Toto je starší verze dokumentu!
Treq

Aplikace Treq slouží k obousměrnému prohledávání česko-cizojazyčných a anglicko-cizojazyčných slovníků vytvořených automaticky na základě dat paralelního korpusu InterCorp. Lze v ní snadno a pohodlně vyhledávat možné překladové ekvivalenty či se inspirovat při hledání synonym.
Treq je webová aplikace (k jejímu užívání stačí internetový prohlížeč) a je dostupná bez registrace všem uživatelům na adrese treq.korpus.cz.
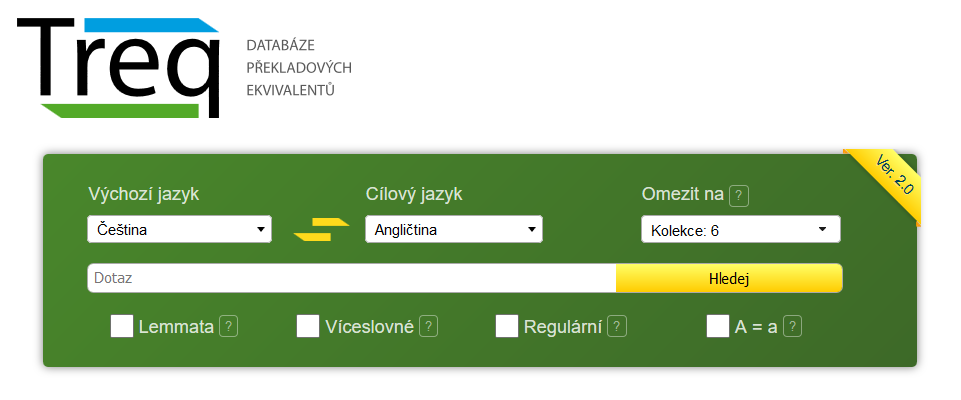
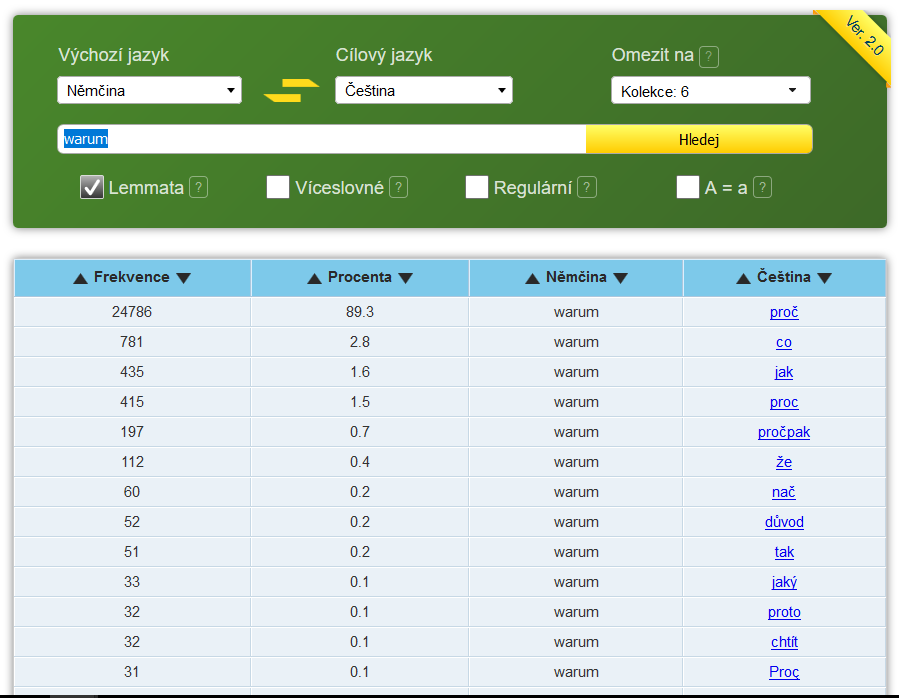
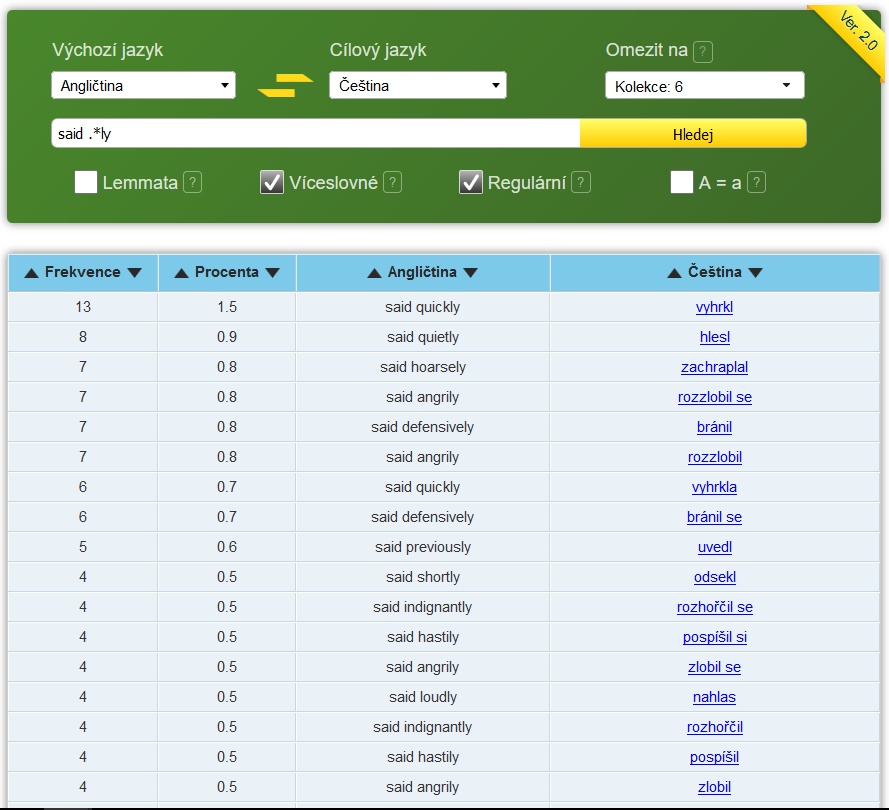
Nejdříve zvolíme výchozí jazyk, v němž je hledaný výraz, a cílový jazyk, do něhož jej chceme přeložit. Slovo můžeme zadat v konkrétním tvaru, v základním slovníkovém tvaru (Lemmata), lze vyhledávat i víceslovnou jednotku (Víceslovné), využít při hledání regulární výrazy (Regulární) nebo v dotazu nerozlišovat velikost písmen (A = a). Můžeme si také vybrat, zda má být výsledek založen na překladech beletristického jádra, jednotlivých kolekcí, nebo všech textů v InterCorpu (Omezit na:). Pak slovo zadáme (Dotaz:) a klikneme na Hledej. Výsledkem dotazu je seznam nalezených překladů zadaného slova, defaultně setříděných sestupně podle frekvence. Realizaci dané dvojice výrazů v kontextu si lze ověřit pomocí hypertextového odkazu, jimž jsou jednotlivé ekvivalenty opatřeny. Počet výskytů udávaný v rozhraní Treq a KonText se však může lišit – paralelní dotaz najde i konkordance, v nichž potenciální ekvivalent odpovídá jinému slovu.
Princip zarovnání
Při přípravě dat pro databázi Treq jsou nejprve z celého korpusu dané jazykové verze InterCorpu vybrány pouze věty, které jsou k češtině zarovnány v poměru 1:1. Výhradně jednoduchá zarovnání používáme proto, že obvykle bývají spolehlivější; zvláště v případě automaticky zarovnaných textů tak můžeme předejít zanesení potenciálních chyb.
Následuje automatické zarovnání po slovech v rámci těchto vět pomocí programu GIZA++1). Ve starších verzích Trequ se využívalo zarovnání pomocí metody intersection, které páruje jedno slovo s jedním ekvivalentem, např.:


