Table of Contents
SyD
![]()
The SyD application (for the analysis of Synchronic and Diachronic variants) serves primarily to study competing linguistic phenomena. It serves as a supplementation of the more universal corpus managers, and can quickly and easily provide corpus results to lay users. As its name suggests, the application has two (essentially separate) parts:
- synchronic, in which it is possible to compare variants based on their frequency and distribution in the texts
- diachronic, in which it is possible to map the development tendencies in the use of the variants.
SyD is an online application (the only thing we need to use it is a web browser) and it is accessible without registration to all users at syd.korpus.cz.
It is currently available in the version 2.0, which was published in 2014 (the first version was launched in 2011). The application includes a concise manual, and the displayed results are accompanied by a detailed commentary. Just like in some of the other applications (e.g. in Morfio), a permanent link leading to the input query is available in SyDu making it appropriate for sharing and citing.
The Synchronic part
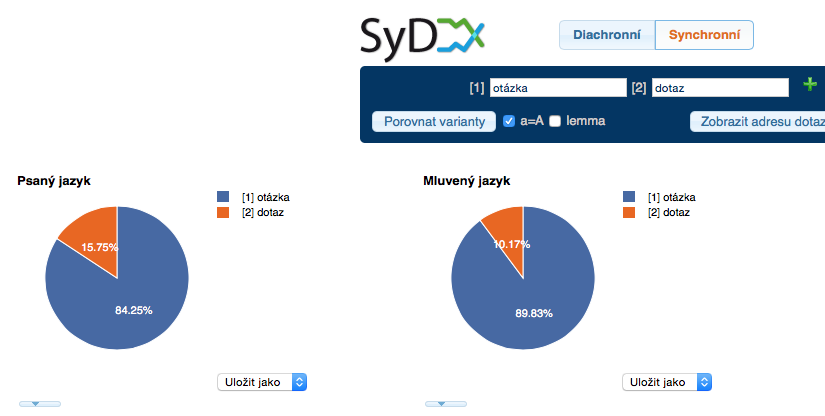
In the synchronic part the user can input two (or even more) phenomena which he wants to compare. The opposition may relate to their spelling (eg. filozofie vs. filosofie), or to their morphology (bychom vs. bysme), however it is also possible to study lexicological opposition (stále vs. pořád vs. furt), or even syntax and word order in general (sebe sama vs. sama sebe). The queries can be written very trivially (a simple input of the desired word will suffice) or with the help of a query language, CQL. The application will evaluate all queries and will display the results in the form of tables and graphs.
Corpora used in the SyD application (in the 2.0 version):
- SYN2010 for written (public) language
- KSK-Dopisy for written private (and informal) language
In the synchronic part of the analysis it is possible to use lemmatization (i.e. to search for an entire lexeme including all of its possible forms), however extra care must be taken when assessing the results. While the SYN series corpora use standard lemmatization, data for spoken Czech and for correspondence are not lemmatized, and therefore the extent of the lemma is estimated based on the written language (the query is first assessed in the SYN2010 corpus and based on the forms identified a query for the non-lemmatized corpora is constructed.
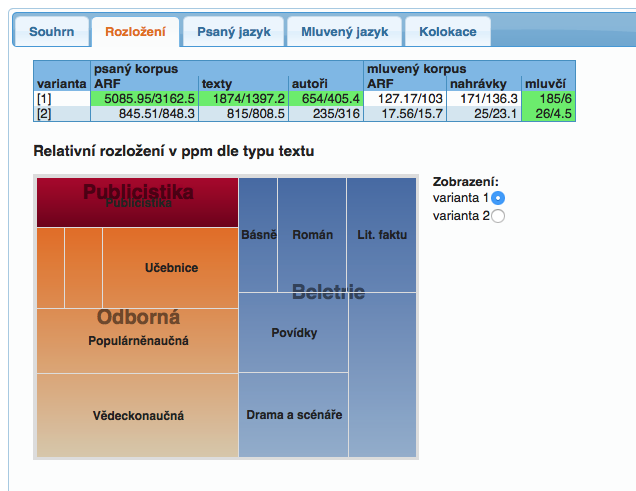
The synchronic part provides information about the distribution of phenomena in written texts (based on the structural attributes txtype and genre) and in spoken language (based on the attributes of gender, age, education and region). All data are made relative with regard to the size of the given category in the corpora.
For the analysis of the lexical differences of the examined variants, the SyD application offers a simplified version of collocational paradigms to the individual queries.
