Corpus SYN2009PUB
The SYN2009PUB is a synchronic corpus of written journalism, a sequel to SYN2006PUB. It contains exclusively journalistic texts from 1995 to 2007, the total size of the corpus is 700 million of words (tokens). All the SYN-series corpora are disjunctive as to the texts used, that is no text, which is part of one corpus, is included in the other two. Corpora SYN2000, SYN2005, SYN2006PUB and SYN2009PUB thus contain a total of 1 200 million text words (tokens).
| Name | SYN2009PUB | |
|---|---|---|
| Positions | Number of positions (tokens) | 844 881 368 |
| Number of positions (tokens) without punctuation | 717 156 997 | |
| Number of word forms (words) | 3 705 028 | |
| Number of lemmata | 2 268 070 | |
| Structural attributes | Number of opera | 11 176 |
| Number of documents | 3 262 815 | |
| Number of sentences | 55 670 721 | |
| Further information | Reference | YES |
| Representative | NO (newspapers and magazines) | |
| Publication date | 2010 | |
Changes compared to the SYN2006PUB corpus
The lemmatization and morphological tagging of SYN2009PUB were improved in comparison with the older corpora. This mainly concerns the following
- lemmatization of personal and possessive pronouns
- non-determination of grammatical categories for abbreviations and foreign words
- tokenization (detection of word form boundaries) – mainly in case of abbreviations and hyphenated word forms
- the tagset itself was slightly simplified, the differences are in elimination of values that grouped together several categories
Composition of the SYN2009PUB corpus
In should be stressed that the SYN2009PUB corpus does not claim to be representative in any way. Although tens of independent regional newspapers and other titles have been included (in addition to the rather unified Deníky Bohemia and Deníky Moravia), their overall share is very low. It is clear from the charts below that the corpus composition is balanced neither according to the year of issue, nor according to the titles. The SYN2009PUB corpus will thus be appreciated mainly by users who need to work with large amounts of data.
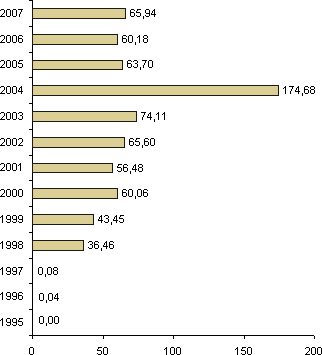
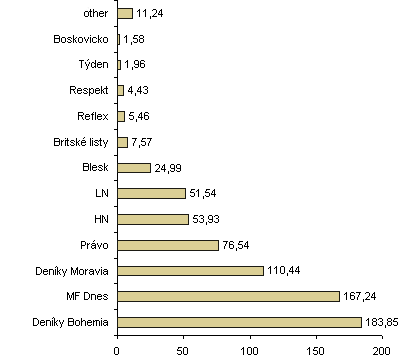
Structure of the SYN2009PUB corpus
Among the structural units used in this corpus are <opus>, <doc> and <s>; the text, document and sentence – followed by each individual position.
They can be displayed using the menu item View options.
How to cite SYN2009PUB
Křen, M. – Bartoň, T. – Hnátková, M. – Jelínek, T. – Petkevič, V. – Procházka, P. – Skoumalová, H.: SYN2009PUB: korpus psané publicistiky. Ústav Českého národního korpusu FF UK, Praha 2010. Available on-line: http://www.korpus.cz
Křen, M. (2009): The SYN Concept: Towards One-Billion Corpus of Czech. In Mahlberg, M. – González-Díaz, V. – Smith, C. (eds), Proceedings of the Corpus Linguistics Conference. Liverpool.
— Michal Křen, Olga Richterová
Related links
SYN • SYN2000 • SYN2005 • SYN2006PUB • SYN2010 • SYN2013PUB