

Obsah
6. lekce: Kolokace a frazémy
V minulých lekcích jsme se zaměřovali na vyhodnocování dotazů, jejich ukládání a v posledních dvou lekcích jsme si osvojili pokročilejší dotazování pomocí regulárních výrazů a CQL. Všechny tyto dovednosti zúročíme v této lekci, kde se soustředíme na smysluplné ustálené souvýskyty slov – kolokace.
Ve vymezení pojmu kolokace nepanuje obecná shoda, a to i přesto, že se jedná o jeden z hlavních předmětů zájmu korpusové lingvistiky. Názory se různí především v tom, co všechno mezi kolokace patří. Je tedy výhodné rozlišovat mezi kolokacemi v užším smyslu, někdy označovanými jako běžné kolokace, kam patří slovní spojení jako čokoládový dort, zavrtět hlavou nebo od rána do večera, a mezi kolokacemi v širším smyslu, které zahrnují následující typy:
- běžné kolokace (letní šaty, vejce naměkko)
- frazémy a idiomy (ležet ladem, růžové brýle)
- víceslovné termíny (infarkt myokardu, červí díra)
- víceslovná vlastní jména (Andělská Hora, Kostelec nad Černými Lesy)
Kolokace jako smysluplná ustálená slovní spojení se vymezují v opozici k volným syntagmatickým spojením, jako jsou růžové šaty, ležet odpoledne, nové brýle, pozorovat vrabce apod.
Vyhledávání kolokací
Existuje mnoho způsobů, jak kolokace v korpusech vyhledávat. V tomto kurzu se zaměříme na tři z nich:
- pomocí specializovaných dotazů CQL
- pomocí filtrů a frekvenční distribuce
- pomocí asociačních měr a funkce Kolokace v menu rozhraní KonText
Funkce meet a union
Dotazovací jazyk CQL, jemuž byla věnována předchozí lekce, obsahuje dva příkazy, které lze efektivně využít k hledání konkrétních kolokací – meet a union. Jedná se tedy o případ, kdy chceme vyhledat všechny výskyty určité kolokace, nikoli o způsob, jak zjistit, jaké kolokace se pojí k určitému klíčovému slovu.
Funkce meet umožňuje vyhledat dvě slova (KWIC a jeho kolokát) v určité vzdálenosti (bez ohledu na jejich pořadí). Syntax tohoto příkazu je následující: (meet KWIC KOLOKÁT OD DO)
Např. dotaz (meet [lemma="prát"][lemma="prádlo"] -3 3) vyhledá lemma prát a v jeho okolí – až tři pozice vlevo a až tři pozice vpravo – lemma prádlo. V SYN2020 najdeme takových výskytů přesně 141 (což je mimochodem úplně stejný počet jako v předchozím SYN2015).
Každý dotaz typu meet lze zapsat – poněkud komplikovanějším způsobem – i jako běžný CQL dotaz. Výše uvedený příklad je ekvivalentní s dotazem ([lemma="prát"][]{0,2}[lemma="prádlo"])|([lemma="prádlo"][]{0,2}[lemma="prát"]). Ačkoli oba dotazy identifikují stejnou množinu konkordancí, budou se lišit tím, co je jejich KWIC; v případě dotazu s pomocí příkazu meet to bude pouze první slovo, v případě CQL dotazu to bude celá sekvence od prvního slova k jeho kolokátu včetně všech slov, která se nacházejí mezi nimi.
Funkce union pomáhá slučovat dotazy typů meet. Její syntax je takováto: (union (meet…) (meet…)).
Dotaz (union (meet [lemma="prát"][lemma="prádlo"] -3 3) (meet [lemma="mýt"][lemma="nádobí"] -3 3)) vyhodnotí nejprve oba dotazy s příkazem meet a ty pak sloučí do jedné konkordance. Ve výsledku jsou v ní tak obsažené ty výskyty lemmatu prát, které mají v kontextu lemma prádlo, a ty výskyty lemmatu mýt, v jejichž okolí najdeme lemma nádobí. KWICem v konkordanci jsou pouze lemmata prát a mýt. Celkový počet výskytů pro tento dotaz v korpusu SYN2020 je 321.
