

KorpusDB: Database of word forms and lemmas attested in the CNC corpora
![]()
The database contains all recognized word forms of all lemmata that actually occur in any of the processed CNC corpora: SYN v8 (contemporary written Czech), ORAL v1 and ORTOFON v1 (contemporary spoken Czech), DIAKORP v6 and an unpublished corpus of 19th century texts. Since their lemmatization and POS-tagging may differ, internal versions of these corpora have been processed, using a common tagging.
The web interface is available for querying at: https://db.korpus.cz/
The interface shows complete paradigms together with frequency breakdown of word forms in various types of text and offers filtering of categories with different degree of variability. For instance, you can try to search for the lemma motýl (butterfly) at https://db.korpus.cz/search/lemmas , then turn on the “stack variants” switch and set the “filter level” to four. Five morphological categories will appear with the greatest attested variability. There are several sources of this variability: contemporary written texts (dat.sg., loc.sg.), 19th century texts (nom.pl., acc.pl.) and contemporary spoken Czech (inst.pl.):
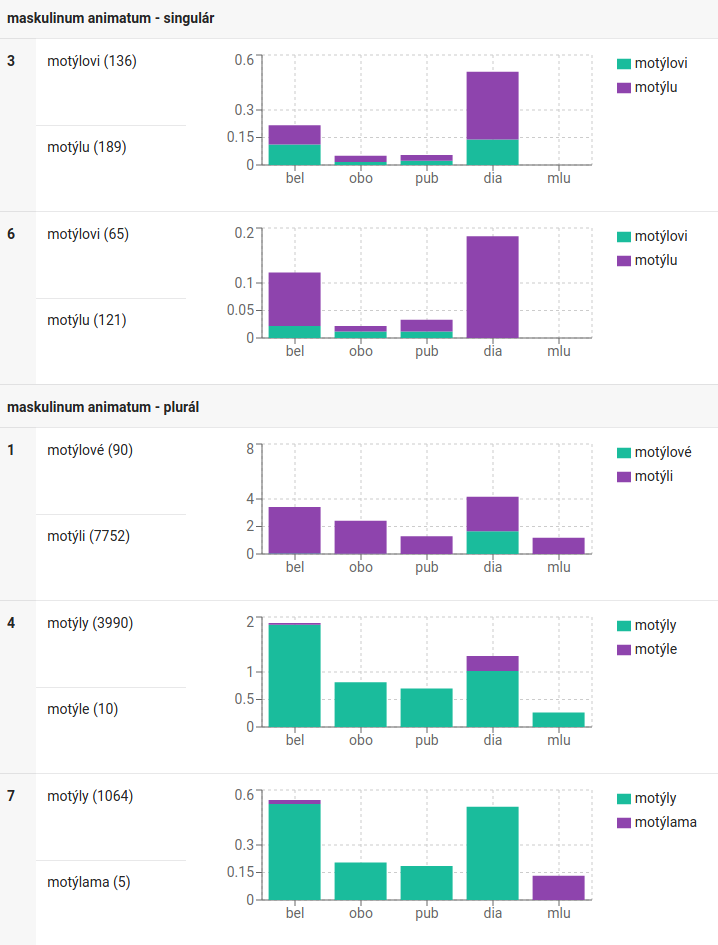
A more detailed help page on how to work with KorpusDB is available directly in the application after clicking on the question mark icon.
How to cite KorpusDB
Vondřička, P. (2020): KorpusDB: Database of word forms and lemmas attested in the CNC corpora. Version 1.0. FF UK, Praha. Available at: <http://db.korpus.cz/>.




