

Lesson 5: Introduction to metadata
The OBC is particularly useful in studying language change in relation to its social context due to its great amount of textual, sociological, and pragmatic annotations. The texts of the OBC are partly transcriptions of spoken language as it was used in court proceedings, therefore it allows us to study the language outside of the relatively standardized usage of the written media of the period.
Structural attributes and metadata
The Old Bailey Corpus consists of 637 court proceedings; each proceeding makes up one individual text of the corpus. Each text is tagged for its metainformation, including the date of the trial, the year of publishing, the categories and subcategories of the offences, the verdicts, and the punishments (for more information on the meanings of these categories, see Crime, Justice and Punishment). For the full list of attributes of the texts, see the table below:
| “text” structure attributes | Description |
| collection | text collection |
| date | date of publishing |
| decade | decade of publishing |
| id | identification number |
| offenceCategory | type of offence(s) committed by the defendant(s) |
| offenceSubcategory | subtype of offence(s) committed by the defendant(s) |
| period | period of publishing |
| punishmentCategory | type of punishment(s) inflicted on the defendant(s) |
| punishmentSubcategory | subtype of punishment(s) inflicted on the defendant(s) |
| type | text type |
| uri | text identifier |
| url | link to the full account |
| verdictCategory | type of verdict(s) given at the trial |
| verdictSubcategory | subtype of verdict(s) given at the trial |
| year | publication year |
There are two issues to be addressed: firstly, it is the fact that not every variable is always known, therefore some information may occasionally be missing.
Secondly, oftentimes the trials involved multiple defendants (and hence multiple offences, punishments, victims etc.), and the way the trials were recorded and later tagged makes it often impossible (without reading the full trial accounts and sometimes not even after that) to distinguish which offence, verdict, punishment etc. are assigned to which defendant or which defendant is speaking at a given moment (more on this topic in Lesson 6).
The direct speech in the text is tagged as individual utterances, which are assigned the following parameters:
- Pragmatic: speaker’s role in the court (defendant, lawyer, judge, witness etc.)
- Textual: scribe, printer, publisher of the individual proceedings (these are already provided in the metadata of the text, but providing these parameters at the utterance level makes some type of queries much simpler)
For the full list of attributes of the utterances, see the table below:
| “utterance” structure attributes | Description | “utterance” structure attributes | Description |
| editor | editor of the text | speaker_hisclass | social class of the speaker (according to HISCLASS) |
| id | identifier of the utterance | speaker_hiscoapprentice | is the speaker an apprentice? |
| n | number of the utterance in the proceedings | speaker_hiscocode | code of the occupation of the speaker (according to HISCO) |
| ntrial | number of the utterance in the trial | speaker_hiscolabel | description of the occupation of the speaker |
| period | period containing the year of the trial | speaker_id | identifier of the speaker |
| printer | printer of the text | speaker_role | the speaker’s role at the trial |
| publisher | publisher of the text | speaker_sex | sex of the speaker |
| scribe | scribe | decade | decade containing the year of publication of the text |
| speaker_age | age of the speaker | trial | trial identifier |
| speaker_class | social class of the speaker (high/low) | wc | word count of the utterance |
| speaker_decade | speaker’s age by decade | year | year in which the utterance was spoken |
Variation and changes in grammar
During the 18th and 19th centuries, there were various grammatical structures in use which would strike present-day readers as peculiar in standard English. Among these were, for example, the use of the double negative and double comparative. Both of these features were condemned by the prescriptive grammarians, and so was the use of the split infinitive, constructions with mismatched subjective and objective pronouns, and constructions such as he/she don’t. Although the usage of such structures was frowned upon, they were still present both in the written and the spoken medium. In this lesson, we will look at one linguistic feature which was an innovation in the English of the 18th and 19th centuries: the progressive passive tense.
Searching the corpus
Verbs in the progressive passive tense are formed by the auxiliary verb be followed by the present participle form being plus the past participle of a full verb, e.g. I am being watched, the house was being built. Searching for such constructions is done best by the use of tags (see Lesson 4).
For the auxiliary verb, we need to search for am, are, is, was and were (if we wish to include both present and past progressive passive) – tagged as VBM, VBR, VBZ, VBDZ and VBDR respectively. The tags should be used in the query instead of the full forms of the verbs, as the tags encompass the contracted forms as well as any unusual spellings which you would not be able to find just by searching for the full forms. In this case, it is not advisable to use all tags starting with V (using e.g. “V.*” expression), as the concordance would then include other verb forms as well. Rather, it is necessary to type out all the tags and separate them with the vertical bar |, which can be used inside the token:
[tag=“VBM|VBR|VBZ|VBDZ|VBDR”]
The following element is being, which is invariable:
[tag=“VBM|VBR|VBZ|VBDZ|VBDR”] [word=“being”]
Alternatively, you can use the tag VBG ([tag=“VBG”]) instead of the word being.
