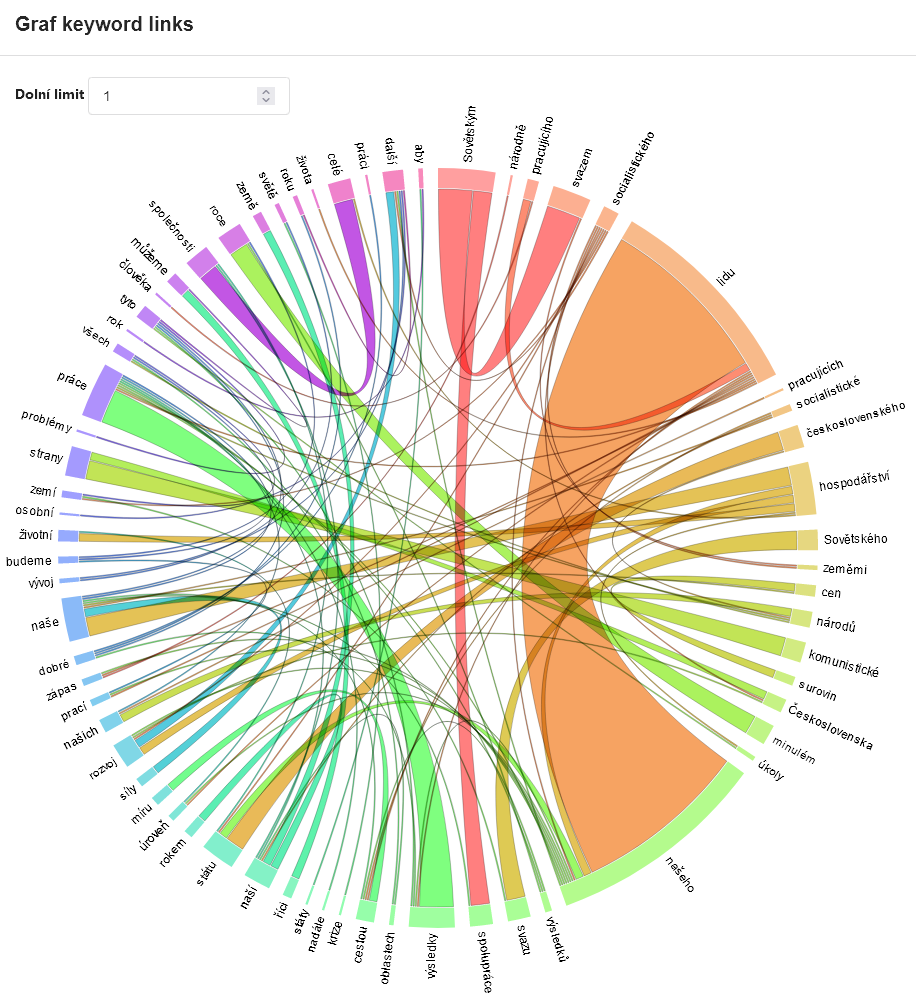
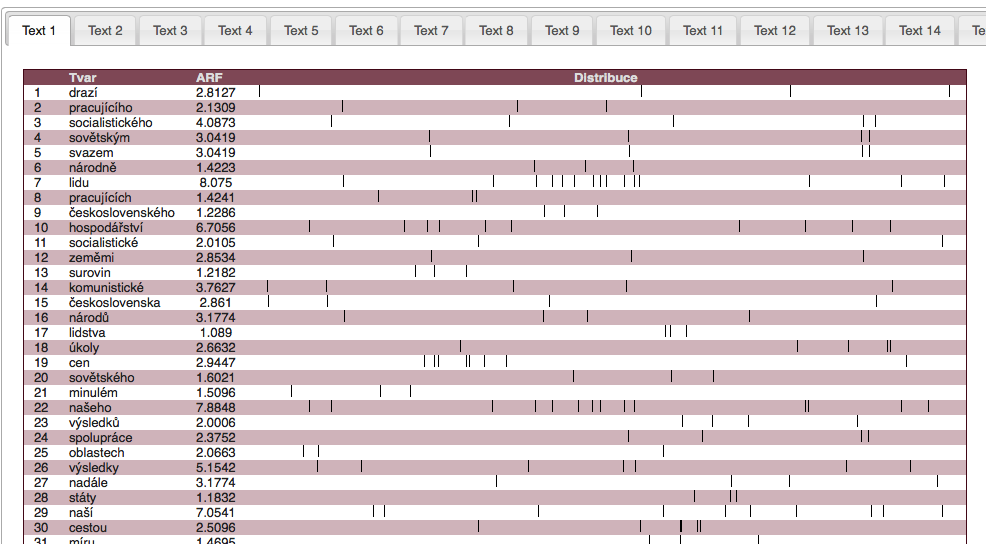
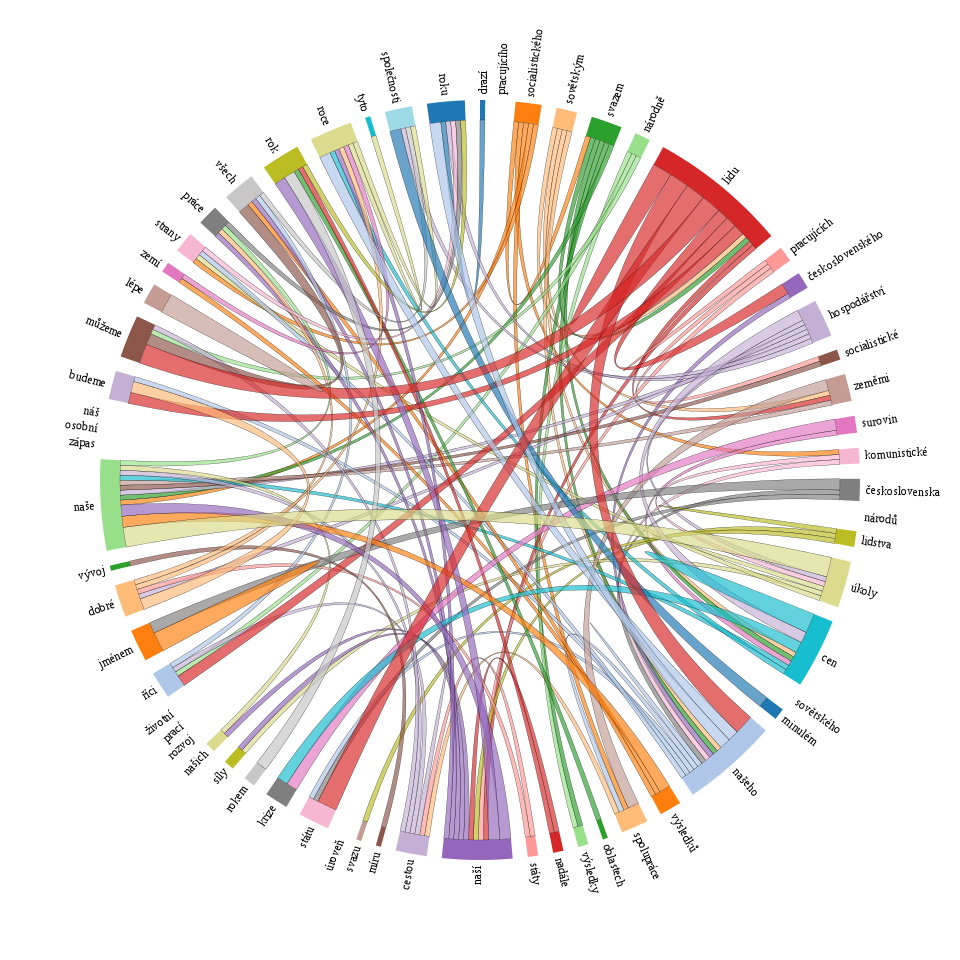
Furthermore, the KWords application offers a whole range of additional information for work with keywords. Apart from the list of keywords and their values it is the data dispersion graph (showing the status of the individual keywords in the text), a graph of so-called keyword links, i.e. relations between keywords in the text and also a concordance of keywords for an analysis of their immediate context.
