Obsah
Menu: Frekvence
Pod označením Frekvence se v menu rozhraní KonText nachází funkce pro vytváření frekvenčních distribucí. Pomocí ní je možné získat přehled typů (např. různých slov) ve výsledku hledání spolu s jejich frekvencí. Vyhledáme-li např. všechna substantiva v gen. pl., můžeme pomocí této funkce zjistit, jaké tvary se v tomto pádě a čísle vyskytují a jak často. Stejně tak je ale možné frekvenční distribuci použít na zjišťování frekvencí jednotek předcházejících či následujících, počítání lemmat v konkordanci nebo pro zjištění distribuce hledaného jevu napříč různými texty či jejich skupinami (podle genre, txtype apod.).
Frekvenční distribuce umožňuje jednak vlastní (obecné) nastavení, jednak rychlé volby (ty jsou přístupné v druhé úrovni menu).
Podobnou funkcionalitu, která se ovšem většinou vztahuje na celý korpus (nikoli pouze na jednu konkrétní konkordanci), poskytuje také funkce Nový dotaz → Seznam slov.
Rychlé volby frekvenční distribuce
Lemmata
Slovní tvary [A=a]
Vyhodnotí dotaz (KWIC) a vypíše všechny různé tvary (atribut word bez ohledu na velikost písmen) spolu s jejich frekvencí.
Dokumenty
Vyhodnotí celou konkordanci a vypíše identifikátory textů (konkrétní strukturní atribut se může lišit v závislosti na vybraném korpusu), v nichž se hledaný jev vyskytuje, spolu s frekvencí tohoto jevu v jednotlivých textech.
Typy textů
Vyhodnotí celou konkordanci a vypíše přehled strukturních atributů2), které se vztahují k typu textu (strukturní atributy txtype, genre apod.), spolu s jejich frekvencí (význam jednotlivých zkratek je k dispozici v seznamu zkratek a kódů).
Frekvenční seznam
Výsledkem funkce frekvenční distribuce je zobrazení frekvenčního seznamu, a to jednak ve formě tabulky četností, jednak v podobě grafů.
Následující příklad využití frekvenční distribuce se vztahuje ke korpusu SYN2020 a dotazu na lemma dřevo ([lemma="dřevo"]): Frekvenční distribuce slovních tvarů lemmatu dřevo bez rozlišování velikosti písmen (volba Slovní tvary [A=a]).
Tabulkové zobrazení
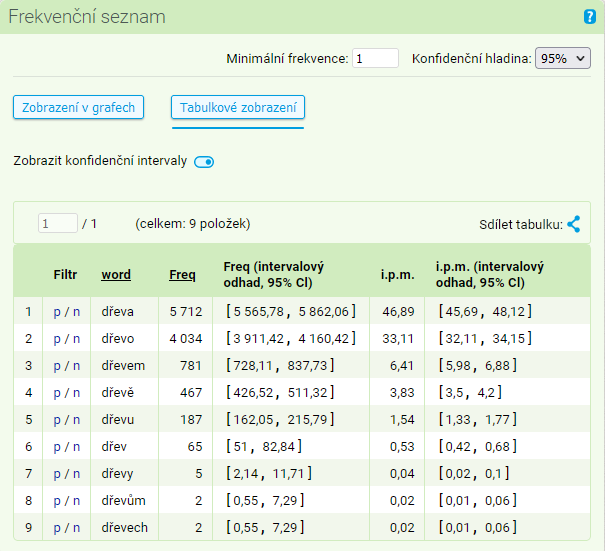
Výchozím způsobem zobrazení je tabulka s uvedením absolutních a relativních frekvencí pro jednotlivé položky (včetně možnosti zobrazení konfidenčních intervalů).
U každého slovního tvaru (atribut word) vypsaného ve frekvenční distribuci lemmatu dřevo se objevuje několik informací. Základní je informace ve sloupci frekvence, která udává absolutní četnost dané jednotky ve vyhledané konkordanci (byla-li konkordance před zadáním frekvenční distribuce nějak měněna – např. pomocí filtrů či vzorků – bude i frekvenční seznam tyto změny reflektovat). V seznamu se zobrazí všechny položky s alespoň jednotkovým výskytem. Chceme-li výpis zúžit, můžeme nastavit Minimální frekvenci na hodnotu, která vyhovuje konkrétní situaci.
