Korpus SYN2010
Korpus SYN2010 je synchronní reprezentativní korpus současné psané češtiny obsahující 100 milionů textových slov (tokenů). Navazuje tak na korpusy SYN2000 a SYN2005 a tvoří s nimi řadu synchronních reprezentativních korpusů pokrývajících tři po sobě jdoucí časová období. Všechny korpusy obsahují rozdílné texty, tedy jsou disjunktní. Základní charakteristiky korpusu SYN2010 jsou shodné s korpusem SYN2005, což se týká zejména stejného pojetí reprezentativnosti založeného na recepci psaného jazyka a z něho vyplývajícího složení korpusu. Korpus SYN2010 je lemmatizovaný a tagovaný.
| Název | SYN2010 | |
|---|---|---|
| Pozice | Počet pozic (tokenů) | 121 667 413 |
| Počet pozic (tokenů) bez interpunkce | 101 219 603 | |
| Počet slovních tvarů (wordů) | 1 706 345 | |
| Počet lemmat | 785 580 | |
| Struktury | Počet opusů | 2 649 |
| Počet dokumentů | 152 634 | |
| Počet vět | 8 172 649 | |
| Další informace | Referenční | ANO |
| Reprezentativní | ANO (různé textové typy) | |
| Rok zveřejnění | 2010 | |
Změny oproti korpusu SYN2005
Oproti korpusu SYN2005 byla v korpusu SYN2010 výrazně vylepšena lemmatizace a slovnědruhové značkování; obojí je v zásadě shodné se zpracováním korpusu SYN2009PUB. Ačkoli se tedy SYN2005 a SYN2010 navzájem neliší pojetím reprezentativnosti, při případném srovnávání lexikálních frekvencí mezi nimi je třeba brát v úvahu také tyto rozdíly. Proto jsme zveřejnili srovnávací frekvenční seznamy slovních tvarů a lemmat, která obsahuje zcela nová data ze všech tří synchronních reprezentativních korpusů SYN2000, SYN2005 a SYN2010, zlemmatizovaných a morfologicky označkovaných na úrovni korpusu SYN2010. Tato data obsahují také údaje o tzv. přepočítaných frekvencích, které jsou navzájem přímo srovnatelné, a umožňují tudíž studium změn, kterými čeština za posledních 20 let prošla.
Složení korpusu SYN2010
V SYN2010 došlo ke změnám ve složení publicistiky, nezměnilo se ale vymezení synchronie v beletrii a odborné literatuře; v korpusu SYN2010 tak najdeme pouze odbornou literaturu publikovanou po roce 1989. Beletrie sice může být i starší, přesto však pro odbornou literaturu i beletrii obecně platí, že největší podíl na korpusu mají novější texty, zatímco zastoupení starších textů klesá.
Obecné složení korpusu SYN2010
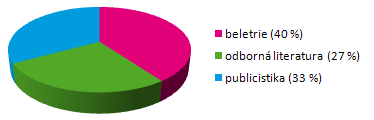
Složení publicistiky
Veškeré publicistické texty v korpusu SYN2010 jsou z let 2005-2009, přičemž každý rok má – stejně jako v korpusu SYN2005 – v publicistice stejné zastoupení (i když se samozřejmě v rámci těchto let změnily podíly jednotlivých titulů).
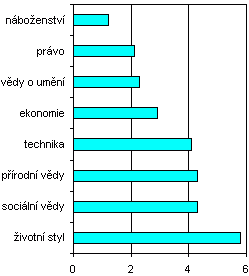
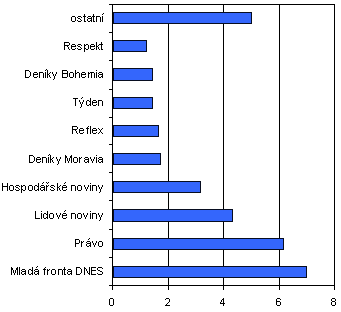
Struktura korpusu SYN2010
Mezi strukturní jednotky, na něž se člení tento korpus, patří <opus>, <doc> a <s>, tedy celý text, dokument (část textu) a věta - a pak každá jednotlivá pozice. Jejich seznam lze zobrazit pomocí položky menu Zobrazení, sekce Struktury.

K těmto strukturním jednotkám náležejí následující atributy, na obrázku seřazené pod nadpisem Metainformace.
— Michal Křen, Olga Richterová
Jak citovat SYN2010
Křen, M. – Bartoň, T. – Cvrček, V. – Hnátková, M. – Jelínek, T. – Kocek, J. – Novotná, R. – Petkevič, V. – Procházka, P. – Schmiedtová, V. – Skoumalová, H.: SYN2010: žánrově vyvážený korpus psané češtiny. Ústav Českého národního korpusu FF UK, Praha 2010. Dostupný z WWW: http://www.korpus.cz
Související odkazy
SYN • SYN2000 • SYN2005 • SYN2006PUB • SYN2009PUB