

Toto je starší verze dokumentu!
Korpus OnomOs
Korpus OnomOs je lingvisticky zpracovaná databáze textů z periodik Rudé právo (vycházelo 1920–1995) a Právo (1995–dosud). Obsahuje vždy jedno číslo z každé dekády, v níž (Rudé) Právo vycházelo. Do korpusu byly zahrnuty texty, v nichž dominuje jazyková složka; vypouštěny byly proto např. reklamy a inzeráty, programy kin, divadel a rádia, některé typy textů ze sportovní rubriky (např. přehledy výsledků a soupisky hráčů), komiksy či křížovky. Složení korpusu je podrobněji představeno na obrázku č. 1. Celkem korpus obsahuje 255 149 tokenů.
Obrázek č. 1 – struktura korpusu OnomOs (v tokenech)
Specifikem korpusu je značkování vlastních jmen, které by v budoucnu mohlo sloužit jako metodologické východisko pro projekty podobného typu. Anotace byla provedena pomocí softwaru NameTag 2 (Straková – Straka – Hajič, 2019; Ševčíková – Žabokrtský – Krůza, 2007; viz zde: https://ufal.mff.cuni.cz/nametag/2). Klasifikace, kterou užívá NameTag 2, však byla upravena, aby byla v souladu s lingvistickým, respektive onomastickým pojetím vlastních jmen (viz Šrámek, 1999 a příslušná hesla v Novém encyklopedickém slovníku češtiny online: Karlík – Nekula – Pleskalová, 2017) a se současnou onomastickou terminologií. Jejím základem jsou kategorie vyššího řádu, zastoupené antroponymy (jmény osobními; A), toponymy (jmény/názvy místními; T) a chrématonymy (názvy lidských výrobků a výtvorů; C). Každá z těchto kategorií se dělí do kategorií nižšího řádu (např. AF – rodná jména, TT – názvy teritorií, CF – názvy firem a společností). Dvoupísmenné kódování kategorií nižšího řádu vychází z jejich anglických pojmenování, případně z blízkých pojmů (např. měny jsou označeny jako CM podle angl. „money“); písmena „X“ a „Y“ jsou vyhrazena pro skupiny málo specifikované (underspecified; např. CX). Mimo klasifikaci stojí výrazy s číslovkami (n), včetně čísel v adresách (a), a některé další kategorie, které česká tradice za vlastní jména nepovažuje (e-mailové adresy [me], internetové odkazy [mi], měrné jednotky [oe], akademické tituly [pd] a většina časových výrazů, např. názvy měsíců [tm]). Transformace kategorií NameTagu 2 do nových, onomastických tříd komplexně prezentuje tabulka č. 1.
| Kategorie vyššího řádu (NameTag 2) | Kategorie nižšího řádu (NameTag 2) | Kategorie nižšího řádu (OnomOs) | Kategorie vyššího řádu (OnomOs) |
|---|---|---|---|
| p - Personal names | pf - first names | AF: first names | Antroponyma (A) |
| pm - second names | |||
| pc - inhabitant names | AI: inhabitants | ||
| pp - relig./myth persons | AM: religious and mythological names | ||
| ps - surnames | AS: surnames | ||
| p_ - underspecified | AX: underspecified anthroponyms | ||
| g - Geographical names | gl - nature areas / objects | TN: nature names | Toponyma (T) |
| gh - hydronyms | |||
| gq - urban parts | TS: settlements | ||
| gu - cities/towns | |||
| gr - territorial names | TT: territories | ||
| gt - continents | |||
| gc - states | |||
| gs - streets, squares | TU: urbanonyms | ||
| g_ - underspecified | TX: underspecified toponyms | ||
| i - Institutions | ia - conferences/contests | CC: conferences, contests and events | Chrématonyma (C) |
| if - companies, concerns… | CF: companies | ||
| ic - cult./educ./scient. inst. | CI: cultural and educational institutions | ||
| io - government/political inst. | CP: politics | ||
| i_ - underspecified | CX: underspecified institutions | ||
| m - Media names | mn - periodical | CN: periodicals | |
| ms - radio and TX stations | CT: radios and TVs | ||
| o - Artifact names | oa - cultural artifacts (books, movies) | CA: art products | |
| or - directives, norms | CD: directives and norms | ||
| om - currency units | CM: currencies | ||
| op - products | CR: products | ||
| o_ - underspecified | CY: underspecified artifacts | ||
| t - Time expressions | tf - feasts | CH: feasts |
Tabulka č. 1 – modifikace třídění vlastních jmen v NameTagu 2 pro účely korpusu OnomOs
Korpus OnomOs sestavili badatelé „ostravské onomastické školy“, která se v rámci výzkumu Katedry českého jazyka Filozofické fakulty Ostravské univerzity zaměřuje na implementaci kvantitativnělingvistických metod do vědy o vlastních jménech. Projekt vznikl s podporou grantového projektu SGS02/FF/2023 OnomOs – ostravský korpus vlastních jmen, který byl řešen na Filozofické fakultě Ostravské univerzity.