Pomocí těchto dotazů lze zjišťovat nejen frekvenci kolokací, ale také míru jejich variability, pokud nějakou připouštějí (např. rozvíjející přívlastky a jiná vložená slova, slovosledné transformace apod.).
Filtrování konkordance
Kolokace lze identifikovat také pomocí frekvenční distribuce a filtrů. Filtry jsme dosud nepoužívali, proto nejprve několik slov obecně k nim.
Každý dotaz – poté, co ho vyhodnotíme a získáme konkordanci – lze dodatečně filtrovat. K dispozici máme dva typy filtrů: p (pozitivní) a n (negativní). V obou případech jsme při filtrování vyzváni k tomu, abychom zadali dodatečnou podmínku (ve stejné formě, jako zadáváme dotaz); při p-filtru jsou ponechány v konkordanci pouze ty doklady, které této podmínce vyhovují, v případě n-filtru jsou naopak ty doklady, které jí vyhovují, z konkordance smazány.
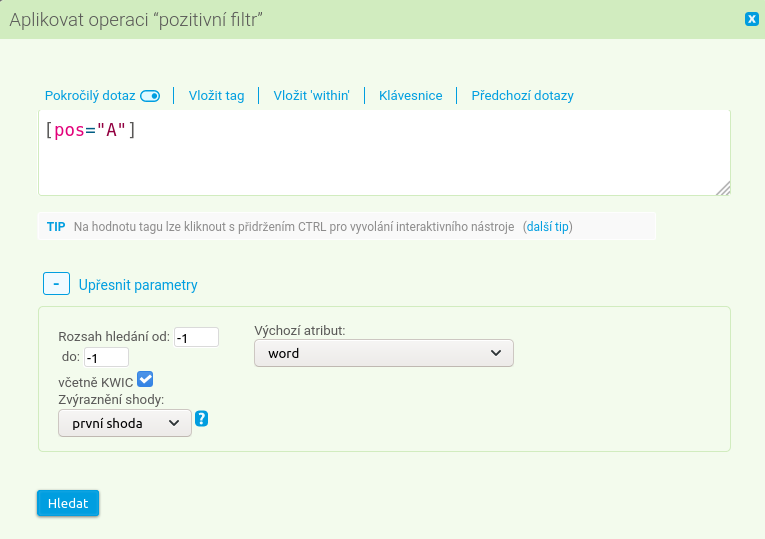
Oba typy filtrů najdeme v menu Filtr → Pozitivní či Filtr → Negativní. Jejich využití pro hledání kolokací si můžeme ukázat na příkladu lemmatu kolega, které má v SYN2020 celkem 13 375 výskytů. Pokud nás zajímají adjektivní přívlastky, které tomuto lemmatu předcházejí, můžeme použít pozitivní filtr, jímž konkordanci zúžíme pouze na ty případy, které našemu záměru vyhovují. Do zadání pozitivního filtru (přes horní menu) vyplníme tyto údaje:
Typ dotazu: přepnout přepínač Pokročílý dotaz
Dotaz: [pos="A"] (hledá všechna adjektiva na dané pozici, viz atribut pos)
Rozsah hledání (v Upřesnit parametry): od -1 do -1 (jde nám pouze o bezprostředně předcházející pozici)
Zbylé možnosti necháme, jak jsou.
Výsledkem je konkordance, která obsahuje 3174 výskytů lemmatu kolega, kterému předchází adjektivum. Ačkoli není zaručeno, že se bude jednat o shodný přívlastek, ve většině případů tomu tak je (můžeme si to ověřit na vzorku).