Vedle sloupce s absolutní frekvencí se objevuje i položka i.p.m. Vyjadřuje relativní četnost zkoumaných jevů vzhledem k celkové velikosti korpusu. V našem případě se tvar dřeva objevuje v korpusu SYN2020 s absolutní četností 5 712, což představuje 46,89 výskytů na milion slov (i.p.m.).
Pro hodnoty absolutní i relativní frekvence lze pomocí další volby zobrazit i hodnoty konfidenčních intervalů, tj. rozsahy, v nichž by se dané frekvence (s pravděpodobností na určené konfidenční hladině) vyskytovaly v jiných, podobně sestavených korpusech srovnatelné velikosti. Konfidenční hladina je nastavena na 95 % a je možné ji uživatelsky změnit pomocí volby na 99 % nebo 90 %.
V seznamu nalevo od slovního tvaru jsou odkazy p/n, které slouží pro rychlé vyvolání pozitivního a negativního filtru. Kliknutím na p v řádku reprezentujícím frekvenci tvaru dřeva vyfiltrujeme ze stávající konkordance pouze tento tvar, analogicky po aktivaci n budou z aktuální konkordance vyloučeny všechny výskyty daného tvaru.
Při kliknutí na nadpis sloupce se tabulka automaticky podle zvoleného sloupce přetřídí. Je tak možné získat i seznam setříděný abecedně (vedle běžného frekvenčně seřazeného výpisu).
Pomocí funkce Sdílet tabulku (odkaz je umístěn v řádku nad tabulkou) se vygeneruje trvalý odkaz na tabulku, který lze přímo z okna formuláře poslat na zadanou adresu e-mailem nebo později uvést v článku, studii apod.
Zobrazení v grafech
Grafické zobrazení umožňuje vizualizovat informace představené v předchozím oddílu (absolutní a relativní frekvence položek s jejich konfidenčními intervaly) do podoby dvou typů grafů: horizontálního sloupcového grafu a grafu typu „word cloud“.
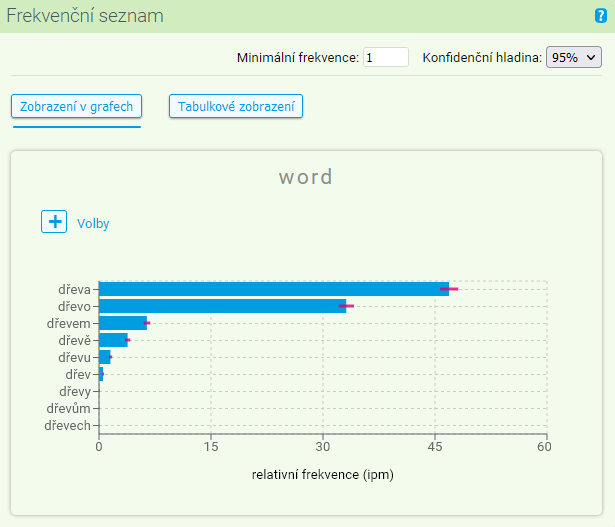
Ve výchozím nastavení se zobrazuje sloupcový graf s hodnotami relativních četností včetně konfidenčních intervalů na hladině 95 %.
Po rozkliknutí voleb nad grafem pomocí (+) je možné vlastnosti grafu upravit. Místo hodnot relativní četnosti lze zobrazit četnosti absolutní, dále lze omezit počet položek v grafu, seřadit položky podle abecedy namísto frekvenčního třídění a také exportovat graf jako obrázek.