The Diachronic part
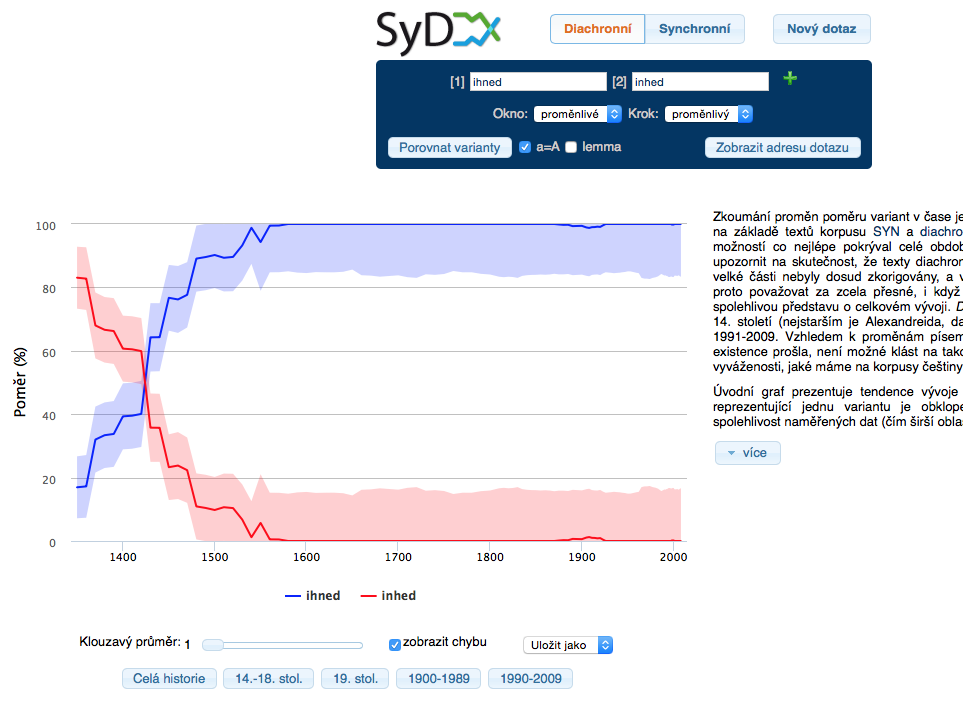
The basis for the diachronic analysis is the Diakon corpus which is composed of the Diakorp corpus texts, expanded upon with data from earlier forms of Czech which have not yet been reviewed manually. A makeshift list of source texts before the year 1989 is available in the lists section. The most modern period is represented by a selection from the synchronic corpora of the SYN series. Due to the fact that the older texts are not yet lemmatized, it is possible to use only the word attribute (word form) for queries.
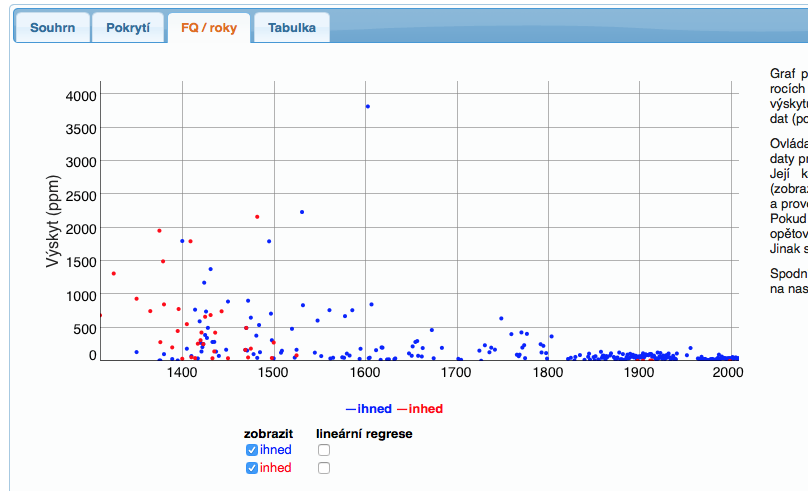
The SyD application will evaluate all queries and find their relative frequencies in various timer periods. Because the coverage of all the time periods is not optimal, it is advisable to understand the temporal information to be more of an approximation, and to use a moving average (with an adjustable window) for displaying trends. The portrayal on the timeline also includes an error rate which should also be taken into account when analyzing data.
Application images

Related links
KonText Interface • Morfio • KWords • Treq • Corpus Manager • Corpus Tools