

Korpus Diakorp
Korpus Diakorp reprezentuje diachronní složku ČNK. Zahrnuje texty celkem ze sedmi století vývoje češtiny a je koncipován tak, aby postupně umožnil zkoumání jazykového úzu v jeho historických proměnách. Jedná se o korpus referenční, průběžně rostoucí ve verzích. První verze (přibližně 700 000 slovních tvarů) byla zpřístupněna veřejnosti v září roku 2005 a je nadále průběžně rozšiřována (textová základna korpusu narůstá tempem přibližně 250 000 slovních tvarů ročně). V současné době obsahuje Diakorp ve verzi 6 přes 3,4 mil. slov.
| Název | DIAKORP | |
|---|---|---|
| Pozice | Počet pozic (tokenů) | 4 128 874 |
| Počet pozic (tokenů) bez interpunkce | 3 450 142 | |
| Počet slovních tvarů (wordů) | 282 799 | |
| Struktury | Počet dokumentů | 116 |
| Další informace | Referenční | ANO |
| Reprezentativní | NE | |
| Aktuální verze | 6 | |
| Rok zveřejnění | 2015 | |
Diakorp vzhledem ke svému časovému záběru necílí na to, aby byl korpusem reprezentativním a vyváženým. V rámci diachronních projektů ČNK se profiluje především jako jedna z fází zpracovávání a zveřejňování textů:
- Diakon - pracovní korpus přístupný přes webovou aplikaci SyD, největší rozsah, obsahuje i dosud nezkorigované texty;
- Diakorp - korpus menšího rozsahu než Diakon, obsahuje ručně zkorigované texty přístupné v rozhraní KonText;
- Dia - připravovaný korpus zaměřený na pokrývání jednotlivých století (počínaje 19. st.) širokým spektrem textových typů, bude obsahovat ručně zkorigované a lemmatizované texty.
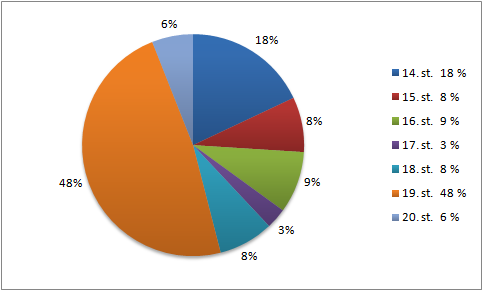
Složení Diakorpu verze 6 (zveřejněna 2015) v % pozic na časové období
Změny oproti starší verzi
Vedle přírůstku dat (z 1,95 mil. na 3,4 mil. slovních tvarů) přibyla i klasifikace textů podle textových typů. Dále byl sjednocen formát datace a zavedeny toleranční intervaly (v případě nejasného roku vzniku byl slovní popis nahrazen číselnou hodnotou, např. „1390±10“ místo „konec 14. století“).
Změnil se charakter značek vnášených do textů editory tak, aby nebyly započítávány do celkového počtu pozic. Nový způsob, jak tyto značky použít při zadávání dotazu, popisují Specifika vyhledávání v diachronním korpusu.
Soubory s kompletním výčtem textů obsažených v Diakorpu a jejich délkou ve slovech jsou k dispozici v příslušné sekci seznamů.
Způsob zpracování textů
Do diachronního korpusu vstupují texty původně zapsané či vytištěné různými pravopisnými systémy (pozůstatky tzv. jednoduchého pravopisu, spřežkovým a diakritickým pravopisem) a jejich kombinacemi. Takto heterogenní materiál si nevyhnutelně vynucuje poněkud jiné zpracování, než je obvyklé jak v edicích starších písemných památek (jejichž zásady jsou zpravidla výrazně přizpůsobeny specifickým jazykovým a pravopisným charakteristikám určitého období, popřípadě i charakteristikám jednoho autora nebo díla), tak v synchronních korpusech (jejichž zásady se orientují na současný jazykový stav a do značné míry se opírají o živé jazykové povědomí uživatelů korpusu).
