

KorpusDB: databáze slovních tvarů a lemmat doložených v korpusech ČNK
![]()
Databáze obsahuje všechny rozpoznané slovní tvary lemmat, která se reálně vyskytují v některém ze zpracovaných korpusů ČNK: SYN v8 (současná psaná čeština), ORAL v1 a ORTOFON v1 (současná mluvená čeština), DIAKORP v6 a nezveřejněný korpus textů 19. stol. Protože se lemmatizace a morfologické značkování těchto korpusů mírně liší, byly jako zdroj dat použity jejich interní verze s jednotným zpracováním.
Webové rozhraní nad databází je dostupné bez registrace na adrese: https://db.korpus.cz/
Webové rozhraní ukazuje mj. celá paradigmata spolu s frekvencemi tvarů v různých typech textu a s možností filtrování kategorií podle míry variability tvarů v nich. Zkuste si například na https://db.korpus.cz/search/lemmas najít lemma motýl, zapnout přepínač „seskupit varianty“ a změnit „úroveň filtru“ na 4. Objeví se celkem 5 morfologických kategorií, v nichž je doložena největší variabilita, jejímž zdrojem jsou v některých kategoriích současné psané texty (dat.sg., loc.sg.), v některých čeština 19. století (nom.pl., acc.pl.) a jindy primárně čeština mluvená (inst.pl.):
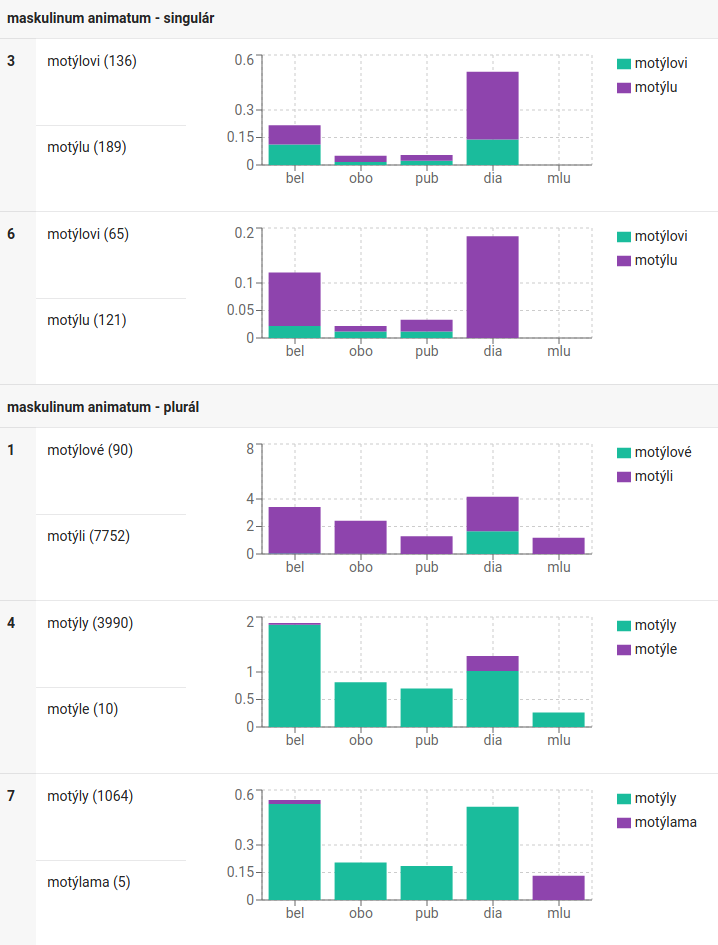
Podrobnější návod pro práci s KorpusDB najdete přímo v aplikaci po kliknutí na ikonu s otazníkem.
Jak citovat aplikaci KorpusDB
Vondřička, P. (2020): KorpusDB: Databáze slovních tvarů a lemmat doložených v korpusech ČNK. Verze 1.0. ÚČNK FF UK, Praha. Dostupný z WWW: <http://db.korpus.cz/>.