For the lexical verb, we are looking for all past participles. According to the tagset, this verb form is tagged either as VVN or VVNK. Hence, we can use the shortened version VVN.*. The resulting query should look like this:
[tag=“VBM|VBR|VBZ|VBDZ|VBDR”] [word=“being”] [tag=“VVN.*”]
If you wish to see an overview of the structural attributes of the whole concordance along with their frequencies, click on Frequency → Text Types.
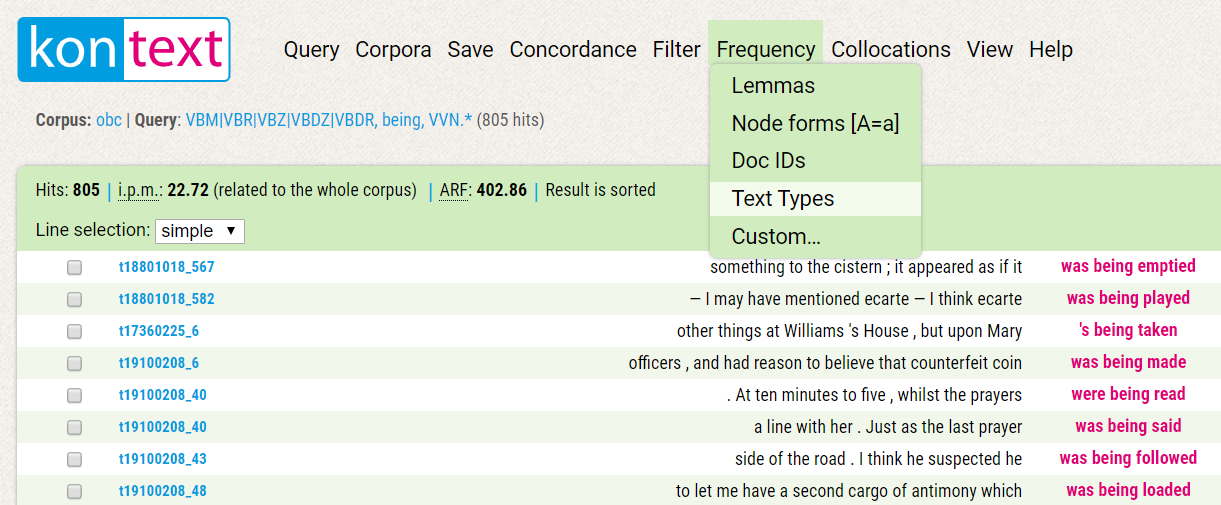
This will provide you with lists of metainformation with their frequencies. For example, under the utterance.text_decade column, you can see in which decades the progressive passive was used most frequently:
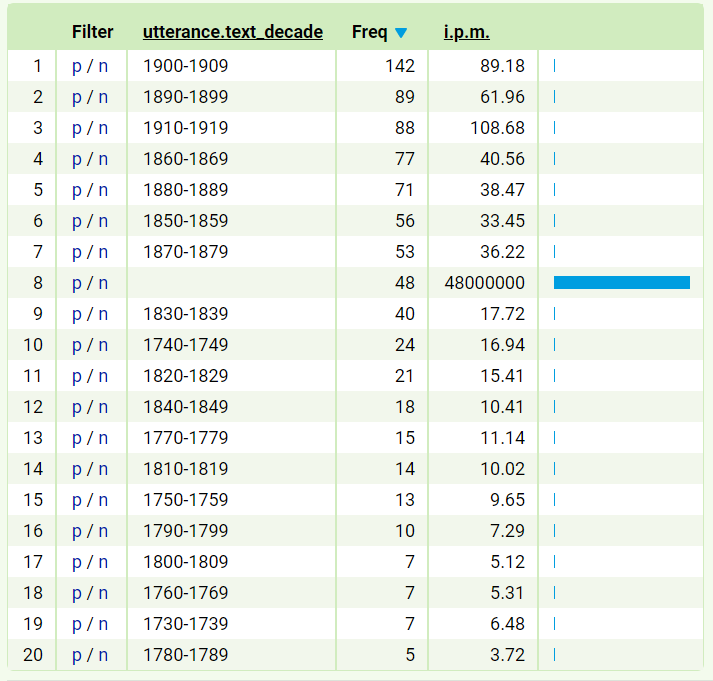
It is important to note here, that some of the utterances are not tagged fully; in this case, there are 48 utterances that are missing the information about the decade in which they were written. You can use the negative filter (p/n) to discard them and work only with the fully annotated data.
By clicking on the header of each column, you can change the sorting – alphabetically according to the labels of that attribute (here decades), according to the frequency or i.p.m. Here i.p.m. (Items Per Million) indicates the relative frequency of the given form in relation to the overall size of the part of the corpus tagged with the respective value of the structural attribute (e.g. in this case the number of occurrences per million tokens in each decade). The relative frequency allows for comparison of the number of occurrences in differently-sized parts of the corpus.