Základním cílem zpracování textů pro diachronní korpus je zajistit – přes zmíněnou různorodost - jednotné, co nejsnazší a nejvšestrannější prohledávání textů z celého sedmisetletého historického vývoje češtiny a současně zachovat co nejvíce relevantních lingvistických informací, které jsou v těchto textech obsaženy. K realizaci těchto dvou cílů jsou v diachronním korpusu aplikovány následující dva principy:
- Texty jsou transkribovány, nikoli transliterovány. Tato zásada umožňuje vyhledávat v diachronním korpusu výskyty konkrétních tvarů a podob jednotlivých slov stejným způsobem jako v korpusu synchronním.
- Texty jsou značkovány. Vedle různých informací o jednotlivých textech a jejich strukturaci umožňuje tato zásada zachovat i podstatnou část lingvistických informací, k jejichž ztrátě obvykle dochází při transkripci.
V budoucnu se možnosti prohledávání diachronního korpusu výrazně rozšíří lemmatizací využívající tzv. hyperlemmat, která uživateli korpusu umožní vyhledat všechny výskyty konkrétního lexému bez ohledu na různost jeho dobových aj. podob a tvarů (například: při vyhledávání pomocí hyperlemmatu kůň bude možno najít i starší české podoby kóň a kuoň).
Transkripce
Starší české texty jsou v diachronním korpusu transkribovány v zásadě podle běžných zvyklostí,1) avšak s některými omezeními (zejména užívání zvláštních znamének a znaků, např. znaků pro staročeské měkké retnice); tato omezení vyplývají ze současných možností elektronického kódování textů, s nímž pracuje korpusový manažer.
Typografické vlastnosti textu
Každý text je přepsán jedním typem a jedním řezem písma (tučné písmo, kurzíva či proložení znaků nejsou zachovány). Zvláštnosti uspořádání textu na stránce a hranice svébytných úseků textu (nadpisů, poznámek pod čarou apod.) signalizují speciální kódy (viz níže).
Pravopis
Starší pravopisný systém je při transkripci nahrazen systémem dnešním:
To wʃʃe ʃe ʃtalo ne gegj, ale cyzý winau. > To vše se stalo ne její, ale cizí vinou.
Pokud je grafická podoba slova neočekávaná nebo nejednoznačná, je normalizována a původní zápis slova je uložen tak, aby jej bylo možno zobrazit spolu s daným slovem (viz níže). Tímto způsobem je nahrazen tradiční výčet zásahů editora uváděný v ediční poznámce. Obvyklost určitého zápisu je ověřována ve slovnících.2)
- Interpunkci originálu nahrazujeme členěním podle dnešních pravidel (ponechána je v případě, že dnešním pravidlům neodporuje nebo nemění smysl textového úseku).
- Zkratky jsou řešeny různě, obvyklé staročeské typy vzniklé kontrakcí nebo nadepsáním písmena (gt, geu) jsou rozepsány bez poznámky (jest, jemu), formy zkrácené tečkou zůstávají obvykle nerozepsány.
- Hranice slov upravujeme podle dnešního stavu (týká se to zvláště příklonek -li, by či předložek psaných dohromady se jménem), výjimkou jsou příslovečné, spojkové a zájmenné spřežky, které ponecháváme ve znění originálu (zdali nebo zda-li, u vnitř nebo uvnitř, kdo koli nebo kdokoli, tak zvaný nebo takzvaný).
- Psaní velkých písmen přizpůsobujeme dnešním pravidlům pravopisu.
Fonologické aspekty
Obecnou zásadou je zachovávat bez úpravy ty jevy, které v daném kontextu s jistou pravděpodobností svědčí o dobové výslovnosti (jsou doloženy v jazykových příručkách).
Pokud je originální text zapsán/vytištěn tak, že neumožňuje jednoznačnou fonologickou interpretaci (např. proto, že v něm - tak jako ve velké části staročeských textů - není označována kvantita, popř. že text byl přejat z kritické edice), a jeho transkripce tedy zahrnuje i celkovou rekonstrukci některých jeho fonologických rysů vyplývající nikoli z textu samého, ale především z dnešního stupně poznání staršího stavu jazyka, je vedle pracovního identifikačního názvu díla (id), který se objeví po kliknutí na referenční údaj v pravé části konkordančního řádku, uvedena značka (R). Tato značka uživatele korpusu upozorňuje, že transkribovaná podoba příslušného textu je do značné míry rekonstruovaná („normalizovaná“), a není tedy po fonologické stránce autentická.