Konečné vyhodnocení provedeme pomocí frekvenční distribuce Frekvence → Vlastní – zkoumat budeme první předcházející pozici (1L), a to na základě lemmatu. Ve výsledku bychom měli objevit následující slova:
| Lemma | Frekvence |
|---|---|
| bývalý | 213 |
| mladý | 191 |
| starý | 137 |
| další | 118 |
| týmový | 97 |
| stranický | 96 |
| nový | 92 |
| ostatní | 73 |
| německý | 64 |
| slovenský | 62 |
Tento seznam může sloužit jako výchozí bod pro úvahy o tom, co je, či není (ustálená) kolokace s komponentem kolega.
Asociační míry
Kolokace až donedávna, bez velkých jazykových dat dostupných v korpusech, nebylo možné identifikovat jinak než introspekcí. K identifikaci kolokací se dnes v praxi používají statistické asociační míry, které ve většině případů dávají do vztahu frekvenci jednotek vstupujících do kolokace, frekvenci celého spojení a případně také velikost korpusu. Mezi nejběžnější patří MI-score, t-score, log-likelihood a logDice. Každá asociační míra je citlivá na jiný druh kolokací, žádnou proto není možné označit za univerzálně platnou, jež by bezchybně identifikovala všechny kolokace v textech. Každé automatické vyhledání kolokací za pomocí kolokačních měr vyžaduje následnou lingvistickou interpretaci, není tedy možné výsledky automatické kolokační analýzy považovat za definitivní seznamy kolokací, ale spíše za seznamy kandidátů na kolokace.
Pro výpočet asociačních měr je důležité tzv. okno, z něhož se vychází (tj. počet pozic napravo a nalevo od KWICu, které jsou považovány za potenciální kolokáty). Pro většinu výzkumů doporučujeme okno v rozmezí pozic -3 až +3 od KWICu. Podle povahy výzkumné otázky je možné – a mnohdy i žádoucí – toto nastavení změnit, např. pokud vyhledáváme pouze přívlastky určitého substantiva (jako v případě uvedeném výše), vhodné okno bude mít rozmezí -1 až -1 (tedy pouze první pozice vlevo od daného substantiva).

Příklad: Rozdíly v kolokátech podle měr
Na konkrétním případu si ukažme, jak rozdílné výsledky jednotlivé asociační míry poskytují.
Hledáme v korpusu SYN2015
- Vyhledáme lemma krev
- V menu zvolíme možnost Kolokace
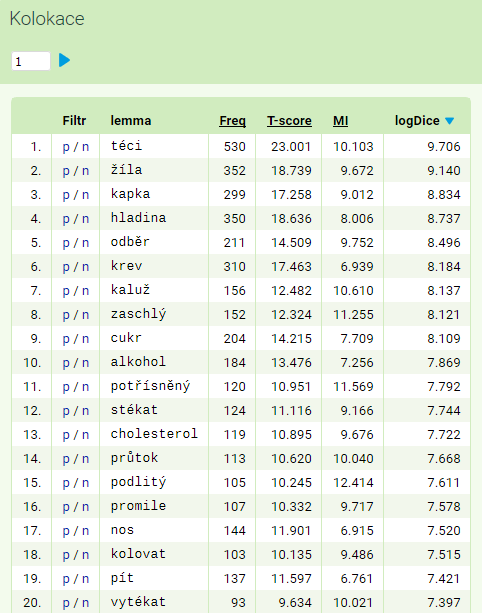
- Zkontrolujeme výchozí nastavení (především výběr používaných asociačních měr), změníme však atribut ze slovního tvaru na lemma
Jaké nabídnou různé asociační míry nejtěsnější kolokáty? Seznam lze v rozhraní KonText přerovnávat kliknutím na podtržené názvy jednotlivých měr (hlavička tabulky).
| míra / kolokáty | logDice | T-score | MI-score | Frekvence |
|---|---|---|---|---|
| 1. kolokát | téci | . | odkysličený | . |
| 2. kolokát | žíla | , | srážlivý | , |
| 3. kolokát | kapka | a | podlitý | a |
| 4. kolokát | hladina | v | prolitý | v |
| 5. kolokát | odběr | být | pupečníkový | být |
| 6. kolokát | krev | se | tratoliště | se |
Zjednodušeně lze výsledky interpretovat takto:
- Na frekvenci souvýskytu je založena míra T-score (3. sloupec), což je vidět i na její shodě s kolokacemi určenými podle pouhé frekvence (5. sloupec). Tato míra preferuje hodně častá slova (jak vidno, patří mezi ně interpunkční znaménka a gramatické výrazy), a co do lexikální sémantiky proto na těchto nejvyšších pozicích příliš vypovídající nebývá. Smysluplné kolokace je tedy nutno hledat níže v seznamu, je-li tento setříděn podle T-score nebo frekvence.
