

Jak citovat korpusy zpřístupňované ČNK
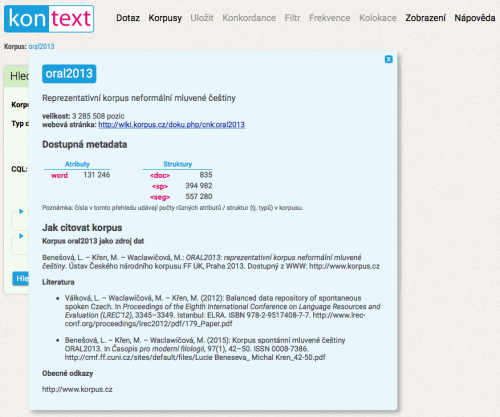
Způsoby citování korpusů
Existují v zásadě dva způsoby, jakým korpusy při vědecké práci citovat:
- uvedení korpusu jako pramene či zdroje dat;
- uvedení odkazu na konkrétní článek, který popisuje vznik korpusu a jeho složení.
Volba mezi těmito dvěma možnostmi je na zvážení uživatele a záleží také na konkrétním účelu citace; samozřejmě je možné oba způsoby kombinovat. Konkrétní podobu citace najdete jednak v této wiki na stránce věnované konkrétnímu korpusu a jednak v rozhraní KonText po kliknutí na odkaz s názvem korpusu.
Citace ad 1) je uvedena vždy, citace ad 2) pouze v KonTextu a jen pro většinu korpusů; chybí tedy v případě, kdy se žádný článek s popisem korpusu nepodařilo dohledat. Kromě konkrétního bibliografického údaje však můžete u některých korpusů v KonTextu najít přímo webový odkaz na adresu, z níž je možné článek stáhnout.
Citování nereferenčních korpusů
Při citování verzovaných korpusů je potřeba uvádět také číslo verze, které je v rozhraní KonText u každého verzovaného korpusu vždy k dispozici jako součást citační informace.
Při citaci konkrétního díla lze použít také seznam zdrojů korpusu SYN2000, SYN2005 nebo SYN2010.
Lemmatizace a tagování
- Používáte-li lemmatizaci, morfologické nebo slovesné značky (atributy lemma, tag nebo verbtag v korpusech řady SYN), citujte jednu z následujících publikací:
Tomáš Jelínek, Jan Křivan, Vladimír Petkevič, Hana Skoumalová, Jana Šindlerová (2021): SYN2020: A new corpus of Czech with an innovated annotation. In: K. Ekštein – F. Pártl – M. Konopík (eds.), Text, Speech, and Dialogue. TSD 2021. Lecture Notes in Computer Science, vol. 12848. Cham: Springer, pp. 48–59.
Křivan, J. – Šindlerová, J. (2022): Změny v morfologické anotaci korpusů řady SYN: nové možnosti zkoumání české gramatiky a lexikonu. Slovo a slovesnost, 83, 2/2022, s. 122–145.
- Můžete také uvést některý z následujících článků, které se použité anotace týkají:
Jan Hajič (2004): Disambiguation of Rich Inflection (Computational Morphology of Czech). Vol. 1. Karolinum Charles University Press, Praha.
Milena Hnátková, Michal Křen, Pavel Procházka, Hana Skoumalová (2014): The SYN-series corpora of written Czech. In: Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14). ELRA, Reykjavík, s. 160–164. http://www.lrec-conf.org/proceedings/lrec2014/pdf/294_Paper.pdf
Vladimír Petkevič (2014): Problémy automatické morfologické disambiguace češtiny. Naše řeč 97 (4), s. 194–207.
Milan Straka, Jana Straková, Jan Hajič (2019): Czech Text Processing with Contextual Embeddings: POS Tagging, Lemmatization, Parsing and NER. In: Proceedings of the 22nd International Conference on Text, Speech and Dialogue - TSD 2019, Lecture Notes in Computer Science, ISSN 0302-9743, 11697, pp. 137-150.
- V případě lemmatizace a značkování mluveného korpusu ORAL můžete citovat také následující publikaci:
Marie Kopřivová, Zuzana Komrsková, David Lukeš, Petra Poukarová (2017): Korpus ORAL: sestavení, lemmatizace a morfologické značkování. Korpus – gramatika – axiologie 15, s. 47–67.
Citování aplikací
Tomáš Machálek (2019): Slovo v kostce – agregátor slovních profilů. FF UK, Praha. Dostupný z WWW: <http://korpus.cz/slovo-v-kostce/>.
Tomáš Machálek (2019): Word at a Glance – a Customizable Word Profile Aggregator. In: Proceedings of the CLARIN Annual Conference 2019, s. 85–88.
Tomáš Machálek (2014): KonText – aplikace pro práci s jazykovými korpusy. FF UK, Praha. Dostupný z WWW: <http://kontext.korpus.cz>.
Tomáš Machálek (2020): KonText: Advanced and Flexible Corpus Query Interface. In: Proceedings of LREC 2020, s. 7005–7010.
Václav Cvrček – Pavel Vondřička (2011): SyD – korpusový průzkum variant. FF UK, Praha. Dostupný z WWW: <http://syd.korpus.cz>.
Václav Cvrček – Pavel Vondřička (2011): Výzkum variability v korpusech češtiny. In: František Čermák (ed.): Korpusová lingvistika Praha 2011. 2. Výzkum a výstavba korpusů. NLN, Praha, s. 184–195.
Václav Cvrček – Pavel Vondřička (2013): Morfio – aplikace pro analýzu slovotvorných vztahů. FF UK, Praha. Dostupný z WWW: <http://morfio.korpus.cz>.
Václav Cvrček – Pavel Vondřička (2013): Nástroj pro slovotvornou analýzu jazykového korpusu. Gramatika a korpus 2012. Gaudeamus, Hradec Králové.
Václav Cvrček – Pavel Vondřička (2013): KWords – aplikace pro extrakci klíčových slov. FF UK, Praha. Dostupný z WWW: <http://kwords.korpus.cz>.
Martin Vavřín – Alexandr Rosen (2015): Treq – databáze překladových ekvivalentů. FF UK, Praha. Dostupný z WWW: <http://treq.korpus.cz>.
Michal Škrabal – Martin Vavřín (2017): Databáze překladových ekvivalentů Treq. Časopis pro moderní filologii 99 (2), s. 245–260.
Michal Škrabal – Martin Vavřín (2017): The Translation Equivalents Database (Treq) as a Lexicographer’s Aid. In: I. Kosem et al. (eds): Electronic lexicography in the 21st century. Proceedings of eLex 2017 conference. Lexical Computing CZ, s. r. o., Leiden, s. 124–137.




