

This is an old revision of the document!
OnomOs Corpus
The OnomOs corpus is a linguistically processed database of texts from the periodicals Rudé právo (published 1920–1995) and Právo (1995–present). It always contains one issue from each decade in which (Rudé) Právo was published. The corpus includes texts in which the language component dominates; therefore, not included are, for example, advertisements and classifieds, cinema, theatre and radio programmes, some types of texts from the sports section (e.g. scoreboards and player rosters), comics or crossword puzzles. The structure of the corpus is presented in more detail in Figure 1. In total, the corpus contains 255 149 tokens.
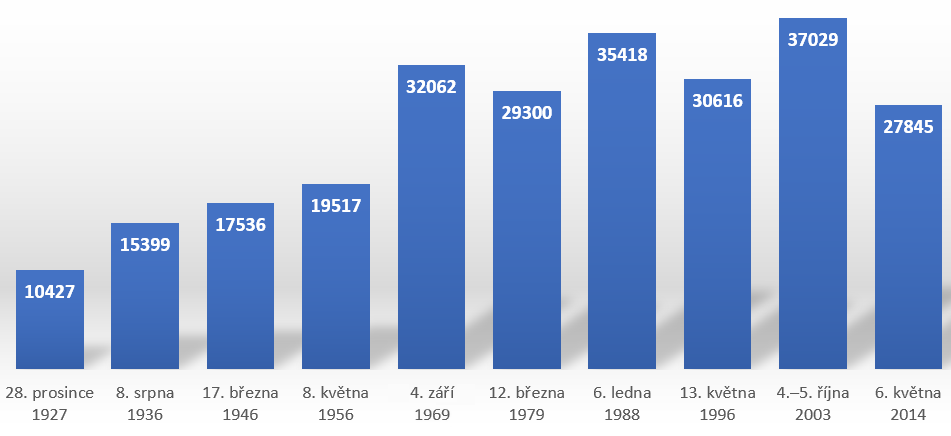
Figure 1 – OnomOs corpus structure (in tokens)
A specific feature of the corpus is the tagging of proper names, which could serve as a methodological basis for similar projects in the future. The annotation was done using the NameTag 2 software (Straková - Straka - Hajič, 2019; Ševčíková - Žabokrtský - Krůza, 2007; see here: https://ufal.mff.cuni.cz/nametag/2). However, the classification used by NameTag 2 was modified to be in line with the linguistic or onomastic conception of proper names (see Šrámek, 1999 and the relevant entries in the New Encyclopedic Dictionary of Czech Online: Karlík - Nekula - Pleskalová, 2017) and with current onomastic terminology. Its basis are higher level categories, represented by anthroponyms (personal names; A), toponyms (place names/names; T) and chrématonyms (names of human products and creations; C). Each of these categories is subdivided into lower order categories (e.g. AF - family names, TT - names of territories, CF - names of companies and societies).The two-letter coding of the lower-order categories is based on their English names or similar terms (e.g. currencies are designated as CM after “money”); the letters “X” and “Y” are reserved for underspecified groups (e.g. CX). Outside the classification are terms with numerals (n), including numbers in addresses (a), and some other categories that are not considered proper nouns in the Czech tradition (e-mail addresses [me], Internet references [mi], units of measurement [oe], academic titles [pd], and most temporal terms, e.g. names of months [tm]). The transformations of NameTag 2 categories into new, onomastic classes are comprehensively presented in Table 1.
| Higher level category (NameTag 2) | Lower level category (NameTag 2) | Lower level category (OnomOs) | Higher level category (OnomOs) |
|---|---|---|---|
| p - Personal names | pf - first names | AF: first names | Antroponyma (A) |
| pm - second names | |||
| pc - inhabitant names | AI: inhabitants | ||
| pp - relig./myth persons | AM: religious and mythological names | ||
| ps - surnames | AS: surnames | ||
| p_ - underspecified | AX: underspecified anthroponyms | ||
| g - Geographical names | gl - nature areas / objects | TN: nature names | Toponyma (T) |
| gh - hydronyms | |||
| gq - urban parts | TS: settlements | ||
| gu - cities/towns | |||
| gr - territorial names | TT: territories | ||
| gt - continents | |||
| gc - states | |||
| gs - streets, squares | TU: urbanonyms | ||
| g_ - underspecified | TX: underspecified toponyms | ||
| i - Institutions | ia - conferences/contests | CC: conferences, contests and events | Chrématonyma (C) |
| if - companies, concerns… | CF: companies | ||
| ic - cult./educ./scient. inst. | CI: cultural and educational institutions | ||
| io - government/political inst. | CP: politics | ||
| i_ - underspecified | CX: underspecified institutions | ||
| m - Media names | mn - periodical | CN: periodicals | |
| ms - radio and TX stations | CT: radios and TVs | ||
| o - Artifact names | oa - cultural artifacts (books, movies) | CA: art products | |
| or - directives, norms | CD: directives and norms | ||
| om - currency units | CM: currencies | ||
| op - products | CR: products | ||
| o_ - underspecified | CY: underspecified artifacts | ||
| t - Time expressions | tf - feasts | CH: feasts |
Table 1 - modification of the sorting of proper names in NameTag 2 for the purposes of the OnomOs corpus
The OnomOs corpus was created by researchers of the “Ostrava Onomastic School”, which focuses on the implementation of quantitative linguistic methods in the science of proper names within the research of the Department of Czech Language of the Faculty of Arts of the University of Ostrava. The project was supported by the grant project SGS02/FF/2023 OnomOs - Ostrava Corpus of Proper Names, which was implemented at the Faculty of Arts, University of Ostrava.