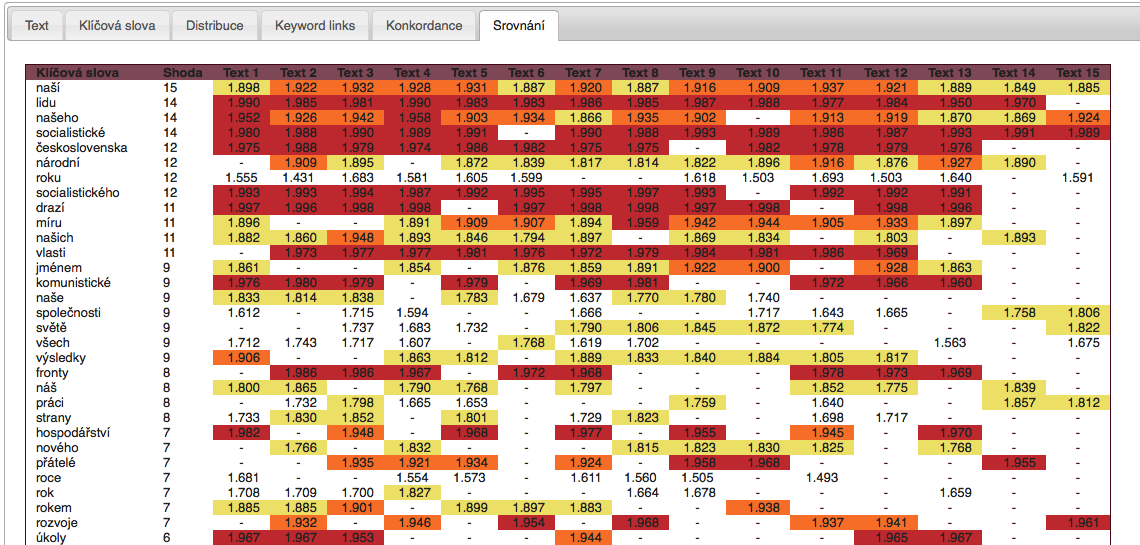
The KWords application was also designed for creating analyses of temporal (or other) data series. If the user inputs more texts into the application (the maximum amount is 20), the so-called multi-analysis regime is activated. This regime analyzes all the inserted texts and the results