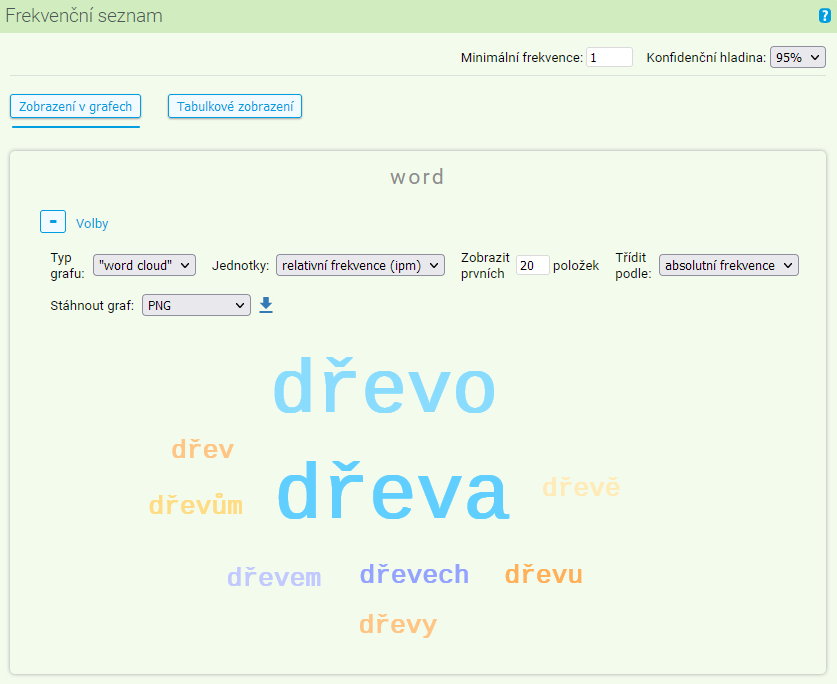
Nakonec je možné graf přepnout do podoby grafu typu „word cloud“, který zobrazuje skupinu zkoumaných položek (v našem příkladů tvarů slov) ve velikostech poměrně odpovídající jejich četnostem. Pro tento typ grafu je v uživatelském nastavení relevantní pouze možnost exportu grafu a omezení počtu položek v grafu.
Vlastní nastavení frekvenční distribuce
Formulář, který se zobrazí po kliknutí na volbu Frekvence → Vlastní (resp. po klávesové zkratce Shift + F na obrazovce s konkordancí), má čtyři možnosti:
- frekvenční distribuci podle typů textu neboli strukturních atributů (jako je
txtype,genrenebosrclang) - disperzi znázorňující rozložení hledané konkordance napříč celým korpusem
- frekvenční distribuci odrážející vzájemný vztah dvou atributů (pozičních i strukturních)
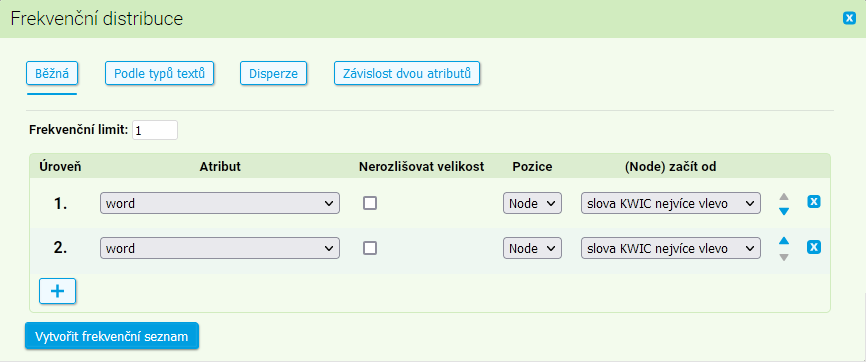
Běžná frekvenční distribuce
Běžná frekvenční distribuce umožňuje počítat frekvenční distribuci na libovolné pozici konkordance v rozmezí 6 pozic nalevo až 6 pozic napravo od KWICu. Ve formuláři je nejprve třeba zvolit, jaký atribut chceme ve frekvenční distribuci počítat (např. v nových korpusech řady SYN jsou k dispozici poziční atributy word, lemma, sublemma, tag, verbtag, lc, pos, case).
Dále je třeba zvolit, zda se frekvenční distribuce má počítat s ohledem na velikost písmen. Při volbě case-insensitive jsou všechny položky převedeny na malá písmena bez ohledu na to, s jakou velikostí písmen se reálně v korpusu objevují.
