

This is an old revision of the document!
The Koditex Corpus
Koditex is a 9-million-word corpus (excl. punctuation) compiled for the purpose of conducting a multidimensional analysis (MDA) of Czech. Its primary goal is to be as diverse and as representative of the wide range of uses of language as possible. At the topmost level, texts are classified into three modes of communication:
| Name | Koditex | |
|---|---|---|
| Positions | Number of positions (tokens) | 10,880,550 |
| Number of positions (excl. punctuation) | 9,139,930 | |
| Number of word forms | 509,764 | |
| Number of lemmas | 205,592 | |
| Structures | Number of samples <chunk> | 3,428 |
| Number of sentences <s> | 719,739 | |
| Further information | Reference corpus | YES |
| Representative corpus | YES | |
| Publication year | 2018 | |
- written language (wri),
- spoken language (spo) and
- web-based communication (web).
The name Koditex is both an acronym of the Czech version of the phrase corpus of diversified texts and a tribute to Vilém Kodýtek, author of a pioneering attempt to apply MDA to Czech.
Corpus design
Unlike other CNC corpora (e.g. SYN2015), the corpus consists of text samples (called chunks). Before sampling the assembled data for material to include in the final corpus, we decided to split texts longer than 5,000 words into contiguous chunks of 2,000–5,000 words (while respecting sentence boundaries). This decision was driven by several perceived advantages, primarily that of ensuring a higher overall diversity of the corpus in terms of registers as well as genres / text types.
Chunks are divided into modes (see above). Each mode is further subdivided into two or more divisions (e.g. the written mode subdivides into fiction, non-fiction, journalism and private correspondence), divisions then branch into classes of texts, aiming at roughly 200,000 words per class (subject to data availability). For the written mode, we introduced an intermediate superclass level which groups several related text classes together.
Some texts had to be removed from the data set prior to performing the MDA due to technical reasons. These texts are identified in the corpus by the attribute include=“no” in their metadata. The table below summarizes only texts which were actually included in the MDA:
| MODE | DIVISION | SUPERCLASS | CLASS | Tokens | Text chunks |
|---|---|---|---|---|---|
| spo (spoken) | int (interactive) | bru (unprepared broadcast discussions) | 221,812 | 90 | |
| eli (elicited speech/dialogue) | 201,690 | 82 | |||
| inf (informal unprepared private dialogue) | 208,565 | 86 | |||
| nin (non-interactive) | wbs (written-to-be-spoken speeches) | 213,201 | 71 | ||
| web | mul (multi-directional) | dis (discussions)† | 197,948 | 87 | |
| fcb (Facebook posts)† | 199,418 | 91 | |||
| for (forums)† | 200,104 | 85 | |||
| uni (uni-directional) | blo (blogs) | 204,356 | 74 | ||
| wik (cs.wikipedia.org articles) | 201,691 | 84 | |||
| wri (written) | fic (fiction) | nov (novels) | crm (crime) | 190,026 | 68 |
| fan (fantasy) | 189,432 | 69 | |||
| gen (general fiction) | 193,667 | 67 | |||
| lov (romance) | 189,893 | 70 | |||
| scf (sci-fi) | 188,703 | 68 | |||
| col (short stories) | 195,595 | 70 | |||
| scr (screenplays & drama) | 182,689 | 76 | |||
| ver (poetry & lyrics) | 205,837 | 76 | |||
| nfc (non-fiction) | pop (popular science) | fts (formal and technical sciences) | 207,607 | 68 | |
| hum (humanities) | 204,837 | 74 | |||
| nat (natural sciences) | 204,751 | 71 | |||
| ssc (social sciences) | 203,698 | 68 | |||
| pro (trade journals) | fts (formal and technical sciences) | 210,010 | 71 | ||
| hum (humanities) | 207,916 | 69 | |||
| nat (natural sciences) | 209,580 | 70 | |||
| ssc (social sciences) | 209,385 | 72 | |||
| sci (scientific/academic) | fts (formal and technical sciences) | 202,932 | 67 | ||
| hum (humanities) | 204,300 | 71 | |||
| nat (natural sciences) | 206,716 | 72 | |||
| ssc (social sciences) | 205,358 | 67 | |||
| adm (administrative texts)* | 203,542 | 82 | |||
| enc (encyclopedias) | 203,957 | 73 | |||
| mem (memoirs) | 203,390 | 71 | |||
| nmg (newspapers & magazines) | lei (leisure) | hou (crafts & hobbies) | 207,499 | 68 | |
| int (interesting facts) | 209,232 | 69 | |||
| lif (lifestyle) | 203,124 | 72 | |||
| mix (supplements, Sunday magazines) | 205,310 | 75 | |||
| sct (tabloids) | 201,417 | 73 | |||
| spo (sport) | 199,238 | 70 | |||
| new (newspapers) | com (op-eds, columns) | 205,372 | 68 | ||
| cul (culture) | 205,690 | 68 | |||
| eco (economic news) | 211,481 | 70 | |||
| fre (free time activities) | 208,532 | 71 | |||
| pol (politics) | 206,893 | 70 | |||
| rep (news) | 206,377 | 70 | |||
| pri (private) | cor (letters)* | 96,366 | 68 | ||
| Total | 9,039,137 | 3292 |
* In these classes, chunks as short as 1,000 tokens were allowed.
† Texts in these classes were first aggregated (by author and time of day) and then split into chunks of 2,000–5,000 words.
