

Toto je starší verze dokumentu!
Obsah
4. lekce: Regulární výrazy
V předchozích lekcích jsme se naučili pokládat dotaz, zobrazovat a ukládat výsledky a vyhodnocovat výsledky pomocí frekvenční distribuce. V této lekci se podíváme na pokročilejší způsoby dotazování.
Tzv. regulárními výrazy rozumíme sekvence znaků, pomocí kterých můžeme vyhledat množinu slov. Regulární výrazy využívají jednak znaky se speciálním významem (například znak * se používá jako zástupný symbol pro libovolný počet opakování, znak | je symbolem pro výběr z alternativ, podrobněji viz níže), jednak běžné znaky, tj. znaky abecedy, číslice apod., které mají doslovný význam. Všechny speciální znaky si postupně představíme a zároveň si vyzkoušíme, jak fungují v rozhraní KonText.
Tečka: libovolný znak
Začněme tím nejuniverzálnějším znakem, tedy tečkou (.), která zastupuje právě jeden libovolný znak. Jakékoliv třípísmenné slovo tak lze v KonTextu najít (mimo jiné) pomocí sekvence tří teček za sebou (...). Zadáme-li takový dotaz jako Slovní tvar, zobrazí se ve výsledku slova jako: ale, pro, tak, jak apod.
Hledáme-li tečku jakožto interpunkční znaménko, využijeme zpětné lomítko (více viz níže). Dotaz pak bude vypadat takto: \.
Kvantifikátory
Hojně využívané jsou tzv. kvantifikátory, které určují, kolikrát se smí bezprostředně předcházející znak (nebo speciální symbol) v daném řetězci opakovat.
| regulární výraz | znak | co zastupuje | další informace |
|---|---|---|---|
| hvězdička | * | libovolný počet (0 a více) opakování předchozího znaku nebo celku | ekvivalentní s {0,} |
| plus | + | 1 nebo více opakování předchozího znaku nebo celku | ekvivalentní s {1,} |
| otazník | ? | žádný nebo jeden výskyt předchozího znaku nebo celku | ekvivalentní s {0,1} nebo {,1} |
| interval ve složených závorkách | {n, k} | n až k opakování předchozího znaku nebo většího celku | je-li k vynecháno, tedy zůstane-li {n,}, odpovídá intervalu nejméně n opakování;je-li n vynecháno, tedy zůstane-li {,k}, doplní se na jeho místo nula;pokud má výraz tvar {n}, odpovídá mu přesně n opakování |
| kulaté závorky | () | vytvářejí celek, na který lze aplikovat další operace, např. opakování | celkem mohou být konkrétní znaky i vyšší jednotky |
Regulární výrazy mohou být složeny pouze ze speciálních znaků, z kombinací znaků speciálních a alfanumerických, nebo dokonce jen ze znaků alfanumerických. Z následující tabulky si můžete udělat představu, jakou množinu slov lze vyhledat prostřednictvím různých regulárních výrazů:
| Dotaz | Výsledek |
|---|---|
... | slova o třech písmenech |
a.. | slova o třech písmenech začínající na písmeno a |
a.* | slova o libovolné délce začínající na písmeno a, včetně samotného písmene a (např. a, až, ale, ahoj…) |
k.*o | slova o libovolné délce začínající na písmeno k a končící písmenem o (kdo, kolo, kafíčko) |
256 | číslo 256 |
19.. | letopočty začínající číslem 19 (případně též kombinace čísla 19 s různými znaky) |
kočka | slovo kočka |
kočk.* | všechny tvary lemmatu kočka s výjimkou Lsg. (kočce) a Gpl. (koček), ale i další odvozená slova: kočkodan, kočkovitý, kočkovat aj. |
Regulární výrazy budeme nejčastěji zadávat v rámci typu dotazu CQL, o němž bude řeč v příští lekci; lze je ale používat i v jiných typech dotazu – i ty jsou totiž následně automaticky přeloženy do dotazovacího jazyka CQL. Pokud tedy do typu dotazu Lemma zadáme regulární výraz .*číst, budou výsledkem všechny výskyty všech předponových sloves odvozených od slovesa číst.