Tzn. že v první větě první slovo ve zdrojovém jazyku (0) odpovídá prvnímu slovu v jazyku cílovém (0), druhé slovo (1) odpovídá třetímu slovu (2) atd. Počínaje verzí 2.0 byla navíc využita metoda grow-diag-final-and, která umožňuje vytvářet i komplikovanější zarovnání více slov na obou stranách překladu. Takové zarovnání pak může vypadat třeba takto:


Oproti případu výše tu druhé slovo ve zdrojovém jazyku (1) neodpovídá pouze třetímu (2), ale též druhému a čtvrtému (1, 3) slovu v jazyku cílovém atd. Z takovéhoto zarovnání je následně vybráno co největší množství kombinací slov, které toto zarovnání umožňuje (viz též příklad extrahovaných ekvivalentů níže). V obou případech jsou zarovnané dvojice slov setříděny a sečteny, výsledky automatické extrakce však už nejsou nijak revidovány a uživateli jsou poskytnuty formou seznamu nalezených ekvivalentů zadaného výrazu, doplněných o absolutní a relativní frekvenci. Tyto údaje jsou uživatelovým primárním vodítkem: čím častěji se ekvivalent hledaného výrazu vyskytl ve srovnání s ostatními ekvivalenty, tím vyšší je pravděpodobnost, že je funkční.
V jakém poměru jsou frekvence nalezené v KonTextu s těmi zobrazovanými Treqem, ukazuje přiložená tabulka. Ta vyčísluje různé typy dat v jednotlivých fázích jejich zpracování pro Treq z anglické složky IC v9 (víceslovná varianta).

Po dílčích krocích lze sledovat postupný úbytek dat, která jsou ve výsledném slovníku použita. V prvním kroku použijeme pouze zarovnání vět 1:1 – tím přijdeme o 20,7 % vět. Následně se vyberou na základě zarovnání z programu GIZA++ jedno- a víceslovné ekvivalenty. Vztah mezi velikostí původního korpusu a počtem vyextrahovaných ekvivalentů však nelze jasně předvídat, zvláště pak u víceslovných ekvivalentů, kde vznikají nejrůznější kombinace stejných slov (viz tučně vysázené dvojice níže). Takto by např. vypadal abecedně řazený soupis česko-anglických párů extrahovaných z druhé příkladové věty:
a – and
chybný – bad
krok – move
lidí – people
naštvalo – angry
považovalo – been widely regarded as
považovalo za – been widely regarded as
považovalo za – regarded a
se – made
Spoustu – lot of
to – This
to – very
za – regarded a
. – .
Ve třetím kroku se v rámci celého textu sečtou řádky, které jsou stejné na obou stranách zarovnání. Tak získáme seznam a frekvenci ekvivalentů. Nakonec, v závěrečném kroku, vyřadíme všechny protějšky obsahující interpunkci, čímž obdržíme finální verzi slovníku. U všech jazykových párů, kde je k dispozici lemmatizace na obou stranách zarovnání, aplikujeme stejný postup i na lemmatizovanou podobu dat (na počátek být stvořit vesmír . – in the beginning the universe be create .).
Obrázky aplikace