

Korpus vyučovacích hodin SCHOLA2010
Korpus SCHOLA20101) je sociologicky i didakticky jedinečný korpus, protože vychází ze školního prostředí a zaznamenává mluvený jazyk vyučovacích hodin (především standardních vyučovacích hodin s délkou cca 45 min.). Uživatelům se tak nabízí jazykový materiál, v němž je zachycena mluva učitelů i žáků během vyučování. Zatím je to jediný veřejně přístupný korpus tohoto typu. Uvedený korpus se od ostatních mluvených korpusů zveřejněných v Českém národním korpusu liší také tím, že neobsahuje jen mluvu dospělých, ale i dětí a mládeže. Jde o referenční sociolingvisticky nevyvážený korpus poloformální a formální mluvené češtiny o velikosti zhruba 1 milion pozic.
Tento korpus je sice určený především lingvistům a pedagogům, ale protože je pojímán interdisciplinárně, může poskytnout užitečné informace také speciálním pedagogům, psychologům, sociologům a dalším uživatelům. Potřebám výzkumu rovněž slouží databanka Akces na ÚČJTK UK FF 2), kde jsou zpřístupněny přepisy ve finální verzi (v přepisech zveřejněných v korpusu SCHOLA2010 byly kvůli prohlížeči provedeny drobné úpravy, viz Zásady pro přepis vyučovacích hodin).
| Název | SCHOLA2010 |
|---|---|
| Počet pozic (tokenů) | 1 046 600 |
| Počet pozic (tokenů) bez interpunkce a dalších značek | 828 038 nebo 792 764 3) |
| Počet slovních tvarů (wordů) | 64 329 |
| Počet nahrávek rozhovorů | 204 |
| Počet promluv | 61 285 |
| Počet mluvčích | 2410 |
| Délka nahrávek v min. | 8605 |
Složení korpusu SCHOLA2010 a získávání dat
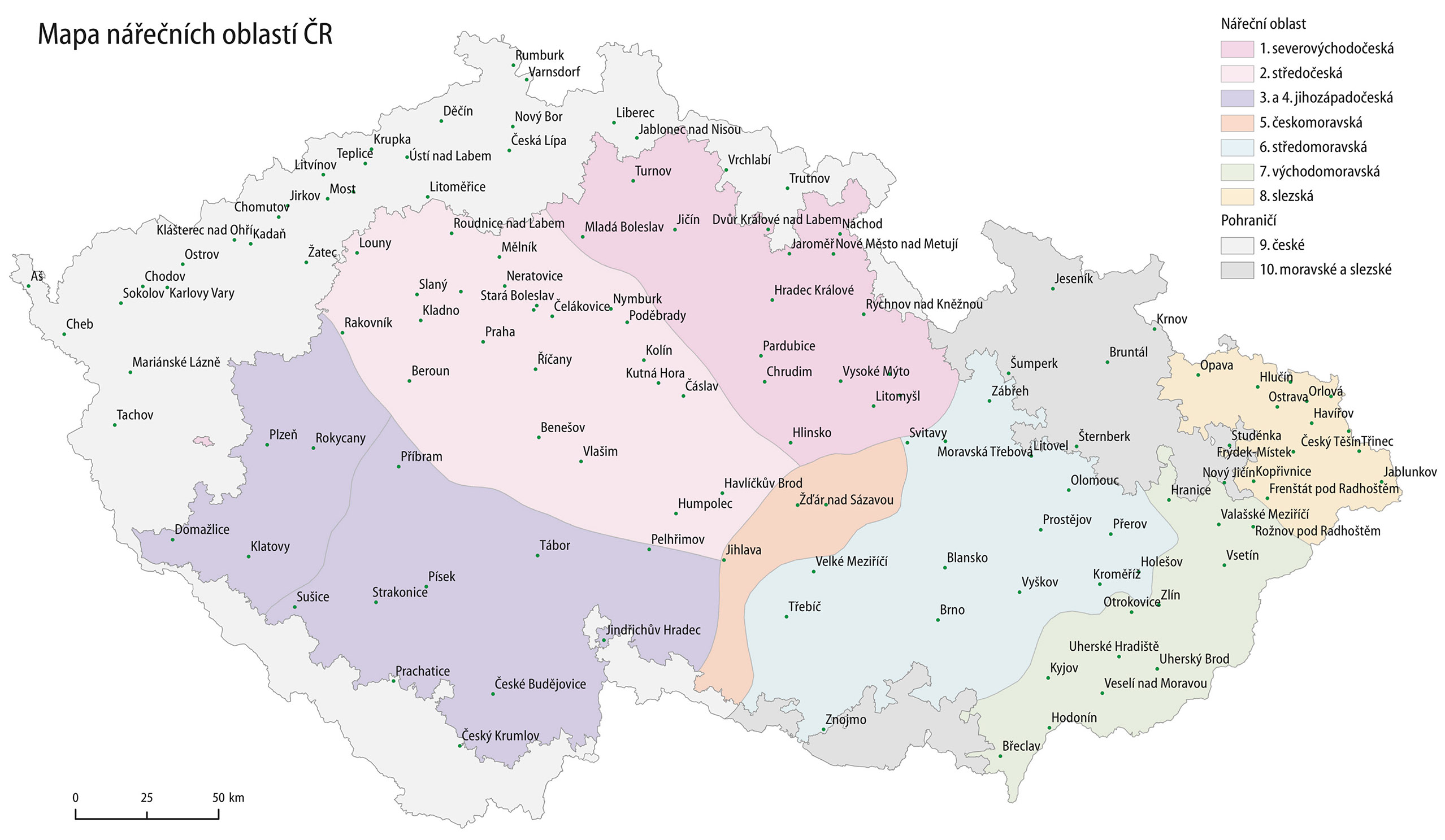