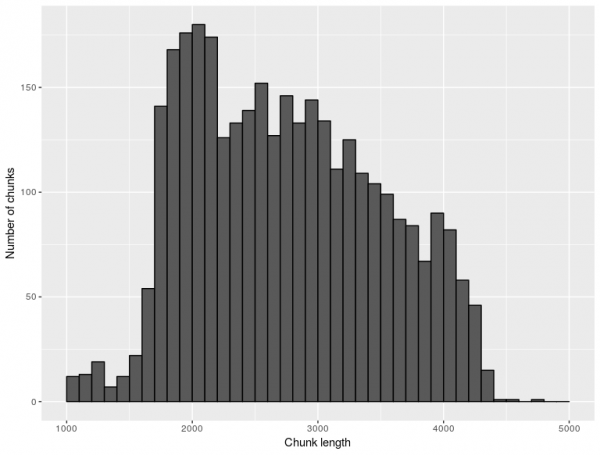
Chunks
The initial idea – to have all chunks approximately of the same length (between 2,000–5,000 words) – turned out to be unrealistic for some classes, because the typical text length in these classes is shorter. This led to two types of solutions. For some classes (e.g. pri or adm), a decision was made to push the lower bound down to 1,000 words, which also hopefully mitigated the bias in favor of texts longer than customary in the given category.
In other classes (e.g. fcb), the original data consisted of a sea of fragments mostly much shorter than even 1,000 words. In these cases, an aggregation of texts was performed and chunking applied only afterwards.
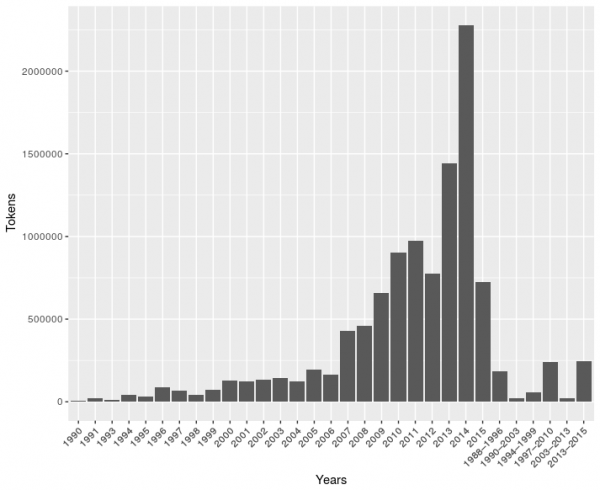
The focus of Koditex is on contemporary language, the oldest pieces were published in 1990.
The majority of texts (accounting for 76% of tokens) included in the corpus are Czech originals (not translations from other languages). The only exceptions are text classes where translated material is common in Czech in general, listed in the table below (the rest of the classes are 100% Czech originals).
| Class | Translations (words) | Originals (words) | % Translations |
|---|---|---|---|
| LOV | 210,250 | 30,981 | 87.2% |
| CRM | 202,921 | 37,677 | 84.3% |
| GEN | 196,924 | 43,497 | 81.9% |
| FAN | 188,848 | 52,778 | 78.2% |
| SCF | 174,340 | 66,221 | 72.5% |
| MEM | 176,000 | 67,731 | 72.2% |
| HUM | 329,928 | 395,573 | 45.5% |
| NAT | 324,310 | 401,957 | 44.7% |
| ENC | 103,954 | 137,889 | 43.0% |
| SSC | 265,640 | 460,324 | 36.6% |
| FTS | 259,325 | 467,253 | 35.7% |
| VER | 82,101 | 158,634 | 34.1% |
| WIK | 49,150 | 192,765 | 20.3% |
Annotation
Several layers of annotation were added to the corpus in order to facilitate operationalization of features:
- lemmatization and morphological tagging; two systems were used: the MorphoDiTa stochastic tagger1) and a hybrid tagger combining stochastic and rule-based disambiguation2)
- phraseme annotation by the FRANTA system3)
- named-entity recognition using the NameTag tool4)
Sources of data
The vast majority of the material in the Koditex corpus draws on the resources of the Czech National Corpus (CNC); types of language data which are not collected by the CNC were acquired from other research centers. We would also like to thank Karel Pala and Vít Baisa from the NLPC at Masaryk University, and Josef Šlerka and his team at Socialinsider, for providing raw data for the wik class and mul division, respectively.
- Benešová, Lucie, Michal Křen & Martina Waclawičová. 2013. ORAL2013.
- Benko, Vladimír. 2015. Araneum Bohemicum Maius, version 15.04. Faculty of Arts, Institute of the Czech National Corpus, Charles University in Prague.
- Cvrček, Václav, Petr Truneček & Václav Horký. 2015. SPEECHES.
- Čermák, František, Ana Adamovičová & Jiří Pešička. 2001. PMK.
- Hladká, Zdeňka. 2002. BMK.
- Hladká, Zdeňka. 2006. KSK.
- Křen, Michal et al. 2015. SYN2015.
- The DIALOG Corpus, version 1.2. 2015. Czech Language Institute of the Czech Academy of Sciences, Prague. http://ujc.dialogy.cz
- The EUROPARL Corpus (the Proceedings of the European Parliament). http://www.europarl.eu.int/
How to cite Koditex
Zasina, Adrian J., David Lukeš, Zuzana Komrsková, Petra Poukarová & Anna Řehořková. 2018. Koditex (A corpus of diversified texts). Faculty of Arts, Institute of the Czech National Corpus, Charles University in Prague.