Při vlastním nastavení frekvenční distribuce se nemusíme omezovat pouze na KWIC (jako je tomu v případě rychlých voleb). Může být počítána z kterékoli kontextové pozice v pravém nebo levém okolí od hledaného slova. Položka Pozice ve formuláři umožňuje vybrat jak pozice v levém (předcházejícím) kontextu (6L–1L), samotný KWIC, tak pozice v pravém (následujícím) kontextu (1R–6R). Číslování pozic (podle současné i starší notace) shrnuje následující tabulka:
| konkordance | místnosti | . | Byly | z | těžkého | tmavého | dřeva | a | zlověstně | zaskřípaly | . | Poslepu | jsem |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pozice | 6L | 5L | 4L | 3L | 2L | 1L | KWIC | 1R | 2R | 3R | 4R | 5R | 6R |
| pozice (starší notace) | -6 | -5 | -4 | -3 | -2 | -1 | KWIC | 1 | 2 | 3 | 4 | 5 | 6 |
S určováním pozice toho, co má být předmětem výpočtu frekvenční distribuce, může nastat problém v případě, že hledaný KWIC je víceslovný (např. při hledání fráze dřevo a uhlí). Pak je třeba specifikovat, kterou hranici KWICu považujeme za výchozí pro výpočet (zda pravou, nebo levou), což umožňuje položka (Node) začít od. Tabulka shrnuje, jak se změní označení kontextových pozic podle toho, který z konců víceslovného KWICu určíme za rozhodující.
| konkordance | znečišťování | ovzduší | . | Moderní | kotle | na | dřevo | a | uhlí | splňují | dnes | všechny | požadavky | z | hlediska |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pozice (počítáno zleva) | 6L | 5L | 4L | 3L | 2L | 1L | KWIC | 1R | 2R | 3R | 4R | 5R | 6R | 7R | 8R |
| pozice (počítáno zprava) | 8L | 7L | 6L | 5L | 4L | 3L | 2L | 1L | KWIC | 1R | 2R | 3R | 4R | 5R | 6R |
Pokud chceme vytvořit frekvenční distribuci nikoli pouze jednotek, ale například dvojic slov (bigramů) nebo rozsáhlejších celků, musíme přidat další úroveň frekvenční distribuce. Ve formuláři přibude další řádek se shodnými možnostmi nastavení. Jednodušší variantu představuje rychlá volba frekvenční distribuce nazvaná Slovní tvary - pokud ji aplikujeme na víceslovný KWIC (např. po vyhledání dvou po sobě jdoucích adverbií typu pomalu a opatrně [tag="D.*"][word="a"][tag="D.*"]), ukáže nám vyhledané víceslovné výrazy seřazené podle frekvence bez složitého nastavování.
V případě, že jsme se specifikací spokojeni, spustíme výpočet kliknutím na tlačítko Vytvořit frekvenční seznam. V základním nastavení se ve výsledku zobrazí všechny položky s alespoň jednotkovým výskytem. Chceme-li výpis zúžit, můžeme nastavit Frekvenční limit na hodnotu, která vyhovuje konkrétní situaci.
Frekvenční distribuce podle typů textů
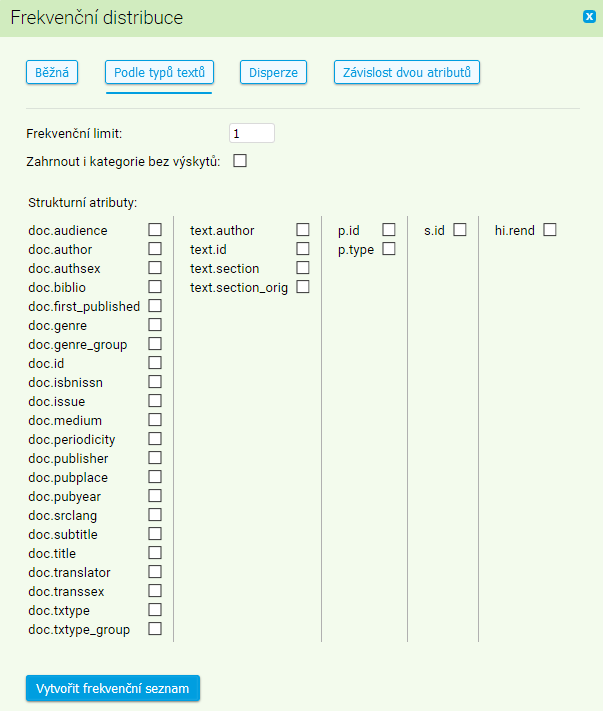
Frekvenční distribuci podle typů textů použijeme naopak v situacích, kdy těžiště výzkumného zájmu spočívá v textech, z nichž výskyty v konkordanci pocházejí (pokud nás tedy zajímá typ textu, zdrojový jazyk, médium apod.).