Pokud v rámci určitého textu a určitého slova kvantita samohlásek kolísá a přitom je délka i krátkost dobově obvyklá, nesjednocujeme podobu slova podle převažující varianty, ale ponecháváme obě podoby.
Morfologie
Při transkripci respektujeme původní morfologické rysy textu (např. v českém museum, se dvěma křídlama, mezi obyvately, cizá idea). Úpravu znění volíme pouze v případě, že jde o zjevný omyl, který by působil problémy při morfologické analýze textu (např. v krásném stavením > v krásném stavení / stavením).
Značkování
Primárním účelem značkování je:
- připojit ke korpusovému textu podstatné vnější metainformace (údaje o době vzniku textu, o jeho autorovi a názvu a o stránkování/foliaci); tyto údaje se objeví v dolním okně obrazovky, klikneme-li na referenční údaj konkordančního řádku;
- zachovat lingvisticky relevantní informace; původní grafická podoba slova se v případě provedení úpravy ukládá do pozičního atributu „e“ (emendace) daného slova, speciálně se zachycuje i (částečná) absence či doplnění textu;
- naznačit strukturu korpusového textu a označit jeho zvláštní součásti, aby byla minimalizována ztráta těchto údajů při transkripci. V diachronním korpusu jsou k tomuto cíli aplikovány značky (konkrétně strukturní atributy) uvedené v následující tabulce.
Kódy a zvláštní znaky obsažené v textu (zobrazí se po volbě příslušných značek v Zobrazení):
| Kód/Zkratka | Popis |
|---|---|
| <f> </f> | naznačují začátek a konec formátovaného textu, tj. graficky členěného textu, tabulky, grafické poezie, textu jako součásti vyobrazení ap.; nejazykové prvky takového textu (grafické symboly, obrázky ap.) se přitom bez poznámky vypouštějí. |
| <k> </k> | naznačují začátek a konec titulku, podtitulku, mezititulku, záhlaví, textu doplňující titul, název ap. Například: <k>Kapitola 5</k>; <k>U hrobu rekova. Z polštiny přeložil Alois Bydžovský. (Dokončení)</k> |
| <n> </n> | naznačují začátek a konec poznámky (pod čarou aj.). Text poznámky se přitom v korpusovém textu vkládá přímo na místo, odkud se na poznámku odkazuje. |
| <o> </o> | naznačují citátové (gramaticky nezačleněné) cizí prvky, pasáže v cizím jazyce ap. Není-li mezi kódy přepsán skutečný cizojazyčný text (např. proto, že je psán abecedou, s níž korpusový manažer nepracuje), uvádí se mezi kódy alespoň jazyk nepřepsaného textu, a to v závorkách, tedy např. <o>(řečtina)</o>. |
| <v> </v> | naznačují začátek a konec veršovaného textu. |
| <x> </x> | naznačují části textu, které byly dodatečně přeškrtnuty (je-li pravděpodobné, že jde o škrt autorův, popř. písařův). |
| <m> </m> | naznačují začátek a konec marginálie; text marginálie se přitom umisťuje před začátek odstavce nebo věty (tj. na místo v textu, kam podle smyslu patří); např.: Příklady toho některé vizme. <m>Příklad na Adamovi v ráji</m> První člověk Adam rady u sebe nevěda, začal ji krom sebe hledati… |
Informace uložená v pozičním atributu „e“ (emendace)
Atribut „e“ informuje o grafické podobě slova (obvykle slova zapsaného nebo vytištěného způsobem, který je v dané době nestandardní, zjevně chybný, nejednoznačný, nezřetelný nebo nečitelný). Původní zápis se uvádí v transliterované podobě (bez speciálních znaků, jako je tzv. dlouhé s), tj. např. ušima / vssijma. Další případy:
| Kód/Zkratka | Popis |
|---|---|
| e | informuje o zjevných tiskových nebo písařských chybách (např. duha / dnha), |
- o dobově neobvyklém nebo rozkolísaném způsobu psaní, u nějž se kloníme k názoru, že neobráží variantní výslovnost (tj. jinou výslovnost, než odpovídá dobově obvyklému způsobu zápisu), např. set / seth, maso / masso, Kristus / Krystus ap., |
