

Table of Contents
DIN
The DIN (Difference index) is a so called effect-size metric, i.e. a measure designed1) for the purpose of quantifying the relevance differences between values. The DIN is implemented for extracting prominent units from a text (keywords) in the KWords tool.
Significance and relevance
When comparing values (e.g. frequencies of words) we should be aware not only of the statistical significance, but also whether the difference under consideration is actually relevant for the description. Statistical significance can be obtained through several tests (e.g. the chi2 test, Fisher's test or log-likelihood test).2) Significance is usually expressed as a p-value, i.e. the probability that the difference can be attributed to chance or variation within the data.
Even if the difference is significant, this does not necessarily mean that it is also relevant for the description. Even a small difference can be significant when there is a large number of measurements available. That is why statistical significance information is often combined with the effect-size estimation.
How it works
In this model example for the extraction of prominent words (keywords) from a text, let us proceed in the following way. For units which display a statistically significant difference, the DIN value is calculated in the following way:
$$DIN = 100 \times \frac{RelFq(Ttxt) - RelFq(RefC)}{RelFq(Ttxt) + RelFq(RefC)}$$
where RelFq(Ttxt) is the relative frequency of the phenomenon in the analyzed text (target text) and RelFq(RefC) is the relative frequency of the same phenomenon in the reference corpus.
The formula takes into account the difference between relative frequencies (numerator) in relation to the frequency level of the items under comparison (denominator). This reference frequency level can be represented by their average value, as can be seen in following formula, which is equivalent to the above (the coefficient has been changed from 100 to 50 in order to keep the DIN values within the desired range):
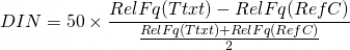
DIN Values
The DIN is designed to reach values from -100 to 100, it being understood that:
- a value of -100 means that the given phenomenon does not occur in the analyzed text and is only in the reference corpus (therefore the word is not prominent in the analyzed text)
- a value of 0 means that the given phenomenon has approximately the same relative frequency in the analyzed text and in the reference corpus (therefore the word is not prominent in the analyzed text)
- a value of 100 means that the word occurs only in the analyzed text (it can therefore be a very prominent word 3))
In texts of up to 20 thousand words in length and for the analysis of word forms, DIN values in the 75-100 range may be considered of interest, as they indicate that the unit is probably prominent and can be used as a basis for the interpretation of the entire text.
Furthermore, the KWords application offers a whole range of additional information for work with keywords. Apart from the list of keywords and their values, it also features a data dispersion graph (showing the status of the individual keywords in the text), a graph of so-called keyword links, i.e. relations between keywords in the text, and also a concordance of keywords which enables the analysis of their immediate contexts.
The KWords application was also designed for creating analyses of temporal (or other) data series. If the user inputs more texts into the application (the maximum amount is 20), the so-called multi-analysis regime is activated. This regime analyzes all the inserted texts and the results of the individual analyses are compared based on the DIN.