V zobrazeném seznamu pomocí myši zvýrazníme ty metainformace, jejichž hodnoty chceme ve frekvenční distribuci vyhodnotit. Vybereme-li hodnot víc, bude ve výsledku víc seznamů – nejde tudíž jako v předchozím případě o víceúrovňovou analýzu (kdy by se kombinovaly údaje různých úrovní), ale o postupné spuštění několika frekvenčních distribucí a zobrazení několika frekvenčních seznamů.
I zde můžeme nastavit frekvenční limit, chceme-li omezit počet výsledků v seznamu. Zároveň je ale možné pomocí volby Zahrnout i kategorie bez výskytů zobrazit v seznamu ty hodnoty atributů, které se v konkordanci vůbec neobjevily. Např. lemma dřevo se v SYN2010 ani jednou neobjevuje v písních (txtype SON). Je-li tato volba zaškrtnuta, txtype SON se ve frekvenční distribuci přesto objeví, a to s nulovou frekvencí.
Příklad využití: frekvenční seznam podle typů textů
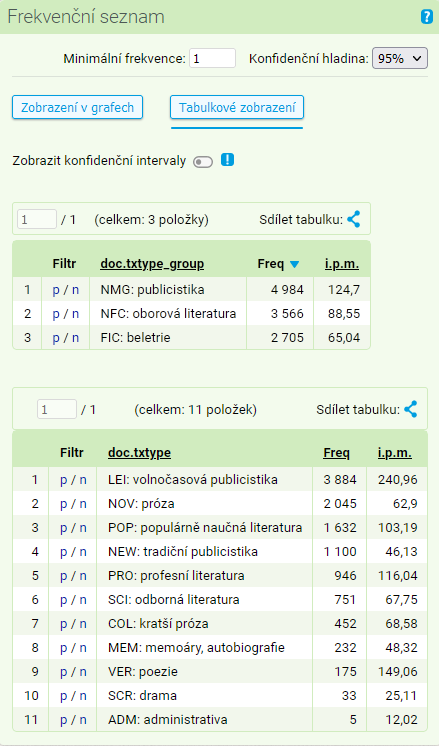
Následující příklad využití frekvenční distribuce se vztahuje ke korpusu SYN2020 a dotazu na lemma dřevo ([lemma="dřevo"]): Frekvenční distribuce hodnot strukturních atributů txtype a txtype_group lemmatu dřevo (bez hodnot s nulovou frekvencí).
Výpis frekvenční distribuce podle strukturních atributů má stejnou strukturu jako výpis podle pozičních atributů. Zvláštní důležitost zde má hodnota i.p.m., která se zobrazuje u každé položky (hodnoty strukturního atributu, který jsme zvolili). Vyjadřuje relativní četnost jevů zobrazených v konkordanci vzhledem k celkové velikosti části korpusu s danou hodnotou strukturního atributu. V našem případě se lemma dřevo objevuje v korpusu SYN2020 s četností 3566 v oborové literatuře (NFC). Vzhledem k celkovému podílu oborové literatury v korpusu (33 %) to představuje 88,55 výskytů na milion slov (i.p.m.).
Stejně jako u jednotek pozičních je u strukturních atributů možné tabulku přetřídit podle libovolného sloupce; výhodné je to zejména v situaci, kdy potřebujeme znát pořadí podle relativní četnosti, která umožňuje srovnání počtu výskytů i v nestejně velkých částech korpusu.