Podívejme se nyní na konkrétní příklady regulárních výrazů zadaných do korpusu SYN2010 prostřednictvím typu dotazu Slovní tvar:
Zadejte následující dotazy:
ps?tps*tps+t
Následně aplikujte kvantifikátory na větší celek než pouhý jeden znak:
cha(cha)?cha(cha)*cha(cha)+
Zobrazte si u jednotlivých výsledků frekvenční distribuci slovních tvarů (word) a lemmat. Nerozlišujte velikost písmen a vytvořte si přehled toho, co dané dotazy našly a co nenašly.
Ověřme si nyní společně výsledky.
| dotaz | počet výskytů | odpovídající lemmata bez rozlišení velikosti (v závorce absolutní četnost) |
|---|---|---|
ps?t | 182 | pst (135), pt (47) |
ps*t | 302 | pst (135), psst (65), pssst (48), pt (47), psssst (6), psssssssst (1) |
ps+t | 255 | pst (135), psst (65), pssst (48), psssst (6), psssssssst (1) |
cha(cha)? | 331 | cha (300), chacha (31) |
cha(cha)* | 364 | cha (300), chacha (31), chachacha (31), chachachacha (2) |
cha(cha)+ | 64 | chacha (31), chachacha (31), chachachacha (2) |
Možná si kladete otázku, jestli se regulární výrazy hodí i pro výzkum zásadnějších jevů než citoslovcí. Je dobré zdůraznit, že se bez nich neobejdeme např. při prohledávání mluvených korpusů, které zatím nejsou lemmatizované, obrovskou pomocí jsou ale i při vyhledávání v korpusech lemmatizovaných.
Zkuste v korpusu ORAL2013 nalézt co nejvíc různých podob výrazu jestli.
- Zamyslete se nad tím, která písmena se při hovoru vynechávají, a lexém přesto zůstává srozumitelný.
- Zformulujte dotaz (drobná nápověda: vystačíte si pouze s písmeny a otazníky).
- Zobrazte si frekvenční distribuci.
Stejně jako u většiny úloh s regulárními výrazy i v tomto případě existuje více postupů, jak se dobrat ke stejnému výsledku. V každém případě nám může pomoct vyhledávač variant v korpusech řady ORAL. Pro řešení naší výzkumné otázky jsme zvolili symbol ?, který pomůže specifikovat, které segmenty se ve slově nemusejí vždy vyskytovat.
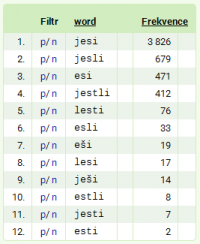

Ve frekvenčním seznamu se ocitly dva překvapivé tvary: jesti a esti. Pomocí modře označeného p (pozitivní filtr) ve frekvenčním seznamu můžeme hned zkontrolovat, zda jde o námi hledaný význam (v obou případech tomu tak je) a nakolik je použití tohoto konkrétního tvaru regionálně či jinak podmíněné (zdá se to být východomoravské specifikum – 6 případů ze 7, respektive 8 z 9 spadá do této nářeční oblasti).
Sekvence libovolných znaků
Nejmocnější kombinací je vyhledání libovolného počtu opakování libovolných znaků, tj. .* (tečka a hvězdička). Ta může reprezentovat celé slovo nebo jeho libovolnou část. Proto není vhodné zadávat samotný dotaz .*, není-li to nutné, protože výsledkem zdlouhavého a výpočetně náročného hledání budou všechna slova v daném korpusu.
- Vyhledejte v korpusu SYN2010 v typu dotazu Slovní tvar řetězec znaků
.*vědom.*. - Zobrazte si frekvenční distribuci takto identifikovaných lemmat a výsledný frekvenční seznam si uložte.
Jak kýžená frekvenční distribuce vypadá? Najde veškerá lemmata obsahující daný řetězec znaků (v tomto případě slovní základ vědom) a umožní zkoumat nejrůznější typy odvozování, zároveň s územ (reprezentovaným frekvencí).