|
- o případech, v nichž grafický záznam sice může odrážet více či méně odlišnou výslovnost než standardní zápis, avšak příslušný tisk či písemný záznam je jako celek natolik nedokonalý nebo nedůsledný, že je sporné, zda nestandardní grafika odlišnou výslovnost skutečně odráží; například: nějaký / negaký, jináč / ginač, |
|
- o nejednoznačném písemném záznamu, který by mohl být interpretován/transkribován více než jedním způsobem; například: ústa / vsta (zápis je možno číst i jako usta), město / miesto (zápis by v daném kontextu bylo možno číst i jako miesto) ap., |
|
- o částečně nezřetelném, poškozeném ap. textu, který však bylo při transkripci možno na základě kontextu doplnit (původní záznam je uveden v pozičním atributu „e“), přičemž nezřetelná, nečitelná nebo chybějící místa jsou označena pomocí [...]; například: námi / ná[…], uslyšán / vsl[…]ssan), |
|
- o užívání římských číslic (čísla zapsaná římskými číslicemi jsou v korpusu přepsána číslicemi arabskými, např. 123 / cxxiii; do léta 1560ho / M.D.L.Xo.). |
Značky mající povahu textových pozic
Na rozdíl od všech výše uvedených atributů, které nejsou součástí vlastního textu díla a nevstupují do výpočtů, je naznačení chybějícího či doplněného textu stejnou textovou pozicí jako slovní tvary či interpunkce.
| Kód/Zkratka | Popis |
|---|---|
| [ ] | naznačují, že znak (značka, symbol ap.), který nemá ekvivalent ve znakové sadě Windows, s níž pracuje korpusový manažer, byl přepsán dnešním ekvivalentem (značkou, zkratkou ap.) nebo rozepsán slovy, aby byl zachován smysl věty (např. náhrada astrologického znaku pro Slunce v zápisu Myslí, že jemu samému [Slunce] svítí.). |
| [...] | naznačuje vynechaný, porušený nebo nečitelný text, např. A protož múdrý lékař najprv [...]. |
Anotace textových typů
V Diakorpu verze 6 byla zavedena dvouúrovňová klasifikace textů. Označení úrovní je stejné jako v korpusech řady SYN (1. txtype_group, textová skupina; 2. txtype, textový typ), avšak vymezení jednotlivých skupin a typů (tj. hodnoty strukturních atributů txtype_group a txtype) se liší.
Klasifikace textů v korpusu Diakorp verze 6
V závorkách jsou uvedeny typy textů, které zatím buď nejsou v korpusu zastoupeny, nebo nejsou určeny (X).
| txtype_group | txtype |
|---|---|
| próza | povídka, román, cestopis… |
| verše | písně duchovní… |
| drama | tragédie, komedie ve verších… |
| odborná teoretická | chemie, historie… |
| odborná praktická | zvěrolékařství, zemědělství… |
| periodikum | časopis, noviny |
| názory | X (propagace, agitace, polemika apod.) |
| reflexe | X (esej, rozjímání apod.) |
| řeč | modlitby, bohoslužba… (slavnostní řeč apod.) |
| každodenní | deník… (dopis, paměti apod.) |
| mix | X |
Cílem klasifikace je pomoci uživateli zorientovat se v datech. Voleny proto byly takové textové třídy, které jsou pokud možno obecně srozumitelné, a to i za cenu jisté nesystematičnosti v třídění. Na úrovni textové skupiny i textového typu jsou využita různá kritéria (literární druhy, registry, témata…), aby při daném rozsahu korpusu nenarůstala složitost metadat. Třídění je založeno na textech, které jsou obsaženy v současné verzi korpusu. Konflikty, které se v budoucnu očekávají, budou řešeny pragmaticky (např. odborný časopis bude zařazen do skupiny „odborná teoretická“ nebo „odborná praktická“, neboť je to z hlediska předpokládaného lingvistického výzkumu podstatnější než periodicita vydávání; analogicky nyní spadá „časopis pro zábavu a poučení“ pod skupinu „periodikum“, a nikoli „mix“, protože označení formy má větší výpovědní hodnotu atd.).