Jak vyhledávat propria v korpusu OnomOs
Vlastní jména lze v korpusu OnomOs vyhledat např. pomocí následujícího příkazu v CQL (v uvozovkách se uvádí kategorie nižšího řádu):
[] within <ne type="TT: territories" />
Výslednou konkordanci, která zachycuje teritoriální názvy, lze nalézt na obrázku č. 2. Rovněž postačí i zkrácený příkaz:
[] within <ne type="TT.*" />
V případě potřeby vyhledat kategorie vyššího řádu lze využít např. následující příkaz (v uvozovkách se uvádí první písmeno dané kategorie – A, C, nebo T):
[] within <ne type="T.*" />
Alternativním postupem je zobrazení úplného frekvenčního seznamu kategorií nižšího řádu. V takovém případě vyhledáme všechna slova v korpusu (= ponecháme dotazový řádek prázdný) a na liště zvolíme „Frekvence“ a „Vlastní…“. V oknu frekvenční distribuce vybereme možnost „Podle typů textů“ a zaškrtneme „ne.type“. Podobný postup lze uplatnit také při práci se subkorpusy (např. s prvorepublikovými čísly Rudého práva) nebo při zobrazení frekvencí jednotlivých kategorií nižšího řádu pro vybranou kategorii vyššího řádu (např. toponyma; viz obrázek č. 3).
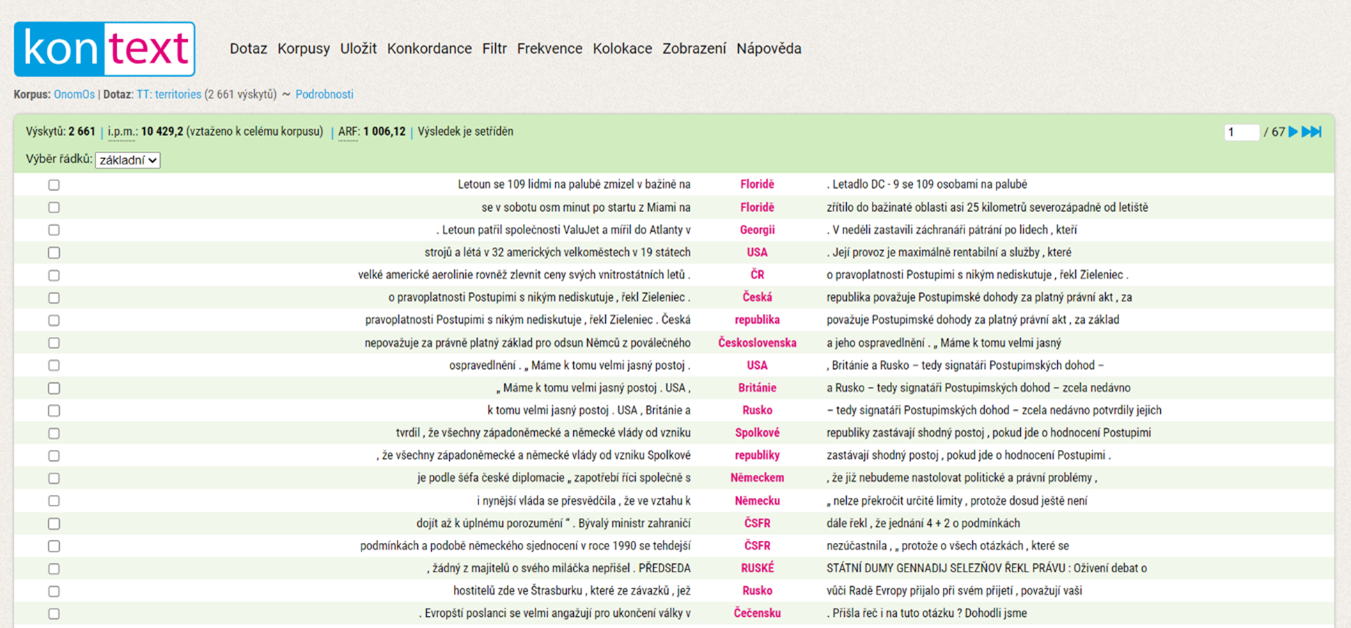
Obrázek č. 2 – konkordance všech výskytů názvů teritorií v korpusu OnomOs.