Korpus SCHOLA2010 tvoří 204 přepisů nahrávek vyučovacích hodin pořízených v letech 2005–2008 na různých místech České republiky, viz oddíl Statistiky ke korpusu Schola2010. 131 nahrávek bylo nahráno ve středočeské nářeční oblasti, 57 nahrávek ve východomoravské nářeční oblasti 4), viz Mapa nářečních oblastí ČR, jde tedy i o teritoriálně různorodý jazykový materiál. Přestože nahrávání probíhalo víceméně ve formálním prostředí, v korpusu SCHOLA2010 se vyskytují i rysy běžně mluveného jazyka. V přepisech vyučovacích hodin je vedle spisovné češtiny poměrně často přítomna obecná čeština a objevují se i regionální prvky. V projevech zaznamenaných ve východní části České republiky je zřejmý vliv dialektu (jsou zde i některé archaické nářeční prvky, např. infinitiv s ť – zkúšať aj.).
Učitelé i žáci o nahrávání dopředu věděli, žáci (případně jejich rodiče) souhlasili s nahráváním i s využitím těchto nahrávek pro potřeby Českého národního korpusu a pro výzkumné účely. V korpusu vyučovacích hodin se vyskytuje 2410 jedinečných mluvčích (osob). Celková délka zaznamenaného zvukového materiálu činí 143 h 25 min. Korpus obsahuje 1 046 600 pozic, z toho je 792 764 slov (bez interpunkce a bez komentářů, které jsou v různých závorkách).
Výběr škol a vyučovacích předmětů
Pro budování korpusu SCHOLA2010 byly vybrány základní školy, gymnázia a střední odborné školy. Projektu se účastnilo celkem 27 škol (16 pražských a 11 mimopražských) a 115 tříd/skupin. Pokud jde o pedagogy, na nahrávání se podílelo 47 učitelů (20 mužů a 27 žen). V projevech bylo rozpoznáno 2347 jedinečných žáků (jsou v tom zahrnuti i 4 cizí žáci) a 16 cizích dospělých osob (převážně učitelů). U žáků byl zaznamenán věk od 6 do 23 let, věk učitelů se pohybuje od 23 let do 53 let, u cizích dospělých osob do 69 let, podrobněji viz oddíl Statistiky ke korpusu Schola2010.