Disperze
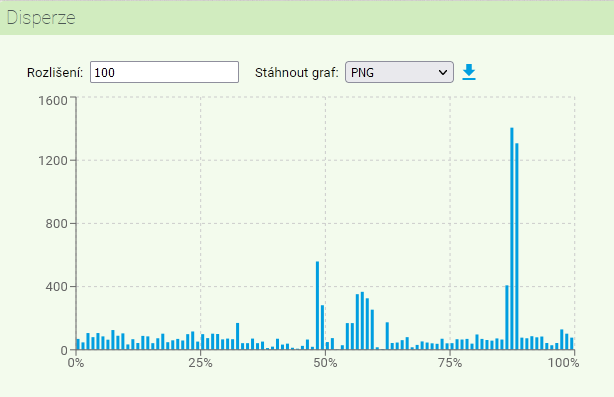
Funkce Disperze umožňuje graficky znázornit rozložení daného vyhledaného jevu napříč textem/korpusem. V úvodním formuláři je třeba nastavit počet úseků (nejvýše 1000), na něž bude korpus pro účel zobrazení disperze rozdělen. Ve výsledném grafu jsou pak na ose y zaneseny počty výskytů vyhledaného jevu pro každý úsek.
Závislost dvou atributů
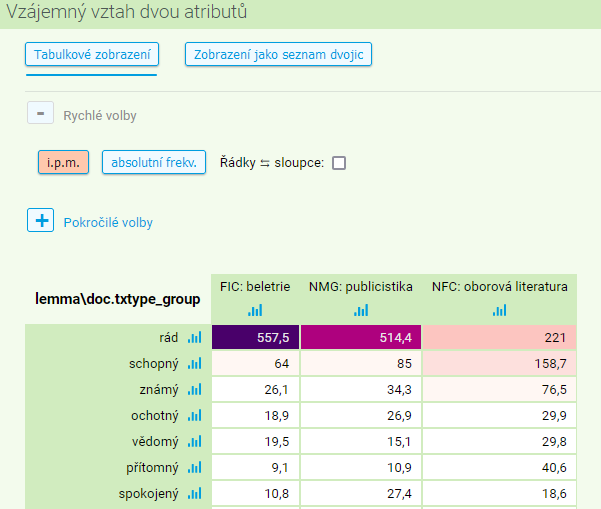
Poslední typ frekvenční distribuce odráží vzájemný vztah dvou atributů, a to jak pozičních, tak strukturních. Takto můžeme zjistit například to, jaká jmenná adjektiva ([tag="AC..-.*"], bez zahrnutí ustrnulých popředložkových tvarů typu na živo) jsou typická pro jednotlivé žánry či typy textů (pro SYN2020). V menu Frekvence → Vlastní zvolíme možnost Závislost dvou atributů a tyto dva atributy vybereme z nabídky, v našem případě jako první atribut (v tabulce s výsledky se bude zobrazovat v řádcích) zvolíme lemma, jako druhý (zobrazovaný ve sloupcích) doc.txtype_group (pod Typy textů). Rovněž můžeme nastavit minimální hodnoty, ať už ve frekvenci absolutní či relativní anebo v percentilech jedné z nich.
Po potvrzení volby Vytvořit frekvenční seznam se objeví tabulka s počty výskytů jednotlivých adjektiv ve třech makrotřídách textů (tedy v beletrii, oborové literatuře a publicistice), řazenými defaultně podle frekvence sestupně. Zobrazení výsledků je možno podle potřeb dále měnit: střídat absolutní frekvenci s relativní (i.p.m.) či přepnout orientaci řádků a sloupců, případně namísto tabulky zobrazit seznam dvojic daných atributů. V rámci pokročilých voleb lze mj. třídit řádky podle trojího kritéria (hodnota atributu, součet absolutní/relativní frekvence v řádku či sloupci), nastavit konfidenční interval či mapování barev (bližší informace – viz ikonka otazníku vedle volby Mapování barev). Při zobrazení relativních frekvencí (i.p.m.) lze pomocí ikony grafu zobrazit distribuci jevu v řádku nebo ve sloupci pomocí grafu s naznačenými konfidenčními intervaly.