

DIN
DIN (Difference index) je tzv. effect size metrika, tedy míra navržená1) pro účely poměřování relevance rozdílu mezi čísly. DIN se uplatňuje zejména při analýze prominence klíčových slov v aplikaci KWords.
Signifikance a relevance
Při poměřování hodnot (např. frekvencí slov) nás zajímá jednak to, jestli je jejich rozdíl statisticky signifikantní, a jednak, jestli je z hlediska popisu relevantní. První typ informace zprostředkovávají testy statistické signifikance (např. chi2 test, Fisherův test či log-likelihood test).2) Výsledek těchto testů lze převést na tzv. p-value, která vyjadřuje, jak pravděpodobné je, že daný rozdíl je způsoben přirozenou variabilitou dat nebo náhodou.
To, že rozdíl je statisticky signifikantní ještě neznamená, že je také výzkumně relevantní. I velmi malý rozdíl se může ukázat jako signifikantní, pokud máme dostatek měření. Proto se údaj o statistické signifikanci kombinuje s informací o relevanci (effect-size).
Princip fungování
Když se vrátíme k modelovému příkladu identifikace prominentních jednotek v textu (klíčových slov), tak pro jednotky, u nichž byl zaznamenán statisticky signifikantní rozdíl (podle zvoleného statistického testu), je vypočítána hodnota DIN (difference index) vypovídající o relevanci daného rozdílu:
$$DIN = 100 \times \frac{RelFq(Ttxt) - RelFq(RefC)}{RelFq(Ttxt) + RelFq(RefC)}$$
kde $RelFq(Ttxt)$ je relativní frekvence jevu ve zkoumaném textu (target text) a $RelFq(RefC)$ je relativní frekvence téhož jevu v referenčním korpusu.
V základu vzorce pro výpočet DIN je rozdíl relativních frekvencí v čitateli ku frekvenční hladině, na níž se oba jevy vyskytují. Tuto frekvenční hladinu můžeme reprezentovat např. průměrem relativních frekvencí (celý vzorec se pak nenásobí koeficientem 100, ale 50, aby byl zachován požadovaný rozsah hodnot DIN):
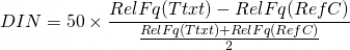
Hodnoty DIN
Hodnota DIN je koncipována tak, aby dosahovala hodnot od -100 do 100, přičemž platí, že:
- hodnota -100 znamená, že daný jev se ve zkoumaném textu nevyskytuje, je pouze v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 0 znamená, že daný jev má zhruba stejnou relativní frekvenci ve zkoumaném textu i v referenčním korpusu (slovo tedy není ve zkoumaném textu prominentní)
- hodnota 100 značí, že slovo se vyskytuje pouze ve zkoumaném textu (může se tedy jednat o velmi prominentní slovo3))
V textech o rozsahu do 20 tisíc slov a při analýze slovních tvarů je možné považovat hodnoty DIN v rozmezí 75-100 za velmi zajímavé a značí, že se jedná pravděpodobně o prominentní jednotku, která může dobře posloužit jako východisko pro interpretaci celého textu.
— Václav Cvrček