V korpusu jsou zastoupeny všechny třídy ZŠ kromě 4. třídy (nahrávání se zde nepodařilo zajistit), všechny třídy víceletých gymnázií a všechny ročníky čtyřletých gymnázií a středních odborných škol. Podle rámcových vzdělávacích plánů (RVP) do něj byly zařazeny všechny základní vyučovací předměty (kromě cizích jazyků a tělocviku) a výběrově i odborné předměty vyučované na středních odborných školách, viz Sociolingvistické značky a charakteristiky v korpusu SCHOLA2010. Korpus SCHOLA2010 je vyvážený především vzhledem ke skupinám vyučovacích předmětů k počtu sond:
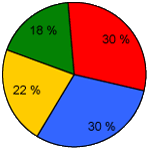
| 1. skupina | ||
|---|---|---|
| skupina A | český jazyk a literatura | 60 sond |
| skupina B | matematické a přírodovědné předměty | 62 sond |
| 2. skupina | ||
| skupina C | společenskovědní a výchovné předměty | 45 sond |
| skupina D | informatika, technické a profesně–pracovního vyučování | 37 sond |
podrobněji viz oddíl Statistiky ke korpusu Schola2010.
Statistiky ke korpusu Schola2010
Korpus SCHOLA2010 se s ostatními mluvenými korpusy shoduje v základních sociolingvistických proměnných. Kvůli srovnatelnosti s ostatními korpusy uvádíme situaci při nahrávání:
| Kategorie | zkratky |
|---|---|
| Situace při nahrávání | F (formální) |
| Pohlaví | M (muž) a Z (žena) |
| Věk | I (do 35 let) a V (35 let a více) |
| Vzdělání | B (základní a středoškolské) a A (vysokoškolské včetně pouze započatého) |
U všech mluvčích jsou taktéž zpřístupněny informace o jejich přesném věku a konkrétním dosahovaném stupni vzdělání (ZŠ, SŠ, VŠ). Korpus SCHOLA2010 navíc díky svému speciálnímu zaměření obsahuje další užitečné sociolingvistické charakteristiky: informace o sondě, o škole, o třídě, o vyučovacím předmětu, o vyučovací hodině, doplňující údaje o mluvčím, podrobněji viz Sociolingvistické značky a charakteristiky v korpusu SCHOLA2010.
Zásady pro přepis vyučovacích hodin
Zpracování nahrávek vyučovacích hodin a jejich přepisování vycházelo ze zásad uplatňovaných při přípravě předchozích mluvených korpusů v rámci Českého národního korpusu, zejména korpusu ORAL2006. Pravidla pro přepis vyučovacích hodin však byla upravena v závislosti na charakteru a koncepci tohoto projektu, viz Zásady pro přepis vyučovacích hodin.
Odkazy:
Mapa nářečních oblastí ČR

Poděkování
Korpus SCHOLA2010 by nemohl vzniknout bez výrazné pomoci učitelů a jejich cenné účasti v tomto projektu. Na přepisech vyučovacích hodin, na úpravách a jiných specifických úkolech se podíleli studenti z FF a z PedF Univerzity Karlovy v Praze a další spolupracovníci z ÚČJTK FF UK a z Ústavu českého národního korpusu (ÚČNK). Celému pracovnímu týmu tímto děkujeme.
Jak citovat
Šebesta, K. – Goláňová, H. – Křen, M. – Procházka, P.: SCHOLA2010: korpus mluvené češtiny ve škole – přepisy nahrávek vyučovacích hodin na českých základních a středních školách. Ústav Českého národního korpusu FF UK, Praha 2010. Dostupný z WWW: http://www.korpus.cz
— Karel Šebesta, Hana Goláňová, Olga Richterová





{kind=link}