

Obsah
3. lekce: Položili jsme dotaz. Jak ho vyhodnotit?
V první lekci tohoto průvodce pro práci s korpusy jsme se naučili pokládat jednoduchý typ dotazu, v druhé lekci jsme si ukázali různé možnosti zobrazení výsledků, především doplňkových informací o zdrojovém textu. Nyní se zaměříme zejména na to, jak zobrazená data co nejefektivněji vyhodnotit pomocí funkcí Frekvence a Konkordance → Třídění.
Frekvence
Funkce frekvenční distribuce, zkráceně nazývaná Frekvence, poskytuje přehled o frekvenci jevů v rámci vyhledaného dotazu – především pomáhá spočítat, kolik je těch či oněch slovních tvarů, lemmat nebo tagů, případně kolik je výskytů vyhledaného lemmatu či slovního tvaru v různých typech textů. Na rozdíl od konkordance, která zobrazuje tokeny, frekvenční distribuce slouží k zjištění frekvencí typů.
Vedle rychlých voleb – slovní tvary (bez ohledu na velikost písmen), dokumenty, typy textů apod. – nabízí funkce Frekvence i široce nastavitelnou volbu Vlastní. Ta umožňuje vytvářet frekvenční seznamy pozičních atributů (tzv. Běžná frekvenční distribuce), seznamy strukturních atributů (Podle typů textu) a seznamy kombinující dva atributy (tomuto typu se zde věnovat nebudeme, je ale popsán v manuálu).
Frekvenční distribuce slovních tvarů
Zkusme si nejprve společně vyhledat frekvenci jednotlivých pádových forem lemmatu noha, a to v korpusu SYN2020. Celkem se tu nachází 32 535 výskytů tohoto lemmatu (za předpokladu, že jsme zvolili lemma za výchozí atribut). V menu vybereme volbu Frekvence → Slovní tvary, načež se nám ukážou všechny doložené pádové formy. Celkový počet různých tvarů (typů) je zobrazen za slovem Celkem v horní části výsledné tabulky, v tomto případě 12 tvarů.
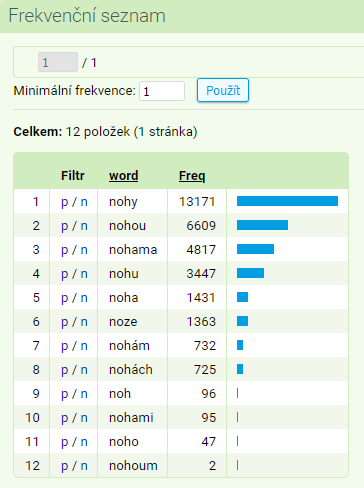
Z výsledné tabulky se dá leccos snadno vyčíst, např. kolikrát se slovo noha realizuje v „neživotném“ tvaru nohami. Zajímá-li vás, zda a jak se liší užití tvarů nohama a nohami, stačí prokliknout přes modře zvýrazněné p vlevo od vybraného tvaru (p značí pozitivní filtr dané konkordance, n je filtr negativní a zobrazil by všechny tvary kromě vybraného).
Pohled na 95 konkordančních řádků tvaru nohami, k nimž se takto dostanete, ukazuje, že většinou se skutečně jedná o nohy od nábytku (stůl, židle), nezanedbatelný počet výskytů sice odkazuje i k životným subjektům, ale v porovnání s četností (kodifikovaného) tvaru nohama (4817) je to minimum. A naopak, jistě bychom našli i nejeden tvar nohama v souvislosti s nábytkem.
Pozor, je třeba počítat s pádovou homonymií: např. nejfrekventovanější tvar nohy může být jak forma genitivu singuláru, tak nominativu či akuzativu plurálu (a jak se ukáže níže, i ještě jednoho okrajového pádu – tipnete si jakého?).
Jak tyto pádové formy odlišit? Samozřejmě lze vyfiltrovanou konkordanci podrobit manuální analýze, ale ruku na srdce, chtělo by se vám ručně procházet přes 13 tisíc řádků? U takto velkého objemu dat je však lepší spolehnout se na automatickou morfologickou analýzu (a skousnout určitou míru chybovosti, pohybující se aktuálně kolem 4 %). Stejně jako si můžeme nechat korpusovým manažerem sečíst totožné tvary, není problém aplikovat početní operace i na jiné atributy, např. tag, který nám konkrétní pádové formy – i ty homonymní – odliší.
