

This is an old revision of the document!
Corpus SYN2015
| Name | SYN2015 | |
|---|---|---|
| Positions | Number of positions (tokens) | 120 748 715 |
| Number of positions (excl. punctuation) | 100 838 568 | |
| Number of word forms | 1 751 599 | |
| Number of lemmas | 777 011 | |
| Structures | Number of documents <doc> | 3 376 |
| Number of texts <text> | 114 492 | |
| Number of paragraphs <p> | 2 805 065 | |
| Number of sentences <s> | 8 004 732 | |
| Further information | Reference corpus | YES |
| Representative corpus | YES | |
| Publication year | 2015 | |
SYN2015 is a representative corpus of contemporary written Czech published in December 2015. SYN2015 is a sequel of the representative corpora of the SYN series (SYN2000, SYN2005, SYN2010), but at the same time, it reflects necessary methodological and technological enhancements outlined below.
Approach adopted to representativeness differs from previous corpora of the SYN-series. SYN2015 is designed to contain a large number of texts in order to cover vast majority of varieties the corpus aims to represent. This corresponds to Biber's notion of representativeness in terms of texts as products. Unlike the previous corpora in this series, SYN2015 is designed as representative, but not claimed to be balanced.
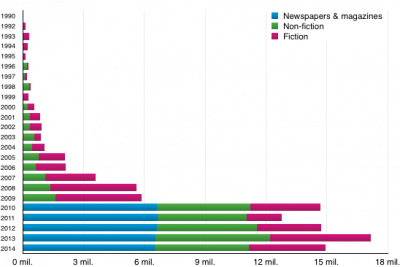
SYN2015 is designed as a representation of contemporary printed language of the last five-year period, i.e. 2010–2014. As the borders of synchronicity vary across the registers, the following criteria for inclusion of the individual texts into SYN2015 have been adopted (based on the three top-level categories, cf. below):
- fiction: publication date within the last 25 years and first publication date within the last 75 years;
- non-fiction: first publication date within the last 25 years;
- newspapers and magazines: publication date within the given five-year period.
The original text classification scheme of the SYN series has been updated and revised; both original and revised classifications are based on text-external criteria that reflect predominant function of a text. The revision has been made with respect to comparability with the original scheme, with the most significant change made to the sub-classification of non-fiction adopted from the Czech National Library and more detailed classification of newspaper texts.
| txtype | genre / genre_group | category | proportion |
|---|---|---|---|
| Fiction (FIC) | 33,33 % | ||
| NOV | novels | 26 % | |
| COL | short stories | 5 % | |
| VER | poetry | 1 % | |
| SCR | drama, screenplays | 1 % | |
| X | other | 0,33 % | |
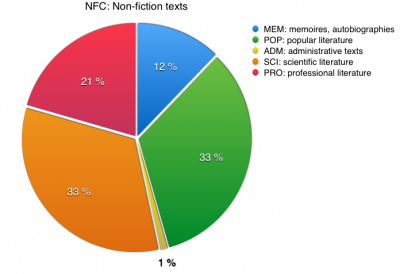
| Non-fiction (NFC) | 33,33 % | ||
| SCI/PRO/POP | HUM | humanities | 7 % |
| SSC | social sciences | 7 % | |
| NAT | natural sciences | 7 % | |
| FTS | technical sciences | 7 % | |
| ITD | interdisciplinary | 1 % | |
| MEM | memoirs, autobiographies | 4 % | |
| ADM | administrative texts | 0,33 % | |
| Newspapers and magazines (NMG) | 33,33 % | ||
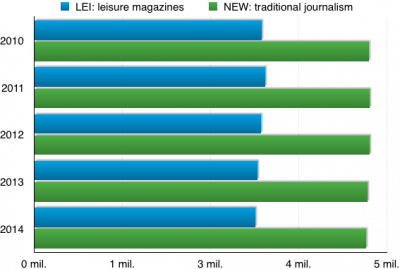
| NEW | NTW | nationawide newspapers – selected titles (MF, LN, HN, Právo) | 10 % |
| NTW | nationawide newspapers – other | 5 % | |
| REG | regional newspapers | 5 % | |
| LEI | leisure magazines | 13,33 % | |
In line with its predecessors, SYN2015 contains a large variety of texts from various publishers within the given classification category. A category is defined by a combination of two variables: text type and genre. Proportions of the particular categories in SYN2015 are set arbitrarily, yet close to the original figures.
Next to the text type and genre, metadata related to the text classification and available for every document also include medium (book, journal, textbook etc.), periodicity (daily, weekly, monthly, less than monthly, non-periodical) and audience (general, children/youth). Standard division of the newspapers into the individual articles is also supplemented by their separate classification into 13 sections (politics, economics, sports, culture, leisure, commentaries etc.) and information about the author that is available for all prominent newspaper titles.
How to cite SYN2015
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A.: SYN2015: reprezentativní korpus psané češtiny. Ústav Českého národního korpusu FF UK, Praha 2015. Dostupný z WWW: http://www.korpus.cz
Cvrček, V. – Čermáková, A. – Křen, M. (2016): Nová koncepce synchronních korpusů psané češtiny. Slovo a slovesnost, 77 (2), 83–101. ISSN 0037-7031.
Křen, M. – Cvrček, V. – Čapka, T. – Čermáková, A. – Hnátková, M. – Chlumská, L. – Jelínek, T. – Kováříková, D. – Petkevič, V. – Procházka, P. – Skoumalová, H. – Škrabal, M. – Truneček, P. – Vondřička, P. – Zasina, A. (2016): SYN2015: Representative Corpus of Contemporary Written Czech. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), 2522–2528. Portorož: ELRA. ISBN 978-2-9517408-9-1.




