

This is an old revision of the document!
How to cite corpora accessed through the CNC
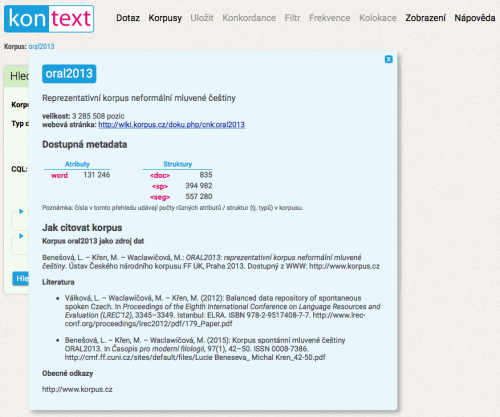
Ways of citing the corpora
There are essentially two ways in which corpora can be cited in an academic text:
- listing the corpus as a source (or source of data);
- listing a reference to the specific article which describes the creation and the structure of the corpus.
Volba mezi těmito dvěma možnostmi je na zvážení uživatele a záleží také na konkrétním účelu citace; samozřejmě je možné oba způsoby kombinovat. Konkrétní podobu citace najdete jednak v této wiki na stránce věnované konkrétnímu korpusu a jednak v rozhraní KonText po kliknutí na odkaz s názvem korpusu.
Citace ad 1) je uvedena vždy, citace ad 2) pouze v KonTextu a jen pro většinu korpusů; chybí tedy v případě, kdy se žádný článek s popisem korpusu nepodařilo dohledat. Kromě konkrétního bibliografického údaje však můžete u některých korpusů v KonTextu najít přímo webový odkaz na adresu, z níž je možné článek stáhnout.
Citování nereferenčních korpusů
Při citování nereferenčních korpusů, které nejsou neměnným referenčním zdrojem, je potřeba uvádět také číslo verze a čas přístupu podobně jako v případě citování webových stránek. Aktuální verze je u každého nereferenčního korpusu vždy k dispozici v rozhraní KonText jako součást citační informace.
Při citaci konkrétního díla lze použít také seznam zdrojů korpusu SYN2000, SYN2005 nebo SYN2010.
Lemmatizace a tagování
Používáte-li lemmatizaci nebo morfologické značky (atributy lemma nebo tag v korpusech řady SYN), citujte také následující publikace:
Jan Hajič: Disambiguation of Rich Inflection (Computational Morphology of Czech). Vol. 1. Karolinum Charles University Press, Praha 2004.
Tomáš Jelínek (2008): Nové značkování v Českém národním korpusu. In: Naše řeč, 91, 1, pp. 13–20.
Drahomíra Spoustová, Jan Hajič, Jan Votrubec, Pavel Krbec, Pavel Květoň: The Best of Two Worlds: Cooperation of Statistical and Rule-Based Taggers for Czech. In: Proceedings of the Workshop on Balto-Slavonic Natural Language Processing. ACL 2007, Praha. pp. 67–74.
Vladimír Petkevič (2006): Reliable Morphological Disambiguation of Czech: Rule-Based Approach is Necessary. In: Insight into the Slovak and Czech Corpus Linguistics (Šimková M. ed.). Veda, Bratislava, pp. 26–44.
Citování speciálních aplikací
Program SyD
Cvrček, V. – Vondřička, P.: SyD - Korpusový průzkum variant. FF UK. Praha 2011. Dostupný z WWW: <http://syd.korpus.cz>.
Cvrček, V. – Vondřička, P.: Výzkum variability v korpusech češtiny. In: F. Čermák (ed).: Korpusová lingvistika Praha 2011. 2. Výzkum a výstavba korpusů. NLN. Praha, s. 184–195.
Program Morfio
Cvrček, V. – Vondřička, P.: Morfio. FF UK. Praha 2013. Dostupný z WWW: <http://morfio.korpus.cz>.
Cvrček, V. – Vondřička. P. (2013): Nástroj pro slovotvornou analýzu jazykového korpusu. In: Gramatika a korpus 2012. Gaudeamus. Hradec Králové.
Program KWords
Cvrček, V. – Vondřička, P.: KWords. FF UK. Praha 2013. Dostupný z WWW: <http://kwords.korpus.cz>.