Další speciální symboly
Vedle kvantifikátorů a tečky lze v rámci regulárních výrazů použít i další symboly se speciálním významem.
| regulární výraz | znaky | co zastupuje | další informace |
|---|---|---|---|
| seznam | [ ] | alternativa, možnost výběru jednoho libovolného znaku ze znaků uvnitř hranatých závorek | v rámci seznamu je možné používat také pomlčku (-) jako operátor rozsahu (např. [a-z], [1-9]) pro alfabetické znaky a číslice |
| inverzní seznam | [^ ] | výběr jednoho libovolného znaku s výjimkou znaků uvnitř hranatých závorek | pokud je prvním znakem seznamu stříška (^), jde o inverzní seznam: tedy jeden libovolný znak kromě těch uvedených uvnitř hranatých závorek |
| svislá čára | | | alternativa, ovšem ne jenom mezi jednotlivými znaky, ale mezi celými řetězci tvořícími celek | kombinuje se často s kulatými závorkami, které pomáhají určit prioritu vyhodnocení |
| zpětné lomítko | \ | pokud předchází speciálnímu znaku, ztrácí daný symbol svůj zvláštní význam | takto lze vyhledávat např. interpunkční znaménka či další speciální znaky v textu |
Pozor! Význam hranatých závorek je dvojí:
- v rámci regulárních výrazů představují seznam (viz tabulka výše)
- v rámci CQL představují samostatnou pozici, viz příští lekce.
Z těchto regulárních výrazů si zde procvičíme jen tři nejpoužívanější, k dalším se dostaneme v dalších lekcích kurzu.
Příklad dotazu: Adjektiva s prefixem vy-
V korpusu ORAL2013 ověřte, jak expanduje prefix vy-, a to především u adjektiv. Korpus není lemmatizovaný ani tagovaný, musíme si proto vystačit s hledáním pomocí Slovního tvaru.
- Nejprve si představte slova s touto předponou: vykalený, vymazlený, vytuněný, …
- Rozepište si, jaké mužské koncovky – pro jednoduchost jen tyto – mohou adjektiva (v obou číslech) mít, a vyberte ty, které nejsou ve velké míře homonymní (např. s tvary sloves).
- Vytvořte dotaz na slovní tvar, u něhož znáte začátek i konec výrazů a hledáte prostřední část.
Jaký dotaz jste zvolili a jaké výsledky jste v korpusu ORAL2013 obdrželi?
| dotaz | odpovídající slovní tvary (absolutní četnost v ORAL2013) |
|---|---|
vy.+(ý|ej|ma|mi) | vysoký (111), vysokej (67), vyřešený (20), vyřízený (17), vystavený (16), … |
Co se dotazu na adjektiva s vy- týče, ani omezení koncovek na ty výše zvolené nevyloučí z výsledku slovesné tvary typu vyndej, ruční třídění je po položení dotazu určitého typu nezbytné (jde o potíž s tzv. precision a recall – jak přesně zformulovaný dotaz položit, aby nevyloučil příliš mnoho dokladů, které nás mohou zajímat).
Příklad dotazu: Konkurence forem
Vyhledejte v korpusu SYN2015 v typu dotazu Lemma:
- prefigovaná adjektiva na vy- zakončená na -lý nebo -ný (např. vyčpělý a vydýchaný)
| dotaz | výsledek | příklady lemmat |
|---|---|---|
vy.+(lý|ný) | 105 368 výskytů | vybraný, vyrovnaný, …, vyspělý, vyčerpaný… |
S tímto dotazem úzce souvisí nástroj Morfio, který slouží pro slovotvornou analýzu.
Vyzkoušejte si na závěr
V korpusu SYN2015 najděte:
- pomocí dotazu typu Lemma všechna slova, která obsahují sekvenci kořen, kterou následuje i předchází alespoň jeden znak (typicky předpona a přípona)
- pomocí dotazu na Slovní tvar všechny prefigované infinitivy odvozené od slovesa téct/téci
- všechny výskyty tvarů negativního superlativu, tj. tvary začínající na nejne- a končící na ší nebo čí (pro jednoduchost odhlédněme od jiných tvarů než je nom. sg.)
Výsledky najdete jako vždy v Řešení úkolů.
Pokročilejší dotazy nelze vytvářet bez znalosti dotazovacího jazyka CQL, o němž si povíme v následující lekci.