Textová skupina (txtype_group) představuje vyšší úroveň obecnosti, jednotlivé kategorie byly navrženy tak, aby do nich bylo možné zařadit většinu textů, které budou do korpusu přibývat. Vycházejí ze základního rozdělení veřejných psaných textů na beletrii, odbornou (oborovou) literaturu a publicistiku, nové kategorie byly přidány pro přechodové a speciální typy textů.
- Beletrii odpovídají kategorie drama, verše a próza. Nejméně typickým představitelem je vzhledem k žánrovému synkretismu ve starší české literatuře próza: do této kategorie byly zařazeny např. i kroniky, staré historie a životopisy (svatých, papežů), a to pod souhrnným označením (
txtype) vyprávění historické. - Odborná (oborová) literatura byla rozdělena na skupinu odborná teoretická a odborná praktická. Prototypem prakticky orientovaných textů je návod, mezním případem jsou učebnice a výchovné spisy. Základním distinktivním rysem oproti teoretickým textům je přítomnost apelativní funkce (Bühler), příjemce má podle těchto textů řídit své chování.
- Publicistice v synchronních korpusech odpovídá kategorie periodikum.
Pomezní a speciální kategorie:
- Názory - texty na pomezí odborné literatury a publicistiky ve stylistickém smyslu (vymezené persvazivní funkcí).3) Na rozdíl od odborných textů jsou skutečnosti otevřeně hodnoceny z jednoho stanoviska.
- Reflexe - přechodový typ mezi odbornou teoretickou literaturou a názory. Úvahy vedené ze subjektivního hlediska, ale nikoli s primárním cílem někoho přesvědčovat; filosofické texty, které ještě nelze zařadit k určité odborné disciplíně.
- Řeč - kategorie předem připravených (vzorových) nebo následně zapsaných proslovů („written to be spoken“). Specifické je zařazení modliteb - důvodem je jednak hlasová (vnější i vnitřní) realizace, jednak formální různorodost těchto textů.
- Každodenní - texty se základní dorozumívací funkcí. Často se vztahují k plynutí času, proto je kategorie určena jak pro soukromé dopisy a běžné poznámky, tak pro pravidelné chronologické záznamy (v letopisech apod.), které nemusejí mít nutně soukromý charakter.
Textový typ (txtype) slouží k podrobnějšímu třídění textů v rámci textové skupiny. Při určování typu byl sledován dvojí cíl: podat informaci o textu (např. list pastýřský) a zároveň pomocí stejných nebo podobných názvů typů vytvářet další podskupiny textů (povídka - povídky (tj. cyklus, soubor) - povídka didaktická). Názvy byly v případě beletristických děl přebírány z literárněvědných příruček 4) nebo vytvářeny z tradičních termínů. Vodítkem ke stanovení typu byly dále údaje v katalogu Národní knihovny nebo metainformace obsažené v samotných dílech (v podtitulech apod.).
Poznámky k některým typům:
- Vyprávění historické - sdružuje kroniky a blízký žánr historie, životopisy, pověsti apod. (název vznikl analogií k označení „historický román“).
- Historie - v rámci teoreticky odborné literatury není rozlišen předmět historického popisu (právo, dějiny Moravy apod.), většinou je naznačen již titulem.
- X - není blíže určen.
Jak citovat DIAKORP
Kučera, K. – Stluka, M.: DIAKORP: Diachronní korpus, verze 5 z 21. 2. 2011. Ústav Českého národního korpusu FF UK, Praha 2011. Dostupný z WWW: http://www.korpus.cz
Kučera, K. – Řehořková, A. – Stluka, M.: DIAKORP: Diachronní korpus, verze 6 z 18. 12. 2015. Ústav Českého národního korpusu FF UK, Praha 2015. Dostupný z WWW: http://www.korpus.cz
Kučera, K. (2014): Diachronní složka Českého národního korpusu a hranice možností korpusového výzkumu vývoje češtiny. Naše řeč 97 (4–5), 208–215. http://nase-rec.ujc.cas.cz/archiv.php?art=8339
— Karel Kučera, Martin Stluka, Anna Řehořková (Zitová)