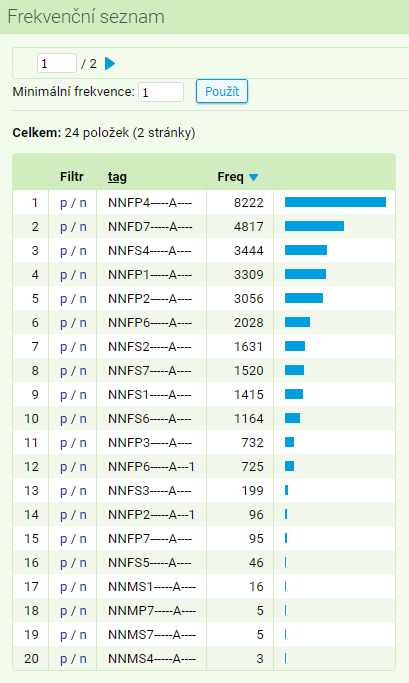
Výsledný soupis vypadá trochu divočeji než ten předchozí, ale s pomocí nápovědy se v něm po chvilce zorientujete. Relevantní je tu 4. a 5. pozice, označující číslo a pád; vidíme tedy, že akuzativ plurálu (P4) je nejčastější, na čtvrtém řádku je zaznamenán nominativ plurálu (P1) a konečně poslední homonymní tvar – genitiv singuláru (S2) – nacházíme na sedmém řádku.
Podobně bychom mohli z prvního frekvenčního seznamu výše pozitivně vyfiltrovat tvar nohy a na ten pak znovu aplikovat funkci Frekvenční distribuce, tentokrát přes atribut tag – dostali bychom takovýto výsledek:
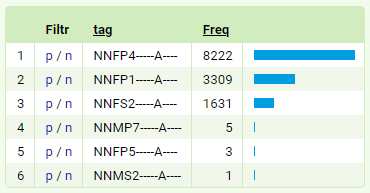
(Poslední tři položky mohou být právě případy chybné strojové anotace, ale nemusí tomu tak být, např. všechny tři tvary vokativu plurálu jsou označkovány správně.)
Frekvenční distribuce slovních druhů v okolí KWICu
Adjektiva proslulý a věhlasný jsou si významově blízká. V textu se však chovají odlišně, a to mj. tím, jak často jsou adverbiálně modifikovaná. Do jaké míry se v tomto ohledu liší a kterými adverbii jsou obě adjektiva rozvíjena, zjistíme pomocí frekvenční distribuce slovních druhů na pozici bezprostředně předcházející KWICu. Vyhledáme postupně obě zkoumaná lemmata v SYN2020. Na výsledek (523krát věhlasný, 2652krát pro proslulý) uplatníme frekvenční distribuci. V menu vybereme Frekvence → Vlastní Jako atribut zadáme pos (part-of-speech, slovní druh), pozici změníme na 1L (první pozice vlevo od KWIC, tedy ta, na které se předpokládá výskyt adverbií rozvíjejících adjektiva).
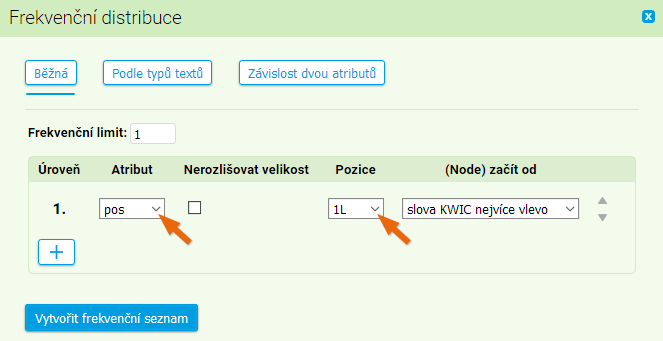
Ve výsledné tabulce zjistíme, že slovu proslulý předcházejí nejčastěji právě adverbia (označovaná zkratkou D), kdežto slovu věhlasný obvykle substantiva (N), a adverbia jsou dokonce až na sedmém místě tabulky. Kromě samotného pořadí je jistě zajímavé i zjištění, v kolika procentech případů jsou tato lemmata adverbiálně modifikována: adjektivu proslulý předchází adverbium ve 25 % případů v porovnání s 8 % případů u věhlasný.
Porovnávání absolutní frekvence může velmi často být zavádějící, spolehlivější a výhodnější je spočítat procentuální zastoupení jevů nebo relativní frekvence.