of the individual analyses are compared based on the DIN.
Application images
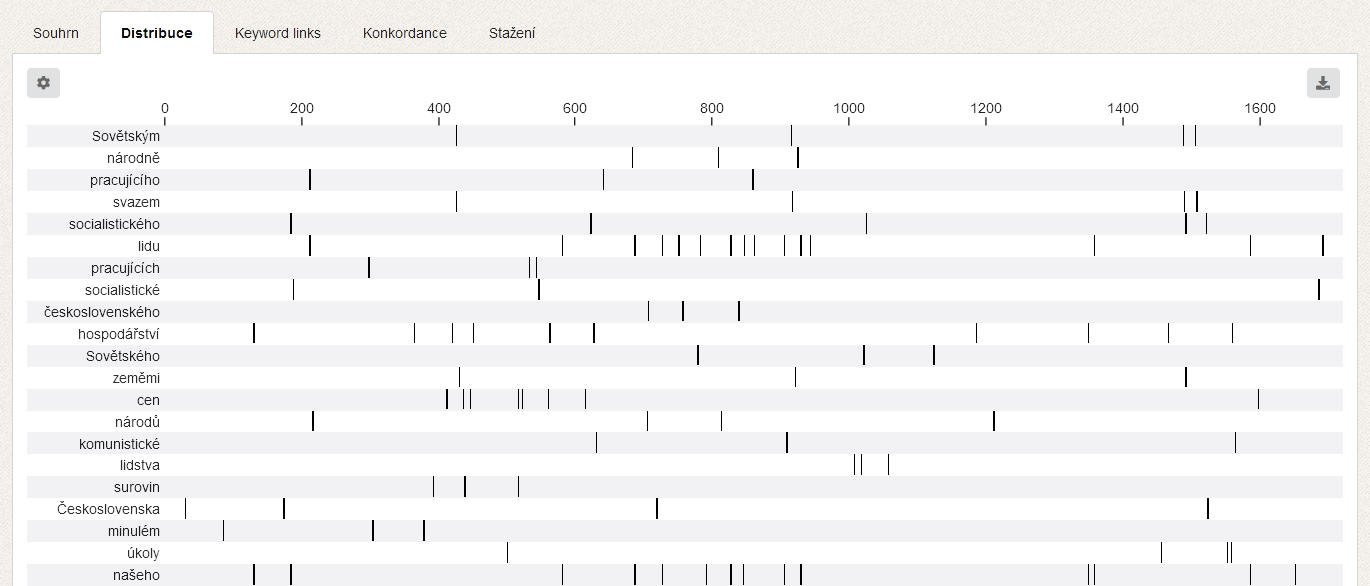
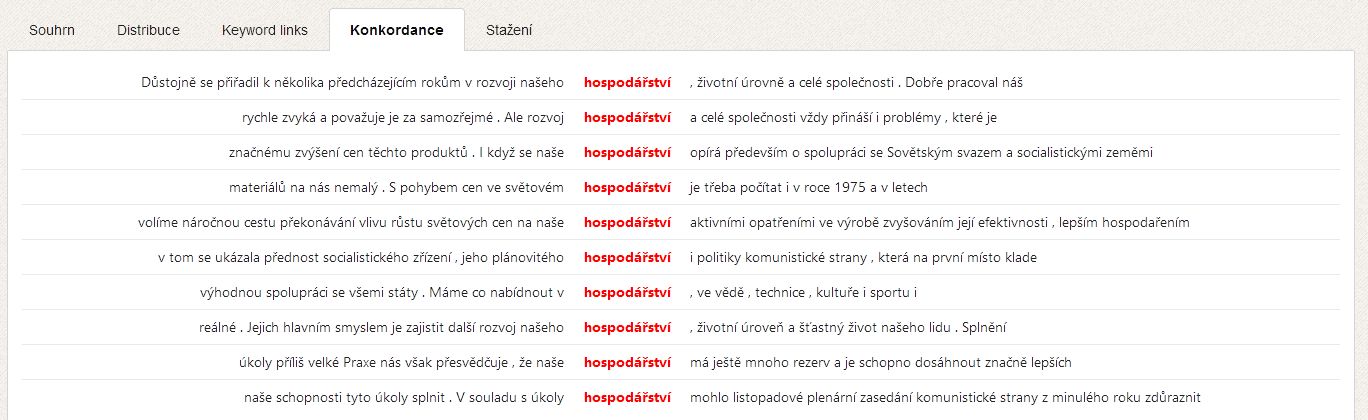
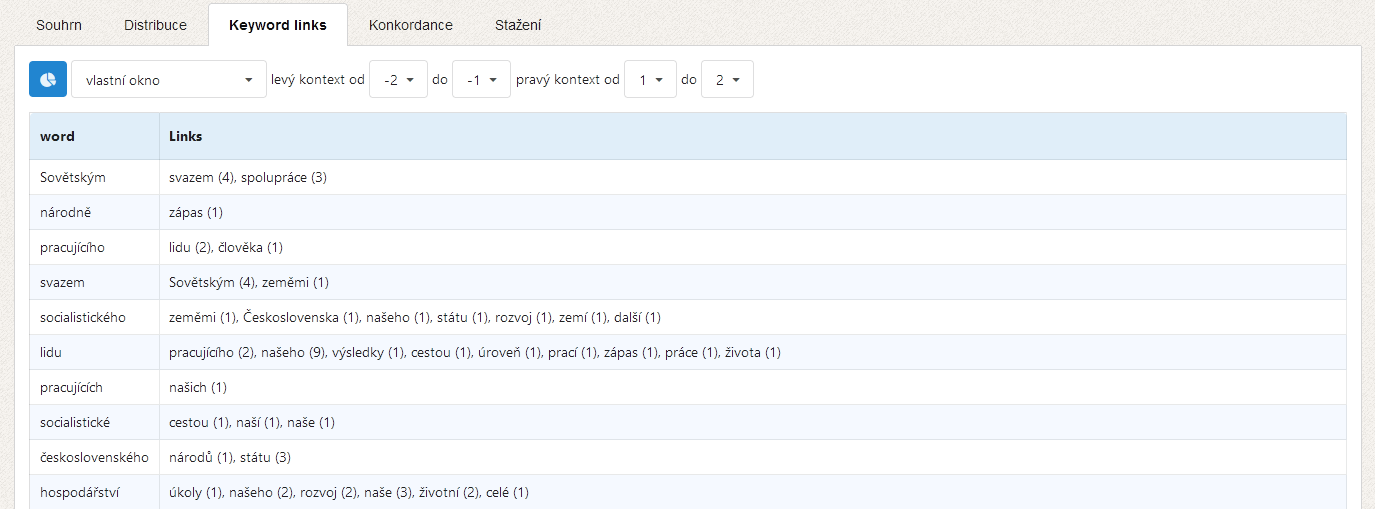
Application images (previous version)

Related links
KonText interface • SyD • Morfio • Treq • Corpus manager • Corpus tools




