

This is an old revision of the document!
Diakorp
Diakorp represents the diachronic section of the Czech National Corpus and aims to cover the texts of a total of seven centuries of the Czech language development. The first completed version (approximately 700 000 word forms) of the corpus was made accessible to the public in September 2005. Making the data public after the processing phase continues at a pace of about 250 000 word forms yearly.
Due to the length of the time span aimed to be covered and due to the decision to include whole texts instead of samples, Diakorp was not designed to be a representative nor balanced corpus (whether in terms of register variability or period size). These aspects will be regarded in a new line of CNC diachronic corpora (in preparation).
The structure of Diakorp version 6 (percentage of tokens per century)
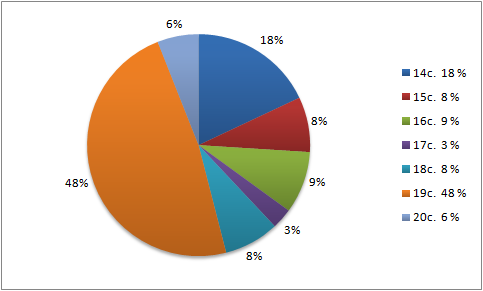
The texts entering Diakorp were originally written down or printed in different spelling systems (simple, digraphic and diacritical orthography) and their combinations. This heterogeneous character of the texts necessarily demands somewhat different processing than is usual both in the editions of older written texts (their rules are usually considerably adapted to the specific language and orthographic characteristics of a certain period, or characteristics of one author or work), and in the synchronic corpora (their rules are oriented to the contemporary state of language and to some extent are based on the current linguistic awareness of the corpus users).
The main goal in processing texts for the diachronic corpus is to ensure – despite the above mentioned variety – a uniform, the simplest possible and most universal search of texts from the entire seven-hundred-year historical development of Czech while retaining maximum relevant linguistic information contained in these texts. Two rules are applied in the diachronic corpus to meet these goals:
- The texts are transcribed, not transliterated. This rule enables to search for occurrences of specific forms of words in the diachronic corpus, just like in the synchronic one.
- The texts are tagged (provided with structure attributes). This enables obtaining various information about individual texts and their structure as well as preserving substantial amount of linguistic information, which is normally lost when transcribing texts. Special tags for headlines, footnotes, verses and other text units are used, words in foreign languages are delimited and in case of irregularly written words, the original orthography can be displayed.
In the future, the search options in the diachronic corpus will be considerably extended by lemmatization using hyperlemmata, which will allow the user to search for all occurrences of a specific lexeme, without respect to the variety of its period and other forms (for instance, when using the hyperlemma kůň (horse) in your search, it will also find the older Czech forms of kóň and kuoň).
Citing DIAKORP
Kučera, K. – Stluka, M.: DIAKORP: Diachronní korpus, version 5 from 21 Feb 2011. Ústav Českého národního korpusu FF UK, Praha 2011. Available on-line: http://www.korpus.cz