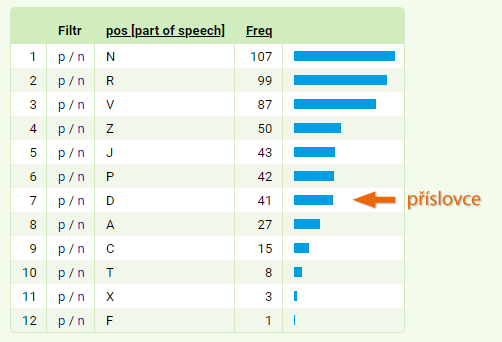
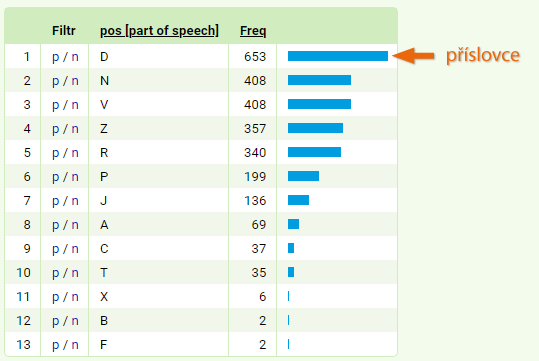
Ve výsledné tabulce můžeme kliknutím na modře zvýrazněné p (pozitivní filtr) zjistit, která konkrétní adverbia dané lemma rozvíjejí – zobrazí se totiž všechny konkordanční řádky, kde vybranému adjektivu bezprostředně předchází adverbium. Seznam adverbií spolu s jejich frekvencemi získáme opětovným použitím frekvenční distribuce: v menu vybereme Frekvence → Vlastní, jako atribut zadáme lemma, pozici upravíme na 1L. Zjistíme tak, že s adjektivem proslulý se nejčastěji pojí adverbia nechvalně, světově a neblaze, kdežto slovo věhlasný je rozvíjeno zcela odlišným typem adverbií, např. tak, také, málo nebo už.
Vliv typu textu na jazyk
Pomocí frekvenční distribuce můžeme zkoumat mimo jiné vliv toho, o jaký text se jedná. Vyhledejme výplňkové slovo vlastně tentokrát např. v korpusu SYN2015 (výchozí atribut: Lemma) a porovnáme jeho frekvenční distribuci v různých textových typech s výskyty v mluvené češtině.
Po zobrazení konkordance z menu vybereme Frekvence → Typy textů, a protože jednotlivé textové typy a žánry nejsou zastoupeny stejným objemem textů, kliknutím na i.p.m. seřadíme výsledky podle relativní frekvence.
Nejvyšší relativní frekvenci (479 i.p.m.) najdeme u dramat, nejnižší (12 i.p.m.) u administrativních textů. Divadelní hry (txtype SCR: drama) jako druh psaného textu, který má nejblíže mluvenému jazyku, přímo vybízejí ke srovnání s korpusy řady ORAL, které obsahují neformální a nepřipravený mluvený jazyk. Zadáme tedy stejný dotaz, tentokrát do korpusu ORAL v1.
Výsledky shrnuje následující tabulka:
| Textový typ | relativní frekvence (i.p.m.) |
|---|---|
| SCR: drama | 479 |
| NOV: próza | 367 |
| SCI: odborná literatura | 163 |
| VER: poezie | 139 |
| ADM: administrativa | 12 |
| ORAL v1 (vlastně + vlasně1)) | 1363 |
Nízká frekvence vlastně v administrativě a odborné literatuře je pochopitelná, tyto texty se snaží být stručné a přitom exaktní. Mluvený jazyk, který divadelní hry (ale oproti poezii třeba i próza, především v přímé řeči) napodobují, naopak jistou redundanci (kterou vlastně signalizuje) přímo vyžaduje.
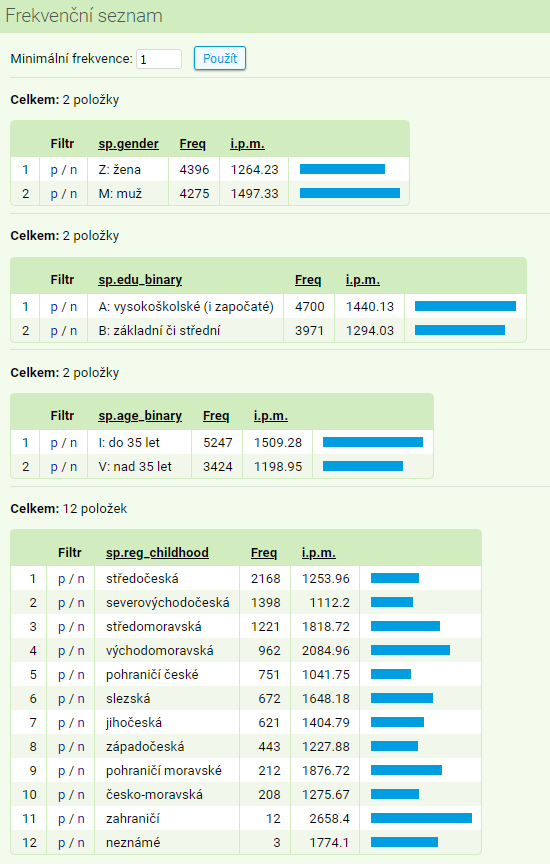
Frekvenční distribuce charakteristik mluvčích
Jednotlivé charakteristiky mluvčích v mluvených korpusech (např. věk, pohlaví, vzdělání, oblast) si navolíte prostřednictvím volby Frekvence → Vlastní → Podle typů textu. Podobný výstup poskytuje i rychlá volba Frekvence → Typy textů, kterou aplikujete na konkordanci v mluveném korpusu řady Oral.