- Naopak MI-score (4. sloupec) upřednostňuje slova s nízkou frekvencí, což může vést k jinému typu zkreslení: pokud se některé výrazy v korpusu vyskytují opravdu řídce, může to být způsobeno i náhodou (danou zařazením konkrétního textu), že zrovna daný výraz míra identifikovala jako kolokaci. Na druhou stranu však bývá vhodná pro identifikaci kolokací typu tratoliště krve, kde jedním z členů kolokace je málo frekventované slovo.
- Jakýmsi kompromisem je míra logDice (2. sloupec), která více zohledňuje jak frekvenci, tak nenáhodnost souvýskytu obou výrazů. Vidět to je na již zmíněné specifické kolokaci tratoliště krve, kterou logDice neupozaďuje tolik jako T-score, ale uvádí ji na 92. místě (oproti 205. místu u T-score) – takto nízké umístění zajímavé kolokace může lehce ujít badatelově pozornosti. Výsledky této kompromisní míry je proto výhodné doplnit výsledky měr ostatních, především MI-score.
Změna nastavení hodnot
Nebudeme-li hledat kolokáty jako lemmata, ale jako konkrétní tvary (bez ohledu na velikost písmen, tedy s využitím atributu lc), může to mít na výsledek často zásadní vliv. Jak je vidět v tabulce, u logDice se v tomto případě pouze vyměnilo pořadí, T-score zůstalo stejné, ovšem z MI-score bylo tratoliště vytlačeno tvarem prolitou.
| míra / kolokáty | logDice | T-score | MI-score |
|---|---|---|---|
| 1. kolokát | žilách | . | nesrážlivé |
| 2. kolokát | tekla | , | podlitých |
| 3. kolokát | teče | a | podlitý |
| 4. kolokát | cukru | v | odkysličená |
| 5. kolokát | hladinu | se | zbrocených |
| 6. kolokát | krev | z | prolitou |
Využití kolokačních profilů
Takzvané kolokační profily či paradigmata, tedy seznam kolokátů daného slova, lze vytvářet právě na základě seznamů vygenerovaných pomocí různých asociačních měr. Díky kolokačním profilům lze například rozlišit různé významy polysémních slov.
Podívejme se na příklad lexému pravice: může jít o pravou ruku, ale i o politické uskupení. Jak v tomto rozlišení využít kolokace? Hledáme lemma pravice v korpusu SYN2015; kolokace vytváříme s nastavením rozsahu tři pozice okolo KWIC (od -3 do +3). Tabulka uvádí seznam 20 prominentních kolokátů lemmatu pravice podle asociační míry logDice.