By changing the sorting to according to i.p.m. (marked by the little blue arrow), we can prove that the passive progressive tense was an innovation indeed, as the decades are in an almost perfect chronological order:
If you wish to see the metadata of individual occurrences in the corpus, click on the blue ID number at the beginning of the line when viewing the concordance.
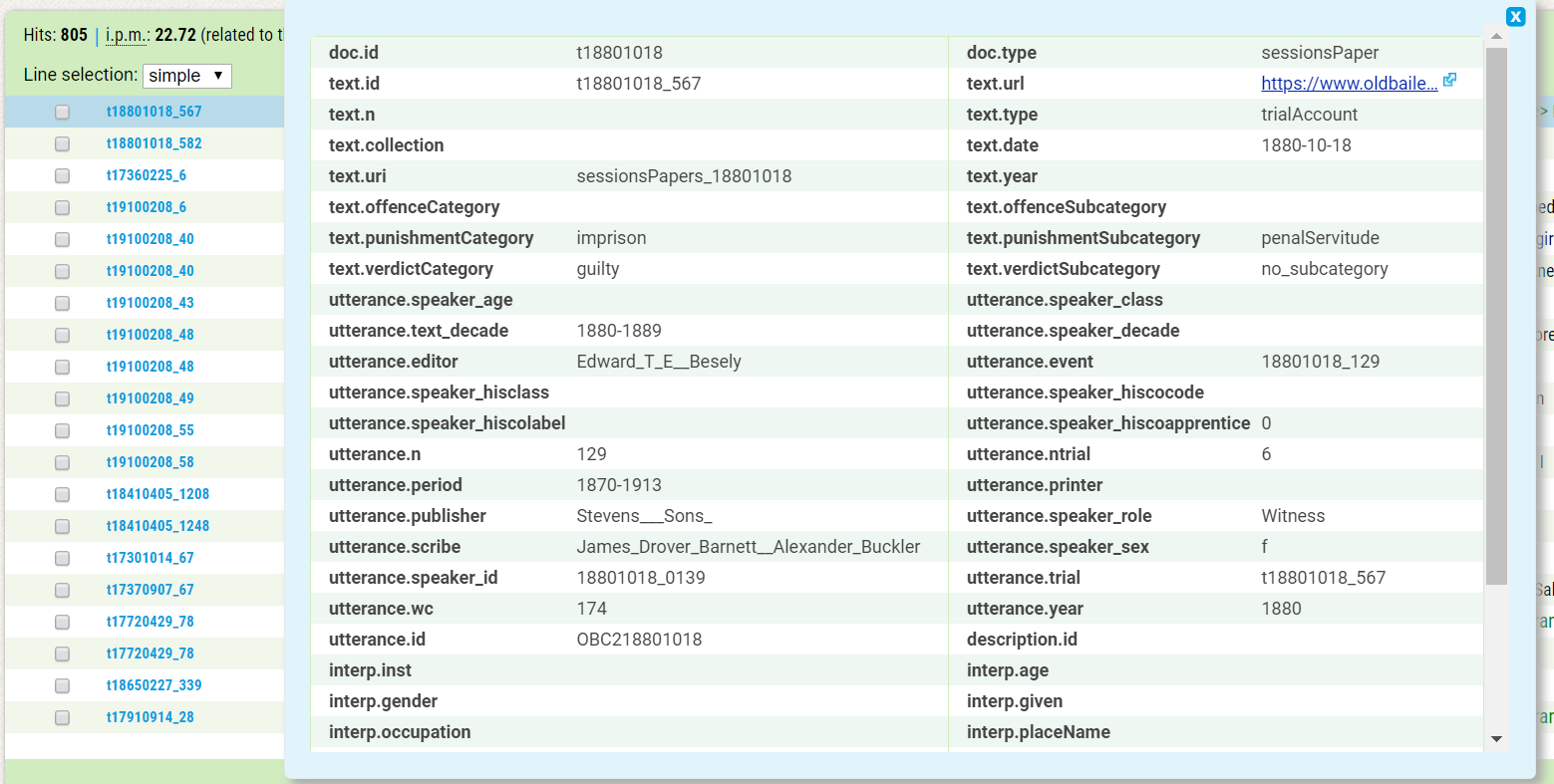
Here you can see all the information available for the given utterance. As was mentioned above, some information may be missing. You can access the whole text of the proceeding including the scan of the original publication by clicking on the link under text.url.
Task:
- Try searching for all occurrences of the split infinitive (e.g. to immediately follow) and double comparative (e.g. more commoner)
- Make sure the query type is set to CQL
- Make use of the tags from the tagset
- Look at the text types list and find when, in which contexts (e.g. type of offence) and by whom these structures were most frequently used
You will find the solution here.
If you are ready, you can continue to Lesson 6.