Třídění řádků
Kvalitativní analýza konkordančních řádků může těžit z funkce Třídění, která je k dispozici v menu pod položkou Konkordance. Tuto funkci lze využít, dáváme-li přednost ruční kvalitativní analýze před analýzou frekvenční (viz první část této lekce věnovaná frekvenční distribuci).
Třídit řádky má smysl jen v případě, že celá konkordance není příliš rozsáhlá – je tedy rozumné pracovat s náhodnými vzorky, tj. s určitým zpracovatelným počtem náhodně vybraných řádků. Náhodný vzorek vytvoříme po zadání dotazu v menu Konkordance → Vzorek, kde si zadáme požadovaný rozsah vzorku. Doporučujeme vybírat spíše menší vzorky (defaultně nastavených je 250), které jsou ještě přehledné. Problematice vytváření náhodných vzorků se detailně věnuje samostatný článek.
Jakmile máme připravený náhodný vzorek, můžeme v něm řádky abecedně seřadit, a to buď podle prvního znaku KWICu, nebo podle levého či pravého kontextu. Chceme například pomocí kvalitativní analýzy zjistit, s jakými slovy se obvykle pojí adjektivum červený. V menu vybereme položku Konkordance → Třídění. Pokud nás zajímá pravý kontext, kde se budou pravděpodobně vyskytovat mj. substantiva rozvíjená slovem červený, zvolíme atribut word nebo lemma, klíč třídění Pravý kontext a počet tokenů k třídění 1 (to znamená, že abecedně řadit se bude jen jediné slovo vpravo od KWICu).
Kvalitativní analýzou zjistíme, že po adjektivu červený skutečně v textu nejčastěji následují substantiva, např. víno, kříž, barva, řepa či karta. Podobnou kvalitativní analýzou levého kontextu (klíč třídění změníme na Levý kontext) dospějeme k tomu, že adjektivum červený může být rozvíjeno adverbii jako jasně či temně, adjektivy velký či malý nebo slovesy být, mít aj.
Uložení výsledků analýzy
Kromě uložení výsledku dotazu (tedy samotných konkordančních řádků) můžeme ukládat i výsledky analýz, především frekvenční a kolokační seznamy. Ve výsledné tabulce (pokud data otevíráme v tabulkovém editoru) můžeme dále třídit, promazávat či jinak upravovat řádky podle svých představ a výzkumných záměrů.
V korpusu SYN2020 najděte nejčastější pravostranná doplnění k výše zmíněnému adjektivu červený. V nabídce Frekvence → Vlastní zvolte atribut: lemma, zaškrtnout Nerozlišovat velikost, pozice: 1R. V horní části výsledné tabulky vidíme, že takových lemmat je téměř 2700. Řekněme, že nás ale zajímají jen takové kolokáty, která se v daném korpusu vyskytují alespoň padesátkrát. Při ukládání zvolte položku Uložit → Vlastní, jež umožní omezit počet exportovaných řádků (shodou okolností jich bude přesně padesát, tj. zadáme od 1 do 50, na řádku 51 je slovo, které je v daném korpusu pouze 47krát, což snadno zjistíte přesunem na následující stránku soupisu). Zvolte formát XLSX a data uložte. V okně, které se automaticky zobrazí, stačí už jen zvolit, zda chcete soubor otevřít ve formátu Excel (pozor, v tom případě není zatím uložený!), nebo ho rovnou uložit mezi své soubory.
Vyzkoušejte si na závěr
- Vytvořte frekvenční distribuci všech předložek bezprostředně předcházejících lemmatu vědomí v korpusu SYN2020.
- Jak se liší výskyt slova vole v mluvě mužů a žen? Opřete se o frekvenční distribuce v korpusech řady ORAL.
Výsledky najdete jako vždy v Řešení úkolů.
A nyní už odvážně do následující lekce, v níž se seznámíme s regulárními výrazy.