| Lemma | Frekvence | T-score | MI | logDice | Interpretace |
|---|---|---|---|---|---|
| levice | 190 | 13.783 | 13.282 | 10.995 | politické uskupení (?) |
| krajní | 87 | 9.325 | 12.068 | 9.828 | politické uskupení |
| potřást | 46 | 6.779 | 11.084 | 8.878 | ruka |
| extrémní | 42 | 6.475 | 10.206 | 8.344 | politické uskupení |
| hegemon | 10 | 3.162 | 12.915 | 7.529 | politické uskupení |
| zdvižený | 11 | 3.315 | 10.638 | 7.371 | ruka (?) |
| volič | 28 | 5.280 | 8.888 | 7.275 | politické uskupení |
| volit | 36 | 5.986 | 8.730 | 7.246 | politické uskupení |
| potřásat | 8 | 2.827 | 11.082 | 7.074 | ruka |
| stoupenec | 11 | 3.312 | 9.564 | 7.047 | politické uskupení |
| napřažený | 7 | 2.644 | 10.895 | 6.882 | ruka |
| napřáhnout | 7 | 2.643 | 9.879 | 6.694 | ruka |
| stisknout | 16 | 3.987 | 8.295 | 6.617 | ruka |
| konzervativní | 10 | 3.153 | 8.466 | 6.464 | politické uskupení |
| bašta | 6 | 2.446 | 9.617 | 6.462 | politické uskupení |
| lídr | 14 | 3.727 | 8.033 | 6.377 | politické uskupení |
| náboženský | 15 | 3.855 | 7.762 | 6.209 | politické uskupení |
| ODS | 24 | 4.872 | 7.485 | 6.121 | politické uskupení |
| radikální | 8 | 2.817 | 8.009 | 6.066 | politické uskupení |
| třímat | 4 | 1.998 | 9.681 | 6.012 | ruka |
V tabulce je naznačeno, jakým způsobem můžeme seznam kolokátů rozkategorizovat při prvním pohledu. Analýza výsledků poskytnutých kolokačními seznamy se však nikdy neobejde bez manuální kontroly. U nejednoho kolokátu z automaticky vytvořeného seznamu je třeba nahlížet do konkrétních kontextů, a to kliknutím na modré p na začátku řádku seznamu, označující pozitivní filtr. Snadno se ukáže, že např. kolokace pravice + levice může odkazovat k politickému uskupení, a to kupodivu nejen v publicistice (Nezajímalo nás, jestli patří k pravici nebo levici, jestli je křesťan nebo ateista…), ale stejně tak najdeme hodně dokladů doslovného užití (Bezvýhradně důvěřujete člověku po levici i po pravici, protože na nich závisí váš život…).
Frazémy
Vedle běžných kolokací odhalují asociační míry ještě další typ ustáleného souvýskytu, a sice frazémy. Pro jednoduchost si vezměme často zkoumané somatické frazémy, např. ty obsahující slovo srdce. Co se dozvíme z kolokační analýzy? Z hlediska frazeologie se jeví nejužitečnější třídit výsledky podle MI-score, přínosné též bývá zachování konkrétních tvarů: vyjeví se tak kupříkladu rozdíl v četnosti pozitivních a negativních tvarů (ne/přirůst k srdci) i možná preference týkající se kategorie času – typickým příkladem realizace tohoto frazému budiž věta To mi k srdci nepřirostlo.
Vyzkoušejte si na závěr
- Nejprve si procvičíme filtrování, tentokrát pomocí negativního filtru. O slově tratoliště se běžně tvrdí, že je tzv. monokolokabilní, tedy spojitelné jen s velmi omezeným počtem lexémů. Prověřte na korpusových datech, zda je tomu skutečně tak – hledejte pravostranné kolokáty tohoto lemmatu v korpusech SYN2010, SYN2015 a SYN2020 a také v korpusu ORAL v1 a odfiltrujte výskyty slovního spojení tratoliště krve. Podívejte se, v jakých typech textů se zbylé případy objevují.
- Adverbia nyní a teď jsou chápána jako synonymní. Pak by ale měla vstupovat do kolokací s víceméně stejnými lexémy, že? Porovnejte kolokační profily obou slov v SYN2015: rozsah nastavte od -3 do 3, atribut na lc (zajímají nás slovní tvary nehledě na velikost písmen) a orientujte se primárně podle asociační míry logDice a pokuste se na jejich základě interpretovat případné rozdíly.
Řešení najdete jako obvykle na speciální stránce.
V našem kurzu jsme téměř na konci, schází nám poslední lekce, která se bude soustředit na vytváření subkorpusů a zadávání podmínek. Pokud vás zajímá výzkum jazyka určitého typu (ať už autorského, dobového či konkrétního žánru), bude to lekce přímo pro vás.




