

Český mluvený korpus ORAL2006
Mluvený korpus ORAL2006 je v pořadí třetím mluveným korpusem, který je dostupný v rámci projektu Český národní korpus. Zachycuje mluvenou češtinu z celé oblasti českých nářečí v užším slova smyslu (tj. pouze z Čech, ne z Moravy a Slezska). Jedná se o přepis více než dvou set nahrávek z let 2002–2006. Všechny nahrávky vznikaly výhradně v neformálních situacích, což znamená, že se mluvčí vzájemně znali a měli k sobě přátelský vztah. Celkem bylo nahráno 6 693 minut, tj. asi 111 a půl hodiny rozhovorů, a v jejich rámci bylo zaznamenáno 1 000 798 slov. Navázal na něj korpus ORAL2008.
| Název | ORAL2006 |
|---|---|
| Počet pozic (tokenů) | 1 312 282 |
| Počet pozic (tokenů) bez interpunkce a dalších značek | 1 000 798 |
| Počet slovních tvarů (wordů) | 64 495 |
| Počet nahrávek rozhovorů | 221 |
| Počet promluv | 97 112 |
| Počet mluvčích | 754 |
ORAL2006 a PMK a BMK - v čem se shodují
Způsob pořizování nahrávek, jejich přepis a označování probíhalo v souladu s pravidly a zásadami předchozích mluvených korpusů, jimiž byl Pražský mluvený korpus –- PMK (z jeho pravidel se vycházelo především) a Brněnský mluvený korpus –- BMK. Z tohoto důvodu bylo zachováno označování sociolingvistických kategorií mluvčích:
| Kategorie | zkratky |
|---|---|
| Pohlaví | M (muž) a Z (žena) |
| Věk | I (iunior, mladší, do 35 let) a V (vetus, starší, 35 let a více) |
| Vzdělání | B (basis, základní a středoškolské) a A (altus, vysokoškolské včetně pouze započatého) |
ORAL2006 a PMK a BMK - v čem se liší
U všech mluvčích jsou (stejně jako v korpusu ORAL2008) navíc zpřístupněny i informace o:
- jejich přesném věku
- konkrétním dosaženém stupni vzdělání (ZŠ, SŠ, VŠ)
- oblasti jejich převažujícího pobytu do 15 let
Oblast převažujícího pobytu do 15 let
Věk 15 let je stanoven jako hranice, kdy se formoval základ individuálního jazykového úzu. Tyto oblasti jsou vymezeny na základě tradičního nářečního členění podle Jaromíra Běliče (Nástin české dialektologie, SPN, Praha 1972). Území Čech je tedy rozděleno na oblast středočeskou, severovýchodočeskou, jihozápadočeskou, přechodnou oblast česko-moravskou a české pohraničí. U každého přepisu je zaznamenán počet mluvčích účastnících se hovoru, rok pořízení nahrávky a neformálnost situace. Poslední označení se zachovává kvůli srovnatelnosti s ostatními korpusy i přesto, že korpus ORAL2006 obsahuje pouze nahrávky neformálních situací.
Složení korpusu ORAL2006

Absolutní počty mluvčích podle místa narození i s údaji o zeměpisné šířce a délce jsou k dispozici ke stažení ve formátu .csv.
Tab 1. Počet nahrávek podle roků
| Rok | Počet nahrávek |
|---|---|
| 2002 | 18 |
| 2003 | 17 |
| 2004 | 36 |
| 2005 | 72 |
| 2006 | 78 |
Tab 2. Počet nahrávek podle počtu mluvčích
| Počet mluvčích | Počet nahrávek |
|---|---|
| 2 | 66 |
| 3 | 71 |
| 4 | 45 |
| 5 | 15 |
| 6 | 14 |
| 7 | 5 |
| 8 | 3 |
| 9 | 1 |
| 10 | 1 |
Tab 3. Počet mluvčích a pozic podle vzdělání
| Vzdělání | Počet mluvčích | Počet pozic |
|---|---|---|
| A | 496 | 781089 |
| B | 258 | 531193 |
| ZŠ | 48 | 89102 |
| SŠ | 210 | 442091 |
| VŠ | 496 | 781089 |
Tab 4. Počet mluvčích a pozic podle pohlaví
| Pohlaví | Počet mluvčích | Počet pozic |
|---|---|---|
| ženy | 452 | 910536 |
| muži | 302 | 401746 |
Tab 5. Počet mluvčích a pozic podle věku
| Věk | Počet mluvčích | Počet pozic |
|---|---|---|
| I | 431 | 755474 |
| V | 323 | 556808 |
Tab 6. Počet mluvčích a pozic podle nářečních oblastí
| Nářeční oblast | Počet mluvčích | Počet pozic |
|---|---|---|
| středočeská | 452 | 573802 |
| severovýchodočeská | 139 | 447500 |
| jihozápadočeská | 73 | 143239 |
| česko-moravská | 3 | 12031 |
| české pohraničí | 87 | 135710 |
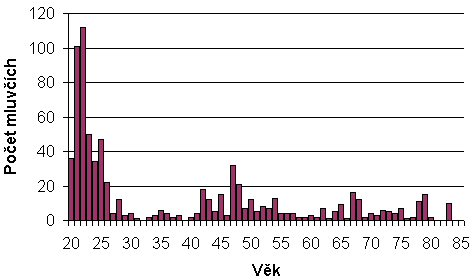
Počet mluvčích podle věku:
Struktura korpusu ORAL2006
Mezi strukturní jednotky používané v tomto korpusu patří <doc> a <sp>, tedy dokument a mluvčí (speaker), a pak každá jednotlivá pozice.

K těmto strukturním jednotkám náležejí následující atributy, na obrázku patrné pod nadpisem Reference.
Zachycování a zobrazování metainformací
Všechny nahrávky pocházejí z neformálních situací, přesto, jak již bylo řečeno výše, se zachovává označení neformálnosti jako v předchozích korpusech (PMK a BMK) – je vyjádřeno posledním písmenem v označení sondy, N. První dvojčíslí v názvu sondy označuje rok pořízení nahrávky, další kombinace písmene a čísel je vlastním číslem sondy. Ovšem ID (identifikační číslo) sondy nám toho zas mnoho neřekne, zato po dvojkliku na něj se zobrazí podrobné sociolingvistické informace o mluvčím a další údaje o sondě. Chcete-li mít tyto informace zobrazené automaticky, upravte si Možnosti nastavení.
Jak citovat ORAL2006
Kopřivová, M. – Waclawičová, M.: ORAL2006: korpus neformální mluvené češtiny. Ústav Českého národního korpusu FF UK, Praha 2006. Dostupný z WWW: http://www.korpus.cz
Poděkování
Na pořizování nahrávek, jejich přepisu a dalších úpravách se podíleli především studenti pražských vysokých škol a další spolupracovníci ÚČNK.
— Martina Waclawičová, Marie Kopřivová, Olga Richterová